Eine häufige Frage, die ich von vielen Leuten sehe, die neu in T-SQL sind, ist, wie man Daten in einer Zeichenkette findet und sie extrahiert. Dies ist eine sehr häufige Anfrage, da unsere Datenbanken viele Zeichenketten enthalten. Wir stellen oft fest, dass Leute, die Anwendungen verwenden, Informationen in eine Zeichenkette einbetten, mit der Erwartung, dass das Programm diese Informationen später leicht entfernen kann. In diesem Artikel zeige ich Ihnen, wie Sie diese Daten mit SUBSTRING, CHARINDEX und PATINDEX extrahieren können.
Dies ist ein Artikel über die Grundlagen, der hoffentlich für Entwickler und DBAs nützlich ist, die neu in SQL Server sind und ihre Kenntnisse verbessern möchten. Fühlen Sie sich frei, dies weiterzugeben.
Finden Sie die konsistente PO
Ein Beispiel ist eine Rechnungsnummer oder PO-Nummer. Ich habe diese Daten oft in Textfelder eingebettet gesehen, mit der Anforderung, diese Nummer später aus dem Feld zu extrahieren. Dies ist eine übliche Art von Daten, die irgendwo in ein Feld in einer Tabelle eingefügt wird, z. B. in einer Kundentabelle. Es kann sein, dass Benutzer oder eine Anwendung entscheiden, diese Daten hinzuzufügen, um unsere Daten zu denormalisieren.
Angenommen, wir haben eine Tabelle, die Informationen wie diese enthält:
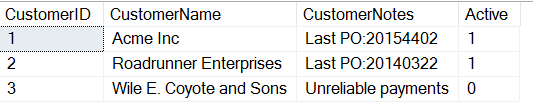
CREATE TABLE Customers( CustomerID INT, CustomerName VARCHAR(500), CustomerNotes VARCHAR(MAX), Active TINYINT);GOINSERT dbo.Customers ( CustomerID , CustomerName , CustomerNotes , Active ) VALUES ( 1, 'Acme Inc', 'Last PO:20154402', 1) , ( 2, 'Roadrunner Enterprises', 'Last PO:20140322', 1 ) , ( 3, 'Wile E. Coyote and Sons', 'Unreliable payments', 0)
Wenn ich mir die Daten ansehe, sehen wir, dass jemand entschieden hat, wichtige Informationen in das Feld „Notizen“ aufzunehmen. Ich bin mir sicher, dass viele erfahrene Leute bei dieser Verwendung von Feldern in einer Tabelle zusammenzucken werden, aber das passiert öfter, als vielen von uns lieb ist.
Wenn ich nun die PO aus diesem Feld herausholen möchte, vielleicht für einen Bericht, der benötigt wird, oder vielleicht, weil ich diese Daten an einen geeigneteren Ort ETLen werde, kann ich die SUBSTRING-Funktion in T-SQL verwenden. Ich verwende diese Funktion, wenn ich weiß, an welcher Stelle innerhalb einer Zeichenkette ich Daten abrufen möchte.
In diesem Fall kann ich sehen, dass die ersten 8 Zeichen des Feldes CustomerNotes oft „Last PO:“ sind. Damit kann ich beim 9. Zeichen beginnen und dann die nächsten 8 Zeichen (Länge der PO) abrufen. Ich verwende diese Abfrage.
SELECT CustomerID , 'PO' = SUBSTRING(CustomerNotes, 9, 8)FROM dbo.Customers
Dies gibt die POs zurück, aber ich erhalte einige andere Daten.
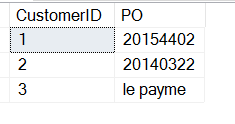
Keine Sorge, ich kann das leicht herausfiltern (eine Diskussion für einen anderen Artikel).
SELECT CustomerID , 'PO' = SUBSTRING(CustomerNotes, 9, 8)FROM dbo.Customers WHERE customerNotes LIKE '%PO%'
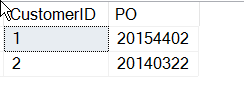
Jetzt bin ich fertig, oder? Nun, vielleicht nicht.
Eine inkonsistente Bestellung
In den Daten, die ich mir bisher angeschaut habe, ist die Bestellnummer immer an der richtigen Stelle. Aber nehmen wir einmal an, dass nicht alle unsere Datenerfasser mit den Kunden auf die gleiche Weise arbeiten. Hier ein paar weitere Daten, um zu zeigen, was ich meine:
INSERT dbo.Customers ( CustomerID , CustomerName , CustomerNotes , Active ) VALUES ( 4, 'Beep Beep Enterprises', 'Remember their slogan: We go fast. Last PO:20154402', 1) , ( 5, 'Goldberg Supplies', 'Preferred. Last PO:20140322', 1 ) , ( 6, 'Bugs Deliveries', 'Fast Last PO:20145554', 0)
Lassen Sie nun unser Skript von oben laufen. Wir erhalten diese Daten:
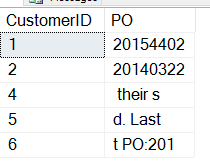
Nicht ganz das, was wir wollen. Das Problem hier ist, dass der Anfang des SUBSTRING nicht das ist, was wir wollen. Wir müssen mit der Position der Bestellnummer beginnen, vielleicht mit der Position von „PO:“. Wie können wir das bekommen?
Wir haben ein paar Möglichkeiten, aber geben Sie CHARINDEX und PATINDEX ein. Beide erlauben uns, eine Zeichenkette zu suchen und eine andere Zeichenkette darin zu finden. Beide können hier funktionieren, aber lassen Sie mich Ihnen zeigen, wie diese an unseren Testdaten funktionieren. Ich führe diese Abfrage aus:
SELECT CustomerID , CustomerNotes , 'Charindex_StartPO' = CHARINDEX('PO:', CustomerNotes) , 'Patindex_StartPO' = PATINDEX('%PO:%', CustomerNotes) , 'PO' = SUBSTRING(CustomerNotes, 9, 8) FROM dbo.Customers
Und erhalte diese Ergebnisse:
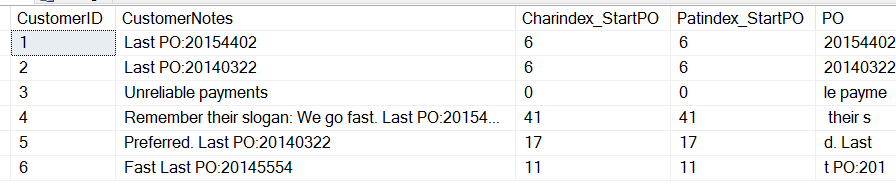
Beachten Sie, dass wir hier sehen können, dass beide Funktionen den gleichen Wert zurückgeben, die Anfangsposition des „P“ in „PO“. Es gibt ein paar Unterschiede. CHARINDEX kann an einer bestimmten Position in der Zeichenkette beginnen, während PATINDEX Wildcards annehmen kann. In diesem einfachen Fall können wir beides verwenden.
Ich verwende hier CHARINDEX und ändere meine Abfrage folgendermaßen ab:
SELECT CustomerID , 'PO' = SUBSTRING(CustomerNotes, CHARINDEX('PO:', CustomerNotes), 8) FROM dbo.Customers WHERE customerNotes LIKE '%PO%';
Das gibt mir das hier, was nicht das ist, was ich will.
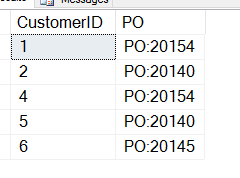
Ich habe vergessen, dass CHARINDEX mir die Anfangsposition der PO liefert, also muss ich zu diesem Wert addieren. Hier ist eine Abfrage, die funktioniert:
SELECT CustomerID , 'PO' = SUBSTRING(CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3, 8) FROM dbo.Customers WHERE customerNotes LIKE '%PO%';
Beachten Sie, dass ich zum Ergebnis der CHARINDEX-Funktion eine 3 addiert habe. Hier sind die Ergebnisse:
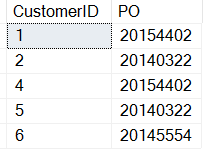
Die Bestellung wächst
Es scheint, dass dies eine gute Abfrage ist, aber stellen wir uns vor, wir fügen ein paar weitere Daten hinzu.
Beachten Sie, dass wir in diesem Fall Bestellungen haben, die größer geworden sind. Einige sind 8 Zeichen lang, andere sind 9. Sicherlich können wir nur 9 Zeichen nehmen, aber wir könnten auf 10 oder mehr wachsen. Außerdem haben wir stellenweise andere Notizen nach der Bestellung.
Lassen Sie uns unsere Abfrage modifizieren, um zu sehen, was wir tun können. Ich habe meinem CHARINDEX eine Wendung hinzugefügt.
SELECT CustomerID , CustomerNotes , 'Start of PO' = CHARINDEX('PO:', CustomerNotes)+3 , 'End of PO' = CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) , 'PO' = SUBSTRING(CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3, 8) FROM dbo.Customers WHERE customerNotes LIKE '%PO%';
Hier sind die Ergebnisse:
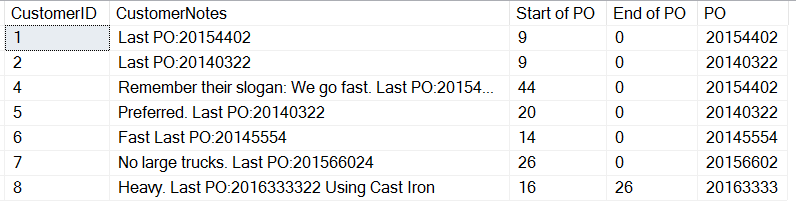
Wenn wir genau hinsehen, sehen wir, dass unser letzter Eintrag, mit Text nach dem PO, uns ein CHARINDEX-Ergebnis liefert. Das liegt daran, dass wir nach einer Zeichenkette suchen, wir erhalten eine 0, wenn kein Eintrag gefunden wird. Nur Kunde 8 hat ein Leerzeichen nach dem PO. Das heißt, wir können die Länge des PO für den letzten Eintrag berechnen, aber was ist mit all den anderen Einträgen, die ein anderes Format haben?
Wir können hier eine CASE-Anweisung verwenden, da wir hier zwei Möglichkeiten haben. Die eine CASE-Anweisung prüft auf ein Leerzeichen und gibt den Index des Leerzeichens innerhalb der Zeichenkette zurück. Die andere wird die Länge der Zeichenkette selbst zurückgeben, wenn kein Leerzeichen vorhanden ist. Das ergibt einen Code wie diesen:
Update: Meine Berechnung war falsch. Ich habe den Code unten von -3 auf -2 geändert.
SELECT CustomerID , CustomerNotes , 'Start of PO' = CHARINDEX('PO:', CustomerNotes)+3 , 'End of PO' = CASE WHEN CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) = 0 THEN LEN(CustomerNotes) ELSE CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) END , 'Real End of PO' = CASE WHEN CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) = 0 THEN LEN(customernotes) ELSE CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) END - CHARINDEX('PO:', CustomerNotes) , 'PO' = SUBSTRING(CustomerNotes , CHARINDEX('PO:', CustomerNotes)+3 , CASE WHEN CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) = 0 THEN LEN(customernotes) ELSE CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) END - CHARINDEX('PO:', CustomerNotes) - 2 ) FROM dbo.Customers WHERE customerNotes LIKE '%PO%';
Wenn wir uns diesen Code ansehen, ist er dem vorher verwendeten SUBSTRING-Code sehr ähnlich, aber statt einer festen Länge, 8, für die Anzahl der zurückzugebenden Zeichen, geben wir jetzt Werte mit einer Formel zurück. Die Formel ist im Wesentlichen das tatsächliche Ende des PO (die 5. Spalte in der Ergebnismenge) und der Anfang des PO. Es gibt eine CASE-Anweisung für den Fall, dass wir eine Null erhalten.
Wenn wir nun rechnen, können wir sehen, wie lang jeder PO ist. Für die meisten POs sind das 8 Zeichen (11 Zeichen nach dem Anfang des „P“ in „PO:“), aber 9 Zeichen für Kunde 7 und 11 für Kunde 8.
Einige von Ihnen werden sich vielleicht über die -3 im Code wundern, aber wenn Sie sich an die Regeln der Arithmetik erinnern, habe ich das Minus tatsächlich auf die Menge übertragen, die den Anfang der PO-Nummer darstellt.
Fazit
Das ist nicht das Ende der Möglichkeiten für POs, die in ein Notizfeld eingebettet sind. Ich könnte etwas haben wie „Test PO: 201530444. Neuer Test“ und das würde Probleme mit unserem Code verursachen. In der Tat gibt es viele andere Fälle, die ich in der realen Welt behandeln müsste.
Dieser Artikel entstand aus ein paar Problemen bei der Zeichenextraktion, die ich in der realen Welt lösen musste, und diese Arten von Problemen treten tatsächlich auf. Ich hoffe, ich konnte Ihnen einige Fähigkeiten vermitteln, die Ihnen bei der Manipulation von SQL Server-Zeichenfolgen helfen werden.
Wie bei allen Techniken, die Sie hier lernen, sollten Sie die Auswirkungen auf die Leistung abschätzen. Führen Sie Ihren Code gegen einen großen Satz von Testdaten aus und stellen Sie fest, wie gut diese Technik im Vergleich zu anderen Techniken funktionieren kann. Ich empfehle Ihnen, eine Tabelle zu verwenden, um Daten zu generieren, die größer sind als Ihre Produktionstabellen.
Zeichenfolgenmanipulationen können in SQL Server sehr rechenintensiv sein, daher sollten Sie sich über die Auswirkungen Ihrer Entscheidungen im Klaren sein, bevor Sie den Code in einem Produktionssystem einsetzen.