Ce billet couvre les bases d’Apache Parquet, qui est une brique importante de l’architecture big data. Pour en savoir plus sur la gestion des fichiers sur le stockage objet, consultez notre guide sur le partitionnement des données sur Amazon S3.
Lors de la conférence Amazon re:Invent de l’année dernière (quand les conférences réelles existaient encore), AWS a annoncé l’exportation de lacs de données – la possibilité de décharger le résultat d’une requête Redshift sur Amazon S3 au format Apache Parquet. Dans l’annonce, AWS décrit Parquet comme étant « 2x plus rapide à décharger et consommant jusqu’à 6x moins de stockage dans Amazon S3, comparé aux formats texte ». La conversion des données en formats colonnaires tels que Parquet ou ORC est également recommandée comme moyen d’améliorer les performances d’Amazon Athena.
Il est clair qu’Apache Parquet joue un rôle important dans les performances du système lorsqu’on travaille avec des lacs de données. Examinons de plus près ce qu’est réellement Parquet et pourquoi il est important pour le stockage et l’analyse des big data.
Les bases : Qu’est-ce qu’Apache Parquet ?
Apache Parquet est un format de fichier conçu pour prendre en charge le traitement rapide des données complexes, avec plusieurs caractéristiques notables :
1. Columnar : Contrairement aux formats basés sur les lignes tels que CSV ou Avro, Apache Parquet est orienté colonnes – ce qui signifie que les valeurs de chaque colonne du tableau sont stockées les unes à côté des autres, plutôt que celles de chaque enregistrement :
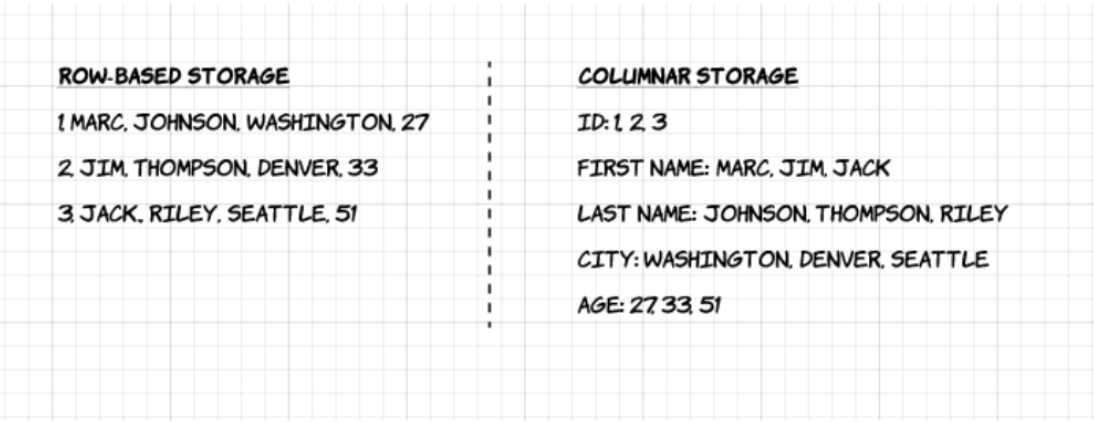
2. Open-source : Parquet est libre d’utilisation et open source sous la licence Apache Hadoop, et est compatible avec la plupart des frameworks de traitement de données Hadoop.
3. Autodescriptif : Dans Parquet, les métadonnées, y compris le schéma et la structure, sont intégrées à chaque fichier, ce qui en fait un format de fichier autodescriptif.
Avantages du stockage en colonnes Parquet
Les caractéristiques ci-dessus du format de fichier Apache Parquet créent plusieurs avantages distincts lorsqu’il s’agit de stocker et d’analyser de grands volumes de données. Examinons certains d’entre eux plus en profondeur.
Compression
La compression de fichiers est le fait de prendre un fichier et de le rendre plus petit. Dans Parquet, la compression est effectuée colonne par colonne et il est construit pour prendre en charge des options de compression flexibles et des schémas d’encodage extensibles par type de données – par exemple, un encodage différent peut être utilisé pour compresser les données d’entiers et de chaînes de caractères.
Les données Parquet peuvent être compressées en utilisant ces méthodes d’encodage :
- Encodage de dictionnaire : ceci est activé automatiquement et dynamiquement pour les données avec un petit nombre de valeurs uniques.
- Encodage de bits : Le stockage des nombres entiers se fait généralement avec 32 ou 64 bits dédiés par nombre entier. Cela permet un stockage plus efficace des petits entiers.
- Codage de longueur d’exécution (RLE) : lorsqu’une même valeur apparaît plusieurs fois, une seule valeur est stockée une fois avec le nombre d’occurrences. Parquet met en œuvre une version combinée du bit packing et du RLE, dans laquelle l’encodage bascule en fonction de celui qui produit les meilleurs résultats de compression.

Performance
Par opposition aux formats de fichiers basés sur les lignes comme CSV, Parquet est optimisé pour les performances. Lorsque vous exécutez des requêtes sur votre système de fichiers basé sur Parquet, vous pouvez vous concentrer uniquement sur les données pertinentes très rapidement. En outre, la quantité de données analysées sera beaucoup plus faible et entraînera une utilisation moindre des E/S. Pour comprendre cela, regardons un peu plus profondément comment les fichiers Parquet sont structurés.
Comme nous l’avons mentionné plus haut, Parquet est un format auto-décrit, donc chaque fichier contient à la fois des données et des métadonnées. Les fichiers Parquet sont composés de groupes de lignes, d’un en-tête et d’un pied de page. Chaque groupe de lignes contient des données provenant des mêmes colonnes. Les mêmes colonnes sont stockées ensemble dans chaque groupe de lignes:
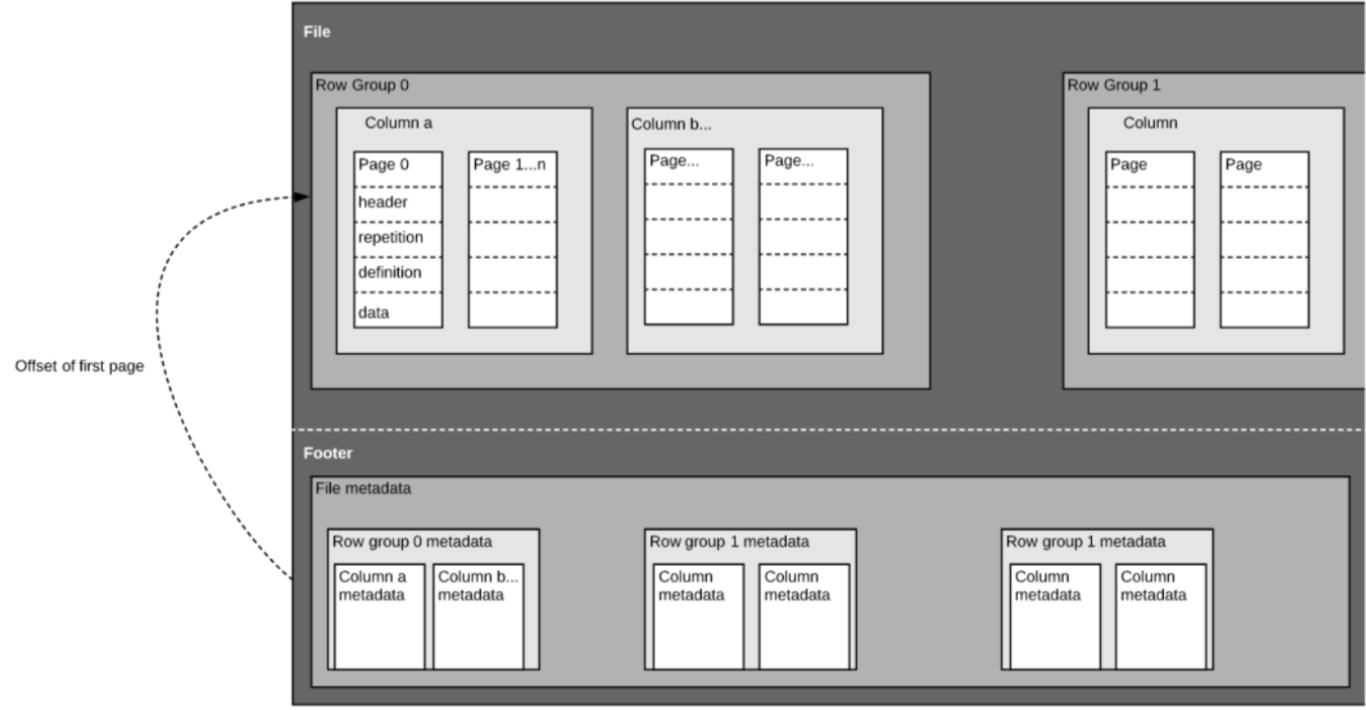
Cette structure est bien optimisée à la fois pour des performances de requête rapides, ainsi que pour des E/S faibles (minimisation de la quantité de données balayées). Par exemple, si vous avez une table avec 1000 colonnes, que vous n’allez généralement interroger qu’en utilisant un petit sous-ensemble de colonnes. L’utilisation de fichiers Parquet vous permettra d’extraire uniquement les colonnes requises et leurs valeurs, de les charger en mémoire et de répondre à la requête. Si un format de fichier basé sur les lignes, comme CSV, était utilisé, il aurait fallu charger l’intégralité de la table en mémoire, ce qui aurait entraîné une augmentation des E/S et une dégradation des performances.
Évolution du schéma
Lorsque l’on utilise des formats de fichiers en colonnes comme Parquet, les utilisateurs peuvent commencer par un schéma simple, et ajouter progressivement plus de colonnes au schéma selon les besoins. De cette façon, les utilisateurs peuvent se retrouver avec plusieurs fichiers Parquet avec des schémas différents mais mutuellement compatibles. Dans ces cas, Parquet prend en charge la fusion automatique des schémas entre ces fichiers.
Support open-source
Apache Parquet, comme mentionné ci-dessus, fait partie de l’écosystème Apache Hadoop qui est open-source et est constamment amélioré et soutenu par une forte communauté d’utilisateurs et de développeurs. En stockant vos données dans des formats ouverts, vous évitez le verrouillage des fournisseurs et augmentez votre flexibilité, par rapport aux formats de fichiers propriétaires utilisés par de nombreuses bases de données modernes à haute performance. Cela signifie que vous pouvez utiliser différents moteurs de requête tels qu’Amazon Athena, Qubole et Amazon Redshift Spectrum, au sein de la même architecture de lac de données.
Le stockage orienté colonne vs le stockage basé sur les lignes pour les requêtes analytiques
Les données sont souvent générées et plus facilement conceptualisées en lignes. Nous avons l’habitude de penser en termes de feuilles de calcul Excel, où nous pouvons voir toutes les données pertinentes pour un enregistrement spécifique dans une seule ligne soignée et organisée. Cependant, pour les requêtes analytiques à grande échelle, le stockage en colonnes présente des avantages significatifs en termes de coûts et de performances.
Des données complexes telles que des journaux et des flux d’événements devraient être représentées sous la forme d’un tableau comportant des centaines ou des milliers de colonnes, et plusieurs millions de lignes. Le stockage de ce tableau dans un format basé sur les lignes, tel que le CSV, signifierait :
- Les requêtes prendront plus de temps à s’exécuter car davantage de données doivent être analysées, plutôt que d’interroger uniquement le sous-ensemble de colonnes dont nous avons besoin pour répondre à une requête (ce qui nécessite généralement une agrégation basée sur une dimension ou une catégorie)
- Le stockage sera plus coûteux car les CSV ne sont pas compressés aussi efficacement que Parquet
Les formats en colonnes offrent une meilleure compression et de meilleures performances dès le départ, et vous permettent d’interroger les données verticalement – colonne par colonne.
Exemple : Parquet, CSV et Amazon Athena
Nous explorerons cet exemple de manière beaucoup plus approfondie lors de notre prochain webinaire avec Looker. Réservez votre place ici.
Pour démontrer l’impact du stockage Parquet en colonnes par rapport aux alternatives basées sur les lignes, regardons ce qui se passe lorsque vous utilisez Amazon Athena pour interroger des données stockées sur Amazon S3 dans les deux cas.
Utilisant Upsolver, nous avons ingéré un ensemble de données CSV de journaux de serveurs vers S3. Dans une architecture commune de lac de données AWS, Athena serait utilisé pour interroger les données directement depuis S3. Ces requêtes peuvent ensuite être visualisées à l’aide d’outils de visualisation de données interactifs tels que Tableau ou Looker.
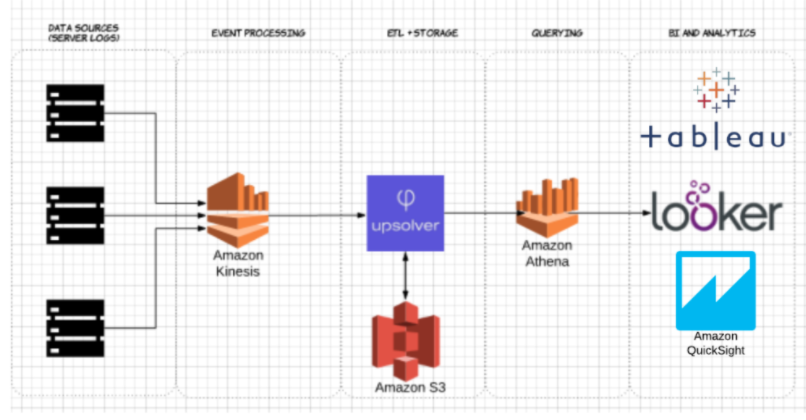
Nous avons testé Athena contre le même jeu de données stocké en CSV compressé, et en Apache Parquet.
Voici la requête que nous avons exécutée dans Athena :
SELECT tags_host AS host_id, AVG(fields_usage_active) as avg_usage
FROM server_usage
GROUPE PAR tags_host
HAVING AVG(fields_usage_active) > 0
LIMIT 10
Et les résultats :
| CSV | Parquet | Colonnes | |
| Temps de recherche (secondes) | 735 | 211 | 18 | Données numérisées (Go) | 372.2 | 10,29 | 18 |
- CSV compressés : Le CSV compressé comporte 18 colonnes et pèse 27 Go sur S3. Athena doit analyser l’ensemble du fichier CSV pour répondre à la requête, nous paierions donc pour 27 Go de données analysées. À des échelles plus élevées, cela aurait également un impact négatif sur les performances.
- Parquet : En convertissant nos fichiers CSV compressés en Apache Parquet, on se retrouve avec une quantité similaire de données dans S3. Cependant, comme Parquet est en colonnes, Athena doit lire uniquement les colonnes qui sont pertinentes pour la requête en cours d’exécution – un petit sous-ensemble des données. Dans ce cas, Athena a dû analyser 0,22 Go de données, donc au lieu de payer pour 27 Go de données analysées, nous ne payons que pour 0,22 Go.
L’utilisation de Parquet est-elle suffisante ?
L’utilisation de Parquet est un bon début ; cependant, l’optimisation des requêtes du lac de données ne s’arrête pas là. Vous avez souvent besoin de nettoyer, d’enrichir et de transformer les données, d’effectuer des jointures à haute cardinalité et de mettre en œuvre une foule de bonnes pratiques afin de garantir que les requêtes reçoivent systématiquement des réponses rapides et rentables.
Vous pouvez utiliser Upsolver pour simplifier votre pipeline ETL de lac de données, ingérer automatiquement les données sous forme de Parquet optimisé et transformer les données en continu avec des fonctions de type SQL ou Excel. Pour en savoir plus, programmez une démo juste ici.
Vous voulez en savoir plus sur l’optimisation de votre lac de données ? Consultez certaines de ces meilleures pratiques en matière de lac de données. Pour voir des benchmarks supplémentaires et apprendre les meilleures pratiques lors de la préparation des données pour Athena, rejoignez le prochain webinaire Upsolver + Looker juste ici.
.