Die Geschwindigkeit von Websites ist eine Priorität für Unternehmen im Jahr 2020.
Schnellere Websites rangieren in den Suchmaschinen höher und bieten auch ein besseres Benutzererlebnis, was zu höheren Konversionsraten führt. Kein Wunder, dass Website-Besitzer schnellere Ladegeschwindigkeiten fordern – und es den Entwicklern überlassen, dies umzusetzen.
Die Datenbankoptimierung ist ein wesentlicher Schritt zur Verbesserung der Website-Performance. Normalerweise normalisieren Entwickler eine relationale Datenbank, das heißt, sie restrukturieren sie, um Datenredundanzen zu reduzieren und die Datenintegrität zu verbessern. Manchmal reicht es jedoch nicht aus, eine Datenbank zu normalisieren. Um die Datenbank-Performance weiter zu verbessern, gehen Entwickler den umgekehrten Weg und greifen auf die Datenbank-Denormalisierung zurück.
In diesem Artikel werfen wir einen genaueren Blick auf die Denormalisierung, um herauszufinden, wann diese Methode angebracht ist und wie Sie sie durchführen können.
Wann sollte man eine Datenbank denormalisieren
Was ist Datenbank-Denormalisierung? Bevor wir in das Thema eintauchen, wollen wir betonen, dass die Normalisierung immer noch der Ausgangspunkt ist, was bedeutet, dass Sie zunächst die Struktur einer Datenbank normalisieren sollten. Das Wesen der Normalisierung besteht darin, jedes Datenelement an die richtige Stelle zu setzen; dies gewährleistet die Datenintegrität und erleichtert die Aktualisierung. Allerdings kann das Abrufen von Daten aus einer normalisierten Datenbank langsamer sein, da Abfragen viele verschiedene Tabellen ansprechen müssen, in denen unterschiedliche Daten gespeichert sind. Aktualisierungen hingegen werden schneller, da alle Daten an einem einzigen Ort gespeichert werden.
Die meisten modernen Anwendungen müssen in der Lage sein, Daten in der kürzest möglichen Zeit abzurufen. Und das ist der Zeitpunkt, an dem Sie die Denormalisierung einer relationalen Datenbank in Betracht ziehen können. Wie der Name schon sagt, ist die Denormalisierung das Gegenteil der Normalisierung. Wenn Sie eine Datenbank normalisieren, organisieren Sie die Daten, um Integrität zu gewährleisten und Redundanzen zu beseitigen. Datenbank-Denormalisierung bedeutet, dass Sie absichtlich dieselben Daten an mehreren Stellen platzieren und so die Redundanz erhöhen.
„Warum überhaupt eine Datenbank denormalisieren?“, werden Sie sich vielleicht fragen. Der Hauptzweck der Denormalisierung besteht darin, das Auffinden von Daten deutlich zu beschleunigen. Allerdings ist die Denormalisierung keine Wunderpille. Entwickler sollten dieses Werkzeug nur für bestimmte Zwecke verwenden:
# 1 Um die Abfrageleistung zu verbessern
Typischerweise müssen bei einer normalisierten Datenbank viele Tabellen gejoint werden, um Abfragen zu erhalten; aber je mehr Joins, desto langsamer die Abfrage. Als Gegenmaßnahme können Sie einer Datenbank Redundanz hinzufügen, indem Sie Werte zwischen übergeordneten und untergeordneten Tabellen kopieren und so die Anzahl der für eine Abfrage erforderlichen Joins reduzieren.
#2 Um eine Datenbank bequemer zu verwalten
Eine normalisierte Datenbank hat keine berechneten Werte, die für Anwendungen wichtig sind. Das Berechnen dieser Werte on-the-fly würde Zeit kosten und die Ausführung von Abfragen verlangsamen.
Sie können eine Datenbank denormalisieren, um berechnete Werte bereitzustellen. Sobald diese generiert und zu den Tabellen hinzugefügt wurden, können nachgelagerte Programmierer leicht ihre eigenen Berichte und Abfragen erstellen, ohne tiefgreifende Kenntnisse des Codes oder der API der App zu haben.
#3 Um das Reporting zu erleichtern und zu beschleunigen
Oft müssen Anwendungen eine Menge analytischer und statistischer Informationen bereitstellen. Die Erstellung von Berichten aus Live-Daten ist zeitaufwändig und kann sich negativ auf die Gesamtleistung des Systems auswirken.
Die Denormalisierung Ihrer Datenbank kann Ihnen helfen, diese Herausforderung zu meistern. Angenommen, Sie müssen eine Gesamtverkaufsübersicht für einen oder viele Benutzer erstellen; eine normalisierte Datenbank würde alle Rechnungsdetails mehrfach aggregieren und berechnen. Um diesen Prozess zu beschleunigen, können Sie die Zusammenfassung der Verkäufe seit Jahresbeginn in einer Tabelle mit Benutzerdetails speichern.
Techniken der Datenbank-Denormalisierung
Nun, da Sie wissen, wann Sie eine Datenbank-Denormalisierung durchführen sollten, fragen Sie sich wahrscheinlich, wie Sie es richtig machen. Es gibt mehrere Denormalisierungstechniken, die jeweils für eine bestimmte Situation geeignet sind. Lassen Sie uns diese im Detail untersuchen:
Speichern von ableitbaren Daten
Wenn Sie eine Berechnung bei Abfragen wiederholt ausführen müssen, ist es am besten, die Ergebnisse zu speichern. Wenn die Berechnung Detailsätze enthält, sollten Sie die abgeleitete Berechnung in der Stammtabelle speichern. Wann immer Sie sich für die Speicherung von abgeleiteten Werten entscheiden, stellen Sie sicher, dass denormalisierte Werte immer vom System neu berechnet werden.
Hier sind Situationen, in denen das Speichern von ableitbaren Werten sinnvoll ist:
- Wenn Sie häufig ableitbare Werte benötigen
- Wenn Sie die Quellwerte nicht häufig ändern
| Vorteile | Nachteile |
|---|---|
| Nicht müssen nicht jedes Mal die Quellwerte nachschlagen, wenn ein ableitbarer Wert benötigt wird | Das Ausführen von Data Manipulation Language (DML)-Anweisungen gegen die Quelldaten erfordert eine Neuberechnung der ableitbaren Daten |
| Es muss nicht für jede Abfrage oder jeden Bericht eine Berechnung durchgeführt werden | Dateninkonsistenzen sind möglich aufgrund von Datenduplikationen |
Beispiel

Als Beispiel für diese Denormalisierungstechnik, nehmen wir an, wir bauen einen E-Mail-Nachrichtendienst. Nachdem ein Benutzer eine Nachricht erhalten hat, bekommt er nur einen Zeiger auf diese Nachricht; der Zeiger wird in der Tabelle User_messages gespeichert. Dies geschieht, um zu verhindern, dass das Nachrichtensystem mehrere Kopien einer E-Mail-Nachricht speichert, falls diese an viele verschiedene Empfänger gleichzeitig gesendet wird. Was aber, wenn ein Benutzer eine Nachricht aus seinem Konto löscht? In diesem Fall wird nur der entsprechende Eintrag in der Tabelle „User_messages“ tatsächlich entfernt. Um die Nachricht vollständig zu löschen, müssen also alle User_messages-Datensätze für diese Nachricht entfernt werden.
Durch eine Denormalisierung der Daten in einer der Tabellen lässt sich dies viel einfacher bewerkstelligen: Wir können der Tabelle Messages einen users_received_count hinzufügen, um einen Datensatz der User_messages für eine bestimmte Nachricht zu erhalten. Wenn ein Benutzer diese Nachricht löscht (lies: den Zeiger auf die eigentliche Nachricht entfernt), wird die Spalte users_received_count um eins dekrementiert. Wenn users_received_count gleich null ist, kann die eigentliche Nachricht natürlich komplett gelöscht werden.
Verwenden von Pre-Join-Tabellen
Um Tabellen zu pre-joinen, müssen Sie eine Nicht-Schlüsselspalte zu einer Tabelle hinzufügen, die keinen Geschäftswert hat. Auf diese Weise können Sie das Joinen von Tabellen umgehen und somit Abfragen beschleunigen. Allerdings müssen Sie sicherstellen, dass die denormalisierte Spalte jedes Mal aktualisiert wird, wenn der Wert der Masterspalte geändert wird.
Diese Denormalisierungstechnik kann verwendet werden, wenn Sie viele Abfragen gegen viele verschiedene Tabellen machen müssen – und solange veraltete Daten akzeptabel sind.
| Nachteile | Nachteile |
|---|---|
| Keine Notwendigkeit, mehrere Joins zu verwenden | DML ist erforderlich, um die nichtdenormalisierte Spalte zu aktualisieren |
| Sie können Aktualisierungen so lange aufschieben, wie veraltete Daten toleriert werden können | Eine zusätzliche Spalte erfordert zusätzlichen Arbeits- und Speicherplatz |
Beispiel

Stellen Sie sich vor, dass Benutzer unseres E-Mail-Nachrichtendienstes auf Nachrichten nach Kategorien zugreifen möchten. Den Namen einer Kategorie direkt in der Tabelle „User_messages“ zu speichern, kann Zeit sparen und die Anzahl der notwendigen Joins reduzieren.
In der obigen denormalisierten Tabelle haben wir die Spalte „category_name“ eingeführt, um Informationen darüber zu speichern, zu welcher Kategorie jeder Datensatz in der Tabelle „User_messages“ gehört. Dank der Denormalisierung ist nur eine Abfrage auf die Tabelle „User_messages“ erforderlich, damit ein Benutzer alle Nachrichten auswählen kann, die zu einer bestimmten Kategorie gehören. Natürlich hat diese Denormalisierungstechnik einen Nachteil – diese zusätzliche Spalte kann viel Speicherplatz beanspruchen.
Verwendung von hartkodierten Werten
Wenn es eine Referenztabelle mit konstanten Datensätzen gibt, können Sie diese in Ihrer Anwendung hartkodieren. Auf diese Weise müssen Sie keine Tabellen verknüpfen, um die Referenzwerte zu holen.
Bei der Verwendung von hartkodierten Werten sollten Sie jedoch eine Prüfbeschränkung erstellen, um die Werte gegen die Referenzwerte zu validieren. Dieses Constraint muss jedes Mal neu geschrieben werden, wenn ein neuer Wert in der A-Tabelle benötigt wird.
Diese Technik der Daten-Denormalisierung sollte verwendet werden, wenn die Werte während des gesamten Lebenszyklus Ihres Systems statisch sind und solange die Anzahl dieser Werte recht klein ist. Werfen wir nun einen Blick auf die Vor- und Nachteile dieser Technik:
| Vorteile | Nachteile |
|---|---|
| Keine Notwendigkeit, eine Nachschlagetabelle zu implementieren | Umcodierung und Neuformatierung sind erforderlich, wenn Nachschlage-Werte geändert werden |
| Keine Joins zu einer Nachschlagetabelle |
Beispiel

Angenommen, wir müssen Hintergrundinformationen über Benutzer eines E-Mail-Nachrichtendienstes herausfinden, zum Beispiel die Art, oder den Typ, des Benutzers. Wir haben eine Tabelle „User_kinds“ erstellt, um Daten über die Arten von Benutzern zu speichern, die wir erkennen müssen.
Die in dieser Tabelle gespeicherten Werte werden wahrscheinlich nicht häufig geändert, also können wir Hardcoding anwenden. Wir können der Spalte eine Prüfbeschränkung hinzufügen oder die Prüfbeschränkung in die Feldüberprüfung für die Anwendung einbauen, in der sich die Benutzer bei unserem E-Mail-Nachrichtendienst anmelden.
Details mit dem Master aufbewahren
Es kann Fälle geben, in denen die Anzahl der Detailsätze pro Master festgelegt ist oder in denen Detailsätze mit dem Master abgefragt werden. In diesen Fällen können Sie eine Datenbank denormalisieren, indem Sie Detailspalten zur Mastertabelle hinzufügen. Diese Technik erweist sich als besonders nützlich, wenn nur wenige Datensätze in der Detailtabelle vorhanden sind.
| Vorteile | Nachteile |
|---|---|
| Keine Notwendigkeit, Joins zu verwenden | Erhöhte Komplexität der DML |
| Spart Platz |
Beispiel

Stellen Sie sich vor, dass wir die maximale Menge an Speicherplatz, die ein Benutzer erhalten kann, begrenzen müssen. Dazu müssen wir in unserem E-Mail-Nachrichtendienst Beschränkungen implementieren – eine für Nachrichten und eine für Dateien. Da die Menge des erlaubten Speicherplatzes für jede dieser Beschränkungen unterschiedlich ist, müssen wir jede Beschränkung einzeln verfolgen. In einer normalisierten relationalen Datenbank könnten wir einfach zwei verschiedene Tabellen einführen – Storage_types und Storage_restraints -, die Datensätze für jeden Benutzer speichern würden.
Anstatt dessen können wir einen anderen Weg gehen und denormalisierte Spalten zur Tabelle Users hinzufügen:
Nachrichten-Speicherplatz_zugeordnet
Nachrichten-Speicherplatz_verfügbar
Datei-Speicherplatz_zugeordnet
Datei-Speicherplatz_verfügbar
In diesem Fall speichert die denormalisierte Tabelle „Users“ nicht nur die eigentlichen Informationen über einen Benutzer, sondern auch die Einschränkungen, so dass die Tabelle von der Funktionalität her nicht ganz ihrem Namen entspricht.
Wiederholung eines einzelnen Details mit seinem Master
Wenn Sie mit historischen Daten arbeiten, benötigen viele Abfragen einen bestimmten einzelnen Datensatz und nur selten andere Details. Mit dieser Technik der Datenbankdenormalisierung können Sie eine neue Fremdschlüsselspalte einführen, um diesen Datensatz mit seinem Master zu speichern. Wenn Sie diese Art der Denormalisierung verwenden, sollten Sie nicht vergessen, Code hinzuzufügen, der die denormalisierte Spalte aktualisiert, wenn ein neuer Datensatz hinzugefügt wird.
| Vorteile | Nachteile |
|---|---|
| Keine Notwendigkeit, Joins für Abfragen zu erstellen, die einen einzelnen Datensatz benötigen | Dateninkonsistenzen sind möglich, da ein Datensatzwert wiederholt werden muss |
Beispiel
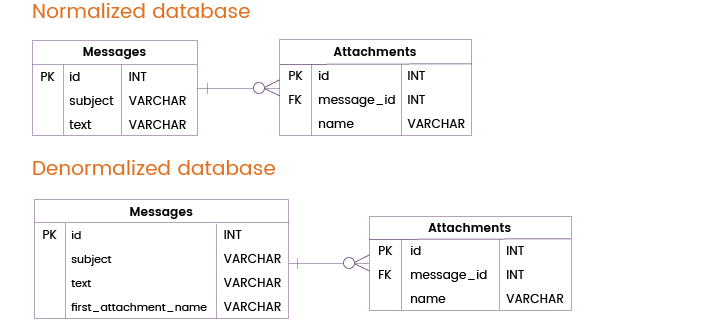
Oft, senden Benutzer nicht nur Nachrichten, sondern auch Anhänge. Die meisten Nachrichten werden entweder ohne Anhang oder mit einem einzigen Anhang verschickt, aber in einigen Fällen hängen Benutzer mehrere Dateien an eine Nachricht an.
Wir können einen Tabellen-Join vermeiden, indem wir die Tabelle „Messages“ durch Hinzufügen der Spalte „first_attachment_name“ denormalisieren. Wenn eine Nachricht mehr als einen Anhang enthält, wird natürlich nur der erste Anhang aus der Tabelle „Messages“ entnommen, während die anderen Anhänge in einer separaten Tabelle „Attachments“ gespeichert werden und daher Tabellen-Joins erfordern. In den meisten Fällen wird diese Denormalisierungstechnik jedoch sehr hilfreich sein.
Hinzufügen von Kurzschlussschlüsseln
Wenn eine Datenbank mehr als drei Ebenen von Master-Details hat und Sie nur Datensätze aus der niedrigsten und höchsten Ebene abfragen müssen, können Sie Ihre Datenbank denormalisieren, indem Sie Kurzschlussschlüssel erstellen, die die Enkel-Datensätze der niedrigsten Ebene mit den Großeltern-Datensätzen der höheren Ebene verbinden. Mit dieser Technik können Sie die Anzahl der Tabellen-Joins bei der Ausführung von Abfragen reduzieren.
| Vorteile | Nachteile |
|---|---|
| Weniger Tabellen werden bei Abfragen gejoint | Mehr Fremdschlüssel müssen verwendet werden |
| Brauche zusätzlichen Code, um die Konsistenz der Werte sicherzustellen |
Beispiel
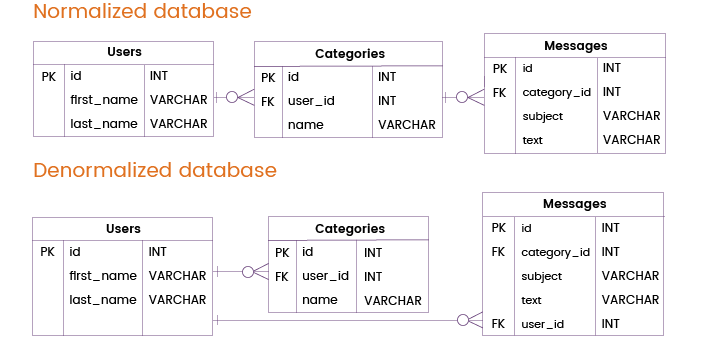
Stellen wir uns nun vor, dass ein E-Mail-Nachrichtendienst häufige Abfragen verarbeiten muss, die nur Daten aus den Tabellen „Benutzer“ und „Nachrichten“ benötigen, ohne die Tabelle Kategorien zu berücksichtigen. In einer normalisierten Datenbank müssten solche Abfragen die Tabellen „Benutzer“ und „Kategorien“ verknüpfen.
Um die Datenbankleistung zu verbessern und solche Verknüpfungen zu vermeiden, können wir einen Primär- oder eindeutigen Schlüssel aus der Tabelle „Benutzer“ direkt in die Tabelle „Nachrichten“ einfügen. Auf diese Weise können wir Informationen über Benutzer und Nachrichten bereitstellen, ohne die Tabelle „Kategorien“ abzufragen, was bedeutet, dass wir auf einen redundanten Tabellen-Join verzichten können.
Nachteile der Datenbank-Denormalisierung
Nun fragen Sie sich wahrscheinlich: denormalisieren oder nicht denormalisieren?
Auch wenn die Denormalisierung der beste Weg zu sein scheint, um die Leistung einer Datenbank und damit einer Anwendung im Allgemeinen zu steigern, sollten Sie nur darauf zurückgreifen, wenn sich andere Methoden als ineffizient erweisen. Zum Beispiel kann eine unzureichende Datenbankleistung oft durch falsch geschriebene Abfragen, fehlerhaften Anwendungscode, inkonsistentes Indexdesign oder sogar eine unsachgemäße Hardwarekonfiguration verursacht werden.
Die Denormalisierung klingt verlockend und in der Theorie äußerst effizient, aber sie bringt eine Reihe von Nachteilen mit sich, über die Sie sich im Klaren sein müssen, bevor Sie diese Strategie anwenden:
- Zusätzlicher Speicherplatz
Wenn Sie eine Datenbank denormalisieren, müssen Sie viele Daten duplizieren. Natürlich wird Ihre Datenbank mehr Speicherplatz benötigen.
- Zusätzliche Dokumentation
Jeder einzelne Schritt, den Sie während der Denormalisierung durchführen, muss ordnungsgemäß dokumentiert werden. Wenn Sie das Design Ihrer Datenbank später einmal ändern, müssen Sie alle Regeln, die Sie zuvor erstellt haben, überarbeiten: Sie brauchen einige von ihnen vielleicht nicht oder müssen bestimmte Denormalisierungsregeln aktualisieren.
- Potentielle Datenanomalien
Wenn Sie eine Datenbank denormalisieren, sollten Sie sich darüber im Klaren sein, dass Sie mehr Daten erhalten, die verändert werden können. Entsprechend müssen Sie sich um jeden einzelnen Fall von doppelten Daten kümmern. Sie sollten Trigger, Stored Procedures und Transaktionen verwenden, um Datenanomalien zu vermeiden.
- Mehr Code
Wenn Sie eine Datenbank denormalisieren, ändern Sie Select-Abfragen, und obwohl dies viele Vorteile bringt, hat es seinen Preis – Sie müssen zusätzlichen Code schreiben. Außerdem müssen Sie Werte in neuen Attributen aktualisieren, die Sie zu bestehenden Datensätzen hinzufügen, was bedeutet, dass noch mehr Code erforderlich ist.
- Langsamere Operationen
Die Denormalisierung einer Datenbank kann Datenabrufe beschleunigen, verlangsamt aber gleichzeitig die Aktualisierungen. Wenn Ihre Anwendung viele Schreiboperationen in die Datenbank durchführen muss, kann sie eine langsamere Leistung aufweisen als eine ähnliche normalisierte Datenbank. Stellen Sie also sicher, dass Sie die Denormalisierung implementieren, ohne die Benutzerfreundlichkeit Ihrer Anwendung zu beeinträchtigen.
Tipps zur Datenbankdenormalisierung
Wie Sie sehen, ist die Denormalisierung ein ernsthafter Prozess, der viel Aufwand und Geschick erfordert. Wenn Sie Datenbanken ohne Probleme denormalisieren wollen, sollten Sie diese nützlichen Tipps befolgen:
- Anstatt gleich zu versuchen, die gesamte Datenbank zu denormalisieren, konzentrieren Sie sich auf bestimmte Teile, die Sie beschleunigen wollen.
- Tun Sie Ihr Bestes, um das logische Design Ihrer Anwendung wirklich gut kennenzulernen, um zu verstehen, welche Teile Ihres Systems wahrscheinlich von der Denormalisierung betroffen sein werden.
- Analysieren Sie, wie oft Daten in Ihrer Anwendung geändert werden; wenn sich Daten zu oft ändern, könnte die Aufrechterhaltung der Integrität Ihrer Datenbank nach der Denormalisierung zu einem echten Problem werden.
- Schauen Sie sich genau an, welche Teile Ihrer Anwendung Leistungsprobleme haben; oft können Sie Ihre Anwendung beschleunigen, indem Sie Abfragen feiner abstimmen, anstatt die Datenbank zu denormalisieren.
- Lernen Sie mehr über Datenspeichertechniken; die Auswahl der relevantesten kann Ihnen helfen, auf die Denormalisierung zu verzichten.
Abschließende Gedanken
Sie sollten immer mit dem Aufbau einer sauberen und leistungsstarken normalisierten Datenbank beginnen. Nur wenn Sie Ihre Datenbank für bestimmte Aufgaben (z. B. Berichte) leistungsfähiger machen müssen, sollten Sie sich für eine Denormalisierung entscheiden. Wenn Sie denormalisieren, seien Sie vorsichtig und stellen Sie sicher, dass Sie alle Änderungen, die Sie an der Datenbank vornehmen, dokumentieren.
Bevor Sie sich für die Denormalisierung entscheiden, stellen Sie sich die folgenden Fragen:
- Kann mein System ohne Denormalisierung eine ausreichende Leistung erreichen?
- Wird die Leistung meiner Datenbank nach der Denormalisierung inakzeptabel?
- Wird mein System unzuverlässiger?
Wenn die Antwort auf eine dieser Fragen „Ja“ lautet, sollten Sie besser auf die Denormalisierung verzichten, da sie sich für Ihre Anwendung als ineffizient erweisen dürfte. Wenn die Denormalisierung jedoch Ihre einzige Option ist, sollten Sie die Datenbank zunächst korrekt normalisieren und dann zur Denormalisierung übergehen, wobei Sie sich sorgfältig und strikt an die Techniken halten sollten, die wir in diesem Artikel beschrieben haben.
Wenn Sie weitere Einblicke in die neuesten Trends in der Softwareentwicklung erhalten möchten, abonnieren Sie unseren Blog.