Dieser Beitrag behandelt die Grundlagen von Apache Parquet, das ein wichtiger Baustein in der Big Data-Architektur ist. Wenn Sie mehr über die Verwaltung von Dateien im Objektspeicher erfahren möchten, lesen Sie unseren Leitfaden zur Partitionierung von Daten auf Amazon S3.
Auf der letztjährigen Amazon re:Invent-Konferenz (als es noch echte Konferenzen gab) kündigte AWS den Data Lake-Export an – die Möglichkeit, das Ergebnis einer Redshift-Abfrage im Apache Parquet-Format auf Amazon S3 zu entladen. In der Ankündigung beschrieb AWS Parquet als „2x schneller beim Entladen und verbraucht bis zu 6x weniger Speicherplatz in Amazon S3, verglichen mit Textformaten“. Die Konvertierung von Daten in kolumnare Formate wie Parquet oder ORC wird auch als Mittel zur Verbesserung der Leistung von Amazon Athena empfohlen.
Es ist klar, dass Apache Parquet eine wichtige Rolle für die Systemleistung beim Arbeiten mit Data Lakes spielt. Lassen Sie uns einen genaueren Blick darauf werfen, was Parquet eigentlich ist und warum es für Big-Data-Speicher und -Analysen wichtig ist.
Die Grundlagen: Was ist Apache Parquet?
Apache Parquet ist ein Dateiformat, das entwickelt wurde, um eine schnelle Datenverarbeitung für komplexe Daten zu unterstützen, mit mehreren bemerkenswerten Eigenschaften:
1. Spaltenbasiert: Im Gegensatz zu zeilenbasierten Formaten wie CSV oder Avro ist Apache Parquet spaltenorientiert – das bedeutet, dass die Werte jeder Tabellenspalte nebeneinander gespeichert werden und nicht die der einzelnen Datensätze:
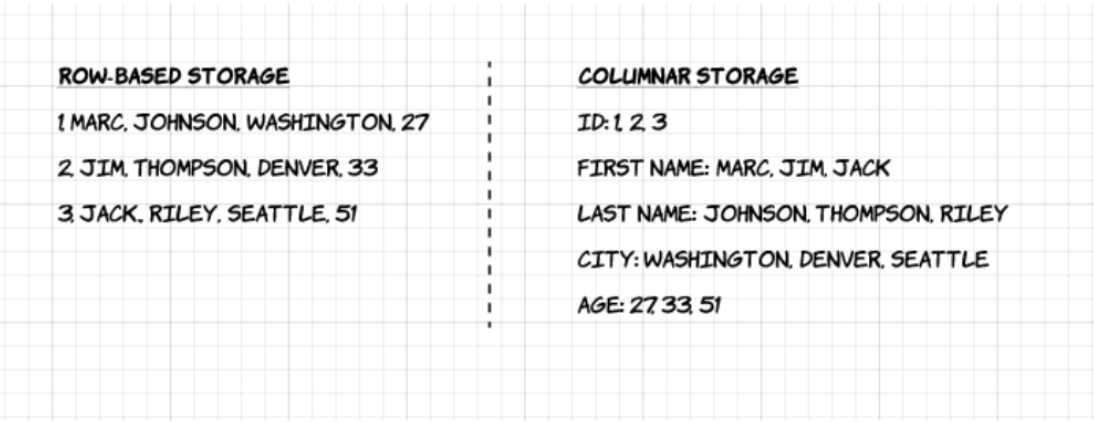
2. Open-Source: Parquet ist kostenlos und quelloffen unter der Apache-Hadoop-Lizenz und ist mit den meisten Hadoop-Datenverarbeitungs-Frameworks kompatibel.
3. Selbstbeschreibend: In Parquet sind Metadaten, einschließlich Schema und Struktur, in jede Datei eingebettet, was es zu einem selbstbeschreibenden Dateiformat macht.
Vorteile von Parquet Columnar Storage
Die oben genannten Eigenschaften des Apache Parquet-Dateiformats schaffen mehrere deutliche Vorteile, wenn es um das Speichern und Analysieren großer Datenmengen geht. Schauen wir uns einige davon genauer an.
Komprimierung
Die Dateikomprimierung ist der Akt, eine Datei zu verkleinern. In Parquet wird die Komprimierung spaltenweise durchgeführt und es ist so aufgebaut, dass es flexible Komprimierungsoptionen und erweiterbare Kodierungsschemata pro Datentyp unterstützt – z.B. können unterschiedliche Kodierungen für die Komprimierung von Integer- und String-Daten verwendet werden.
Parquet-Daten können mit diesen Kodierungsmethoden komprimiert werden:
- Wörterbuchkodierung: Diese wird automatisch und dynamisch für Daten mit einer geringen Anzahl eindeutiger Werte aktiviert.
- Bitpacking: Die Speicherung von Ganzzahlen erfolgt normalerweise mit dedizierten 32 oder 64 Bits pro Ganzzahl. Dies ermöglicht eine effizientere Speicherung von kleinen Ganzzahlen.
- Lauflängenkodierung (RLE): Wenn derselbe Wert mehrfach vorkommt, wird ein einzelner Wert zusammen mit der Anzahl der Vorkommen einmal gespeichert. Parquet implementiert eine kombinierte Version von Bit-Packing und RLE, bei der die Kodierung je nachdem, was die besten Kompressionsergebnisse liefert, umgeschaltet wird.

Performance
Im Gegensatz zu zeilenbasierten Dateiformaten wie CSV ist Parquet auf Performance optimiert. Wenn Sie Abfragen auf Ihrem Parquet-basierten Dateisystem ausführen, können Sie sich sehr schnell nur auf die relevanten Daten konzentrieren. Außerdem ist die Menge der gescannten Daten viel kleiner und führt zu einer geringeren I/O-Nutzung. Um dies zu verstehen, lassen Sie uns ein wenig tiefer in die Struktur von Parquet-Dateien eintauchen.
Wie bereits erwähnt, ist Parquet ein selbstbeschriebenes Format, so dass jede Datei sowohl Daten als auch Metadaten enthält. Parquet-Dateien sind aus Zeilengruppen, Kopf- und Fußzeilen zusammengesetzt. Jede Zeilengruppe enthält Daten aus denselben Spalten. In jeder Zeilengruppe werden dieselben Spalten zusammen gespeichert:
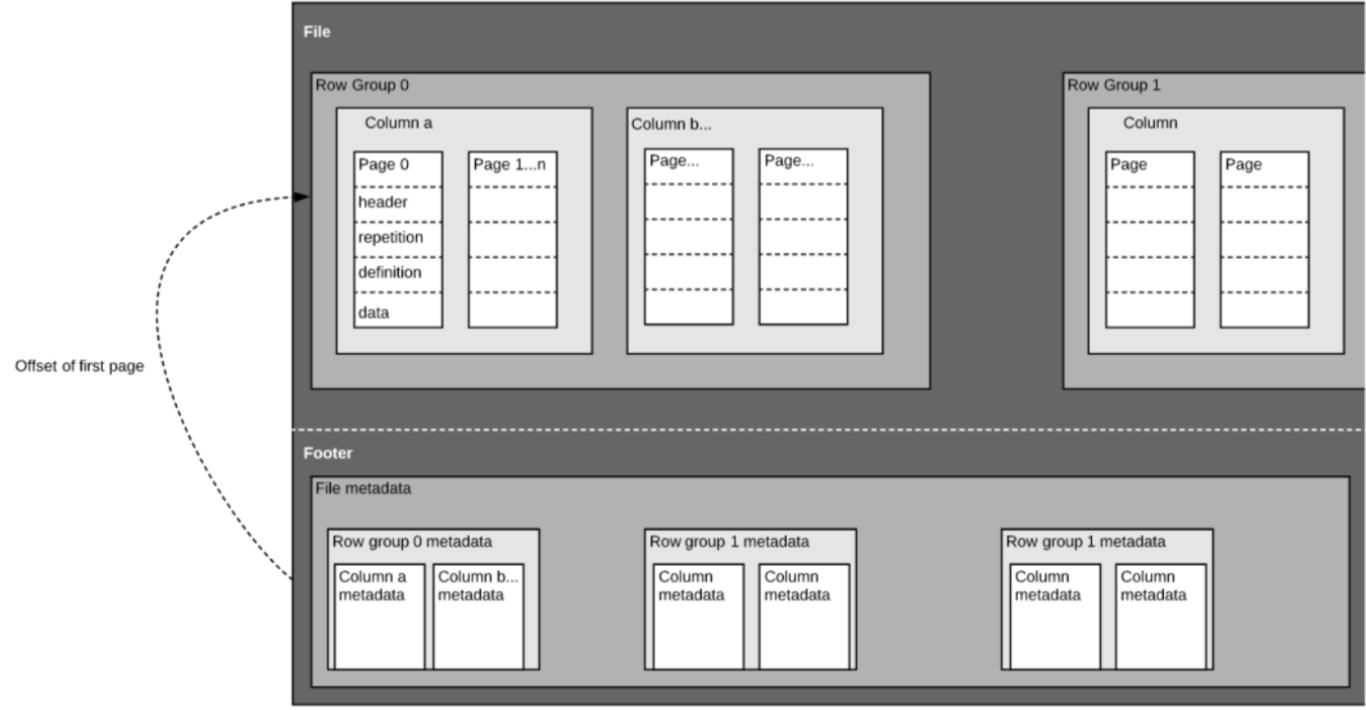
Diese Struktur ist sowohl für eine schnelle Abfrageleistung als auch für eine geringe E/A (Minimierung der zu scannenden Datenmenge) gut optimiert. Wenn Sie z. B. eine Tabelle mit 1000 Spalten haben, die Sie in der Regel nur mit einer kleinen Teilmenge von Spalten abfragen werden. Die Verwendung von Parquet-Dateien ermöglicht es Ihnen, nur die benötigten Spalten und deren Werte zu holen, diese in den Speicher zu laden und die Abfrage zu beantworten. Bei einem zeilenbasierten Dateiformat wie CSV müsste die gesamte Tabelle in den Speicher geladen werden, was zu erhöhter E/A und schlechterer Leistung führen würde.
Schema-Evolution
Bei der Verwendung von spaltenbasierten Dateiformaten wie Parquet können Benutzer mit einem einfachen Schema beginnen und nach und nach weitere Spalten zum Schema hinzufügen, je nach Bedarf. Auf diese Weise können Benutzer am Ende mehrere Parquet-Dateien mit unterschiedlichen, aber miteinander kompatiblen Schemata haben. In diesen Fällen unterstützt Parquet das automatische Zusammenführen von Schemas zwischen diesen Dateien.
Open-Source-Unterstützung
Apache Parquet ist, wie bereits erwähnt, Teil des Apache Hadoop-Ökosystems, das quelloffen ist und von einer starken Gemeinschaft von Anwendern und Entwicklern ständig verbessert und unterstützt wird. Die Speicherung Ihrer Daten in offenen Formaten bedeutet, dass Sie eine Herstellerbindung vermeiden und Ihre Flexibilität im Vergleich zu proprietären Dateiformaten, die von vielen modernen Hochleistungsdatenbanken verwendet werden, erhöhen. Das bedeutet, dass Sie verschiedene Abfrage-Engines wie Amazon Athena, Qubole und Amazon Redshift Spectrum innerhalb derselben Data Lake-Architektur verwenden können.
Spaltenorientierte vs. zeilenbasierte Speicherung für analytische Abfragen
Daten werden oft in Zeilen generiert und sind einfacher zu konzeptualisieren. Wir sind es gewohnt, in Begriffen von Excel-Tabellen zu denken, wo wir alle für einen bestimmten Datensatz relevanten Daten in einer einzigen übersichtlichen Zeile sehen können. Für umfangreiche analytische Abfragen bietet die spaltenbasierte Speicherung jedoch erhebliche Vorteile in Bezug auf Kosten und Leistung.
Komplexe Daten wie Protokolle und Ereignisströme müssten als Tabelle mit Hunderten oder Tausenden von Spalten und vielen Millionen von Zeilen dargestellt werden. Die Speicherung dieser Tabelle in einem zeilenbasierten Format wie CSV würde bedeuten:
- Die Ausführung von Abfragen dauert länger, da mehr Daten gescannt werden müssen, anstatt nur die Teilmenge der Spalten abzufragen, die wir zur Beantwortung einer Abfrage benötigen (was typischerweise eine Aggregation auf Basis von Dimensionen oder Kategorien erfordert)
- Die Speicherung wird kostspieliger, da CSVs nicht so effizient wie Parquet komprimiert werden
Spaltenbasierte Formate bieten eine bessere Komprimierung und eine verbesserte Leistung von Anfang an und ermöglichen die vertikale Abfrage von Daten – Spalte für Spalte.
Beispiel: Parquet, CSV und Amazon Athena
Wir werden dieses Beispiel in unserem kommenden Webinar mit Looker noch viel ausführlicher behandeln. Sichern Sie sich hier Ihren Platz.
Um die Auswirkungen der spaltenbasierten Parquet-Speicherung im Vergleich zu zeilenbasierten Alternativen zu demonstrieren, schauen wir uns an, was passiert, wenn Sie Amazon Athena verwenden, um Daten abzufragen, die in beiden Fällen auf Amazon S3 gespeichert sind.
Mit Upsolver haben wir einen CSV-Datensatz mit Serverprotokollen in S3 aufgenommen. In einer üblichen AWS Data Lake-Architektur würde Athena verwendet werden, um die Daten direkt von S3 abzufragen. Diese Abfragen können dann mit interaktiven Datenvisualisierungstools wie Tableau oder Looker visualisiert werden.
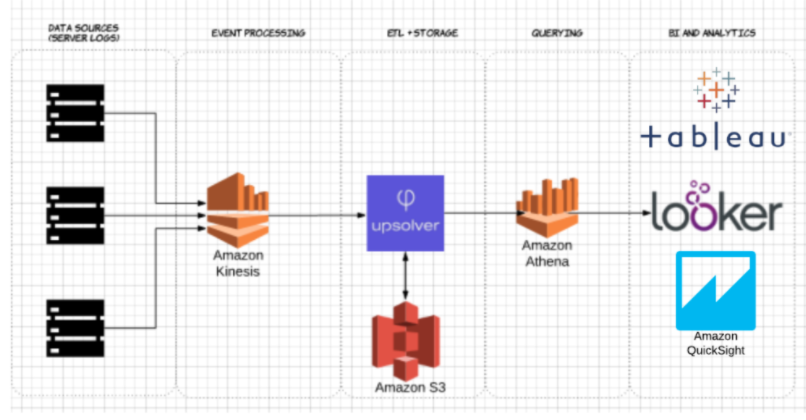
Wir haben Athena mit demselben Datensatz getestet, der als komprimiertes CSV und als Apache Parquet gespeichert wurde.
Das ist die Abfrage, die wir in Athena ausgeführt haben:
SELECT tags_host AS host_id, AVG(felder_auslastung_aktiv) as avg_auslastung
FROM server_auslastung
GROUP BY tags_host
HAVING AVG(fields_usage_active) > 0
LIMIT 10
Und die Ergebnisse:
| CSV | Parquet | Spalten | |
| Abfragezeit (Sekunden) | 735 | 211 | 18 |
| Daten gescannt (GB) | 372.2 | 10.29 | 18 |
- Komprimierte CSVs: Die komprimierte CSV hat 18 Spalten und wiegt 27 GB auf S3. Athena muss die gesamte CSV-Datei scannen, um die Abfrage zu beantworten, wir würden also für 27 GB gescannte Daten bezahlen. Bei höheren Skalierungen würde sich dies auch negativ auf die Leistung auswirken.
- Parquet: Wenn wir unsere komprimierten CSV-Dateien in Apache Parquet konvertieren, erhalten wir eine ähnliche Datenmenge in S3. Da Parquet jedoch spaltenorientiert ist, muss Athena nur die Spalten lesen, die für die ausgeführte Abfrage relevant sind – eine kleine Teilmenge der Daten. In diesem Fall musste Athena 0,22 GB Daten scannen. Anstatt für 27 GB gescannte Daten zu zahlen, zahlen wir also nur für 0,22 GB.
Ist die Verwendung von Parquet genug?
Die Verwendung von Parquet ist ein guter Anfang; die Optimierung von Data Lake-Abfragen endet jedoch nicht dort. Oft müssen Sie die Daten bereinigen, anreichern und transformieren, Joins mit hoher Kardinalität durchführen und eine Vielzahl von Best Practices implementieren, um sicherzustellen, dass Abfragen konsistent, schnell und kosteneffizient beantwortet werden.
Sie können Upsolver verwenden, um Ihre Data Lake ETL-Pipeline zu vereinfachen, Daten automatisch als optimiertes Parquet zu importieren und Streaming-Daten mit SQL- oder Excel-ähnlichen Funktionen zu transformieren. Um mehr zu erfahren, vereinbaren Sie gleich hier eine Demo.
Wollen Sie mehr über die Optimierung Ihres Data Lakes erfahren? Sehen Sie sich einige dieser Data Lake Best Practices an. Um weitere Benchmarks zu sehen und Best Practices für die Vorbereitung von Daten für Athena zu lernen, nehmen Sie am kommenden Webinar von Upsolver + Looker teil, das Sie hier finden.