La vitesse des sites Web est une priorité pour les entreprises en 2020.
Les sites Web plus rapides sont mieux classés sur les moteurs de recherche et offrent également de meilleures expériences aux utilisateurs, ce qui entraîne des taux de conversion plus élevés. Il n’est donc pas étonnant que les propriétaires de sites Web exigent des vitesses de chargement des pages plus rapides – laissant aux développeurs le soin de les concrétiser.
L’optimisation de la base de données est une étape essentielle pour améliorer les performances des sites Web. Généralement, les développeurs normalisent une base de données relationnelle, ce qui signifie qu’ils la restructurent pour réduire la redondance des données et améliorer leur intégrité. Cependant, parfois, normaliser une base de données ne suffit pas, alors pour améliorer encore plus les performances de la base de données, les développeurs font le chemin inverse et ont recours à la dénormalisation de la base de données.
Dans cet article, nous examinons de plus près la dénormalisation pour savoir quand cette méthode est appropriée et comment vous pouvez la réaliser.
Quand dénormaliser une base de données
Qu’est-ce que la dénormalisation de la base de données ? Avant de plonger dans le sujet, soulignons que la normalisation reste toujours le point de départ, ce qui signifie que vous devez tout d’abord normaliser la structure d’une base de données. L’essence de la normalisation est de mettre chaque élément de données à sa place, ce qui garantit l’intégrité des données et facilite leur mise à jour. Cependant, l’extraction de données d’une base de données normalisée peut être plus lente, car les requêtes doivent s’adresser à de nombreuses tables différentes où sont stockés différents éléments de données. La mise à jour, au contraire, devient plus rapide, car tous les éléments de données sont stockés en un seul endroit.
La majorité des applications modernes doivent être en mesure de récupérer des données dans le plus court délai possible. Et c’est à ce moment-là que vous pouvez envisager de dénormaliser une base de données relationnelle. Comme son nom l’indique, la dénormalisation est le contraire de la normalisation. Lorsque vous normalisez une base de données, vous organisez les données pour garantir leur intégrité et éliminer les redondances. La dénormalisation d’une base de données signifie que vous mettez délibérément les mêmes données à plusieurs endroits, ce qui augmente la redondance.
« Pourquoi dénormaliser une base de données ? » vous pouvez vous demander. L’objectif principal de la dénormalisation est d’accélérer considérablement la récupération des données. Cependant, la dénormalisation n’est pas une pilule magique. Les développeurs ne doivent utiliser cet outil qu’à des fins particulières :
# 1 Pour améliorer les performances des requêtes
Typiquement, une base de données normalisée nécessite de joindre beaucoup de tables pour récupérer les requêtes ; mais plus il y a de jointures, plus la requête est lente. Comme contre-mesure, vous pouvez ajouter de la redondance à une base de données en copiant les valeurs entre les tables parent et enfant et, par conséquent, en réduisant le nombre de jointures requises pour une requête.
#2 Pour rendre une base de données plus pratique à gérer
Une base de données normalisée n’a pas de valeurs calculées qui sont essentielles pour les applications. Le calcul de ces valeurs à la volée nécessiterait du temps, ralentissant l’exécution des requêtes.
Vous pouvez dénormaliser une base de données pour fournir des valeurs calculées. Une fois qu’elles sont générées et ajoutées aux tables, les programmeurs en aval peuvent facilement créer leurs propres rapports et requêtes sans avoir une connaissance approfondie du code ou de l’API de l’application.
#3 Pour faciliter et accélérer le reporting
Souvent, les applications doivent fournir beaucoup d’informations analytiques et statistiques. La génération de rapports à partir de données en direct prend du temps et peut avoir un impact négatif sur les performances globales du système.
Dénormaliser votre base de données peut vous aider à relever ce défi. Supposons que vous deviez fournir un résumé des ventes totales pour un ou plusieurs utilisateurs ; une base de données normalisée agrégerait et calculerait tous les détails des factures plusieurs fois. Inutile de dire que cela prendrait beaucoup de temps, donc pour accélérer ce processus, vous pourriez maintenir le résumé des ventes depuis le début de l’année dans une table stockant les détails de l’utilisateur.
Techniques de dénormalisation de la base de données
Maintenant que vous savez quand vous devriez opter pour la dénormalisation de la base de données, vous vous demandez probablement comment le faire correctement. Il existe plusieurs techniques de dénormalisation, chacune étant appropriée à une situation particulière. Explorons-les en profondeur :
Stocker les données dérivables
Si vous devez exécuter un calcul de manière répétée lors de requêtes, il est préférable de stocker les résultats de celui-ci. Si le calcul contient des enregistrements détaillés, vous devez stocker le calcul dérivé dans la table principale. Chaque fois que vous décidez de stocker des valeurs dérivées, assurez-vous que les valeurs dénormalisées sont toujours recalculées par le système.
Voici des situations où le stockage de valeurs dérivables est approprié :
- Quand vous avez fréquemment besoin de valeurs dérivables
- Quand vous ne modifiez pas fréquemment les valeurs sources
| Avantages | Inconvénients | Aucun besoin de rechercher les valeurs sources à chaque fois. besoin de rechercher les valeurs sources chaque fois qu’une valeur dérivable est nécessaire | Exécution d’instructions en langage de manipulation des données (DML) contre la source. (DML) contre les données sources nécessite un nouveau calcul des données dérivables |
|---|---|
| Pas besoin d’effectuer un calcul pour chaque requête ou rapport | Des incohérences de données sont possibles en raison de la duplication des données |
Exemple

A titre d’exemple de cette technique de dénormalisation, supposons que nous construisions un service de messagerie électronique. Après avoir reçu un message, un utilisateur ne reçoit qu’un pointeur vers ce message ; le pointeur est stocké dans la table User_messages. Cela permet d’éviter que le système de messagerie ne stocke plusieurs copies d’un message électronique au cas où il serait envoyé à plusieurs destinataires différents à la fois. Mais que se passe-t-il si un utilisateur supprime un message de son compte ? Dans ce cas, seule l’entrée correspondante dans la table User_messages est réellement supprimée. Donc, pour supprimer complètement le message, tous les enregistrements User_messages le concernant doivent être supprimés.
La dénormalisation des données dans l’une des tables peut rendre cela beaucoup plus simple : nous pouvons ajouter un users_received_count à la table Messages pour conserver un enregistrement des User_messages conservés pour un message spécifique. Lorsqu’un utilisateur supprime ce message (lire : supprime le pointeur vers le message réel), la colonne users_received_count est décrémentée de un. Naturellement, lorsque le users_received_count est égal à zéro, le message réel peut être complètement supprimé.
Utiliser des tables pré-jointes
Pour pré-jointer des tables, vous devez ajouter une colonne non clé à une table qui ne porte aucune valeur commerciale. De cette façon, vous pouvez éviter de joindre des tables et donc accélérer les requêtes. Pourtant, vous devez vous assurer que la colonne dénormalisée est mise à jour chaque fois que la valeur de la colonne maîtresse est modifiée.
Cette technique de dénormalisation peut être utilisée lorsque vous devez effectuer de nombreuses requêtes contre de nombreuses tables différentes – et tant que les données périmées sont acceptables.
| Avantages | Inconvénients |
|---|---|
| Pas besoin d’utiliser des jointures multiples | DML est nécessaire pour mettre à jour la colonne nondénormalisée | Vous pouvez repousser les mises à jour tant que les données périmées sont tolérables | Une colonne supplémentaire nécessite du travail et de l’espace disque supplémentaires |
Exemple

Imaginez que les utilisateurs de notre service de messagerie électronique souhaitent accéder aux messages par catégorie. Conserver le nom d’une catégorie directement dans la table User_messages peut permettre de gagner du temps et de réduire le nombre de jointures nécessaires.
Dans la table dénormalisée ci-dessus, nous avons introduit la colonne category_name pour stocker des informations sur la catégorie à laquelle chaque enregistrement de la table User_messages est lié. Grâce à la dénormalisation, seule une requête sur la table User_messages est nécessaire pour permettre à un utilisateur de sélectionner tous les messages appartenant à une catégorie spécifique. Bien sûr, cette technique de dénormalisation a un inconvénient : cette colonne supplémentaire peut nécessiter beaucoup d’espace de stockage.
Utiliser des valeurs codées en dur
S’il existe une table de référence avec des enregistrements constants, vous pouvez les coder en dur dans votre application. De cette façon, vous n’avez pas besoin de joindre des tables pour récupérer les valeurs de référence.
Cependant, lorsque vous utilisez des valeurs codées en dur, vous devez créer une contrainte de contrôle pour valider les valeurs par rapport aux valeurs de référence. Cette contrainte doit être réécrite chaque fois qu’une nouvelle valeur dans la table A est requise.
Cette technique de dénormalisation des données doit être utilisée si les valeurs sont statiques tout au long du cycle de vie de votre système et tant que le nombre de ces valeurs est assez faible. Voyons maintenant les avantages et les inconvénients de cette technique :
| Avantages | Inconvénients |
|---|---|
| Nul besoin d’implémenter une table de consultation | Le recodage et le retraitement sont nécessaires si les valeurs de la table de consultation sont modifiées |
| Pas de jointures à une table de recherche |
Exemple

Supposons que nous devions trouver des informations générales sur les utilisateurs d’un service de messagerie électronique, par exemple, le genre ou le type d’utilisateur. Nous avons créé une table User_kinds pour stocker les données sur les types d’utilisateurs que nous devons reconnaître.
Les valeurs stockées dans cette table ne sont pas susceptibles d’être modifiées fréquemment, nous pouvons donc appliquer un codage en dur. Nous pouvons ajouter une contrainte de contrôle à la colonne ou intégrer la contrainte de contrôle dans la validation du champ pour l’application où les utilisateurs se connectent à notre service de messagerie électronique.
Garder les détails avec le maître
Il peut y avoir des cas où le nombre d’enregistrements de détails par maître est fixe ou lorsque les enregistrements de détails sont interrogés avec le maître. Dans ces cas, vous pouvez dénormaliser une base de données en ajoutant des colonnes de détails à la table maître. Cette technique s’avère des plus utiles lorsque les enregistrements de la table de détail sont peu nombreux.
| Avantages | Inconvénients | |
|---|---|---|
| Pas besoin d’utiliser les jointures | Augmentation de la complexité du DML | . complexité du DML |
| Gain d’espace |
Exemple

Imaginez que nous devons limiter la quantité maximale d’espace de stockage qu’un utilisateur peut obtenir. Pour ce faire, nous devons mettre en place des restrictions dans notre service de messagerie électronique – une pour les messages et une autre pour les fichiers. Comme la quantité d’espace de stockage autorisée pour chacune de ces restrictions est différente, nous devons suivre chaque restriction individuellement. Dans une base de données relationnelle normalisée, nous pourrions simplement introduire deux tables différentes – Storage_types et Storage_restraints – qui stockeraient des enregistrements pour chaque utilisateur.
Au lieu de cela, nous pouvons suivre une autre voie et ajouter des colonnes dénormalisées à la table Utilisateurs :
message_space_allocated
message_space_available
file_space_allocated
file_space_available
Dans ce cas, la table Users dénormalisée stocke non seulement les informations réelles sur un utilisateur mais aussi les restrictions, donc en termes de fonctionnalité, la table ne correspond pas complètement à son nom.
Répéter un détail unique avec son maître
Lorsque vous traitez des données historiques, de nombreuses requêtes ont besoin d’un enregistrement unique spécifique et rarement d’autres détails. Avec cette technique de dénormalisation de la base de données, vous pouvez introduire une nouvelle colonne de clé étrangère pour stocker cet enregistrement avec son maître. Lorsque vous utilisez ce type de dénormalisation, n’oubliez pas d’ajouter un code qui mettra à jour la colonne dénormalisée lorsqu’un nouvel enregistrement sera ajouté.
| Avantages | Inconvénients |
|---|---|
| Pas besoin de créer des jointures pour les requêtes qui nécessitent un seul enregistrement | Des incohérences de données sont possibles car la valeur d’un enregistrement doit être répétée |
Exemple
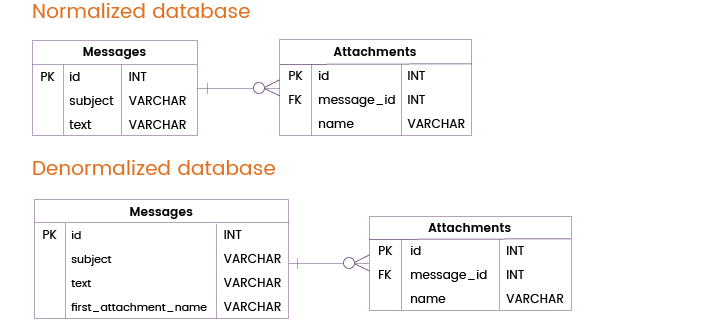
Souvent, les utilisateurs envoient non seulement des messages mais aussi des pièces jointes. La majorité des messages sont envoyés soit sans pièce jointe, soit avec une seule pièce jointe, mais dans certains cas, les utilisateurs joignent plusieurs fichiers à un message.
Nous pouvons éviter une jointure de table en dénormalisant la table Messages par l’ajout de la colonne first_attachment_name. Naturellement, si un message contient plus d’une pièce jointe, seule la première pièce jointe sera extraite de la table Messages tandis que les autres pièces jointes seront stockées dans une table Attachments distincte et, par conséquent, nécessiteront des jointures de table. Dans la plupart des cas, cependant, cette technique de dénormalisation sera vraiment utile.
Ajout de clés de court-circuit
Si une base de données comporte plus de trois niveaux de détails de base et que vous devez interroger uniquement les enregistrements des niveaux les plus bas et les plus élevés, vous pouvez dénormaliser votre base de données en créant des clés de court-circuit qui relient les enregistrements de petits-enfants de niveau le plus bas aux enregistrements de grands-parents de niveau plus élevé. Cette technique vous permet de réduire le nombre de jointures de tables lors de l’exécution des requêtes.
| Avantages | Inconvénients |
|---|---|
| Moins de tables sont jointes lors des requêtes | Nécessité d’utiliser plus de clés étrangères |
| Nécessité de code supplémentaire pour assurer la cohérence des valeurs |
Exemple
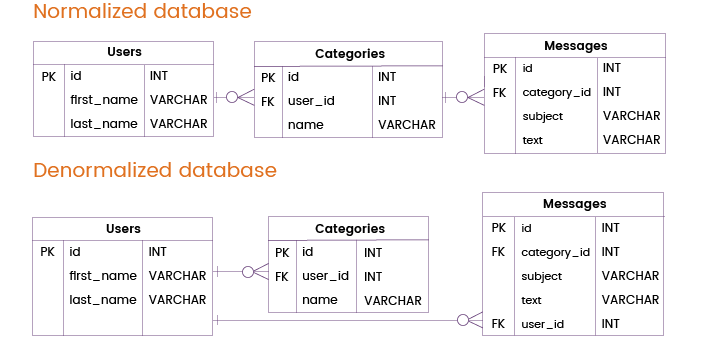
Imaginons maintenant qu’un service de messagerie électronique doive gérer des requêtes fréquentes qui nécessitent les données des tables Utilisateurs et Messages uniquement, sans aborder la table Catégories. Dans une base de données normalisée, de telles requêtes devraient joindre les tables Utilisateurs et Catégories.
Pour améliorer les performances de la base de données et éviter ces jointures, nous pouvons ajouter une clé primaire ou unique de la table Utilisateurs directement à la table Messages. De cette façon, nous pouvons fournir des informations sur les utilisateurs et les messages sans interroger la table Catégories, ce qui signifie que nous pouvons nous passer d’une jointure de table redondante.
Inconvénients de la dénormalisation de la base de données
Maintenant, vous vous demandez probablement : dénormaliser ou ne pas dénormaliser ?
Bien que la dénormalisation semble être le meilleur moyen d’augmenter les performances d’une base de données et, par conséquent, d’une application en général, vous ne devriez y recourir que lorsque les autres méthodes s’avèrent inefficaces. Par exemple, les performances souvent insuffisantes d’une base de données peuvent être causées par des requêtes mal écrites, un code d’application défectueux, une conception d’index incohérente ou même une mauvaise configuration matérielle.
La dénormalisation semble tentante et extrêmement efficace en théorie, mais elle s’accompagne d’un certain nombre d’inconvénients dont vous devez être conscient avant de vous lancer dans cette stratégie :
- Espace de stockage supplémentaire
Lorsque vous dénormalisez une base de données, vous devez dupliquer un grand nombre de données. Naturellement, votre base de données aura besoin de plus d’espace de stockage.
- Documentation supplémentaire
Chaque étape que vous prenez pendant la dénormalisation doit être correctement documentée. Si vous modifiez la conception de votre base de données quelque temps plus tard, vous devrez réviser toutes les règles que vous avez créées auparavant : il se peut que vous n’ayez pas besoin de certaines d’entre elles ou que vous deviez mettre à niveau des règles de dénormalisation particulières.
- Anomalies de données potentielles
Lorsque vous dénormalisez une base de données, vous devez comprendre que vous obtenez plus de données qui peuvent être modifiées. En conséquence, vous devez prendre soin de chaque cas de données dupliquées. Vous devez utiliser des déclencheurs, des procédures stockées et des transactions pour éviter les anomalies de données.
- Plus de code
Lorsque vous dénormalisez une base de données, vous modifiez les requêtes de sélection, et bien que cela apporte beaucoup d’avantages, cela a son prix – vous devez écrire du code supplémentaire. Vous devez également mettre à jour les valeurs des nouveaux attributs que vous ajoutez aux enregistrements existants, ce qui signifie qu’il faut encore plus de code.
- Les opérations plus lentes
La dénormalisation de la base de données peut accélérer les récupérations de données, mais en même temps, elle ralentit les mises à jour. Si votre application doit effectuer beaucoup d’opérations d’écriture dans la base de données, elle peut présenter des performances plus lentes qu’une base de données normalisée similaire. Veillez donc à mettre en œuvre la dénormalisation sans nuire à la convivialité de votre application.
Conseils pour la dénormalisation des bases de données
Comme vous pouvez le constater, la dénormalisation est un processus sérieux qui nécessite beaucoup d’efforts et de compétences. Si vous voulez dénormaliser des bases de données sans problème, suivez ces conseils utiles :
- Au lieu d’essayer de dénormaliser toute la base de données tout de suite, concentrez-vous sur des parties particulières que vous voulez accélérer.
- Faites de votre mieux pour apprendre vraiment bien la conception logique de votre application afin de comprendre quelles parties de votre système sont susceptibles d’être affectées par la dénormalisation.
- Analysez la fréquence à laquelle les données sont modifiées dans votre application ; si les données changent trop souvent, maintenir l’intégrité de votre base de données après la dénormalisation pourrait devenir un véritable problème.
- Regardez de près quelles parties de votre application ont des problèmes de performance ; souvent, vous pouvez accélérer votre application en affinant les requêtes plutôt qu’en dénormalisant la base de données.
- Apprenez-en plus sur les techniques de stockage des données ; choisir les plus pertinentes peut vous aider à vous passer de la dénormalisation.
Pensées finales
Vous devriez toujours commencer par construire une base de données normalisée propre et performante. Ce n’est que si vous avez besoin que votre base de données soit plus performante pour des tâches particulières (comme le reporting) que vous devez opter pour la dénormalisation. Si vous dénormalisez, soyez prudent et veillez à documenter toutes les modifications que vous apportez à la base de données.
Avant de vous lancer dans la dénormalisation, posez-vous les questions suivantes :
- Mon système peut-il atteindre des performances suffisantes sans dénormalisation ?
- Les performances de ma base de données pourraient-elles devenir inacceptables après que je l’ai dénormalisée ?
- Mon système deviendra-t-il moins fiable ?
Si votre réponse à l’une de ces questions est oui, vous feriez mieux de vous passer de la dénormalisation car elle risque de s’avérer inefficace pour votre application. Si, toutefois, la dénormalisation est votre seule option, vous devez d’abord normaliser correctement la base de données, puis passer à sa dénormalisation, en suivant soigneusement et strictement les techniques que nous avons décrites dans cet article.
Pour plus d’informations sur les dernières tendances en matière de développement de logiciels, abonnez-vous à notre blog.
La dénormalisation n’est pas seulement un moyen d’améliorer l’efficacité de votre application, elle est aussi un moyen de la rendre plus fiable.