T-SQLに慣れていない多くの人からよく聞かれる質問の一つに、文字列の中からデータを探し出し、それを抽出する方法があります。 データベースには多くの文字列が含まれているため、これは非常によくある質問です。 アプリケーションを使って文字列に情報を埋め込み、後で簡単に情報を削除できることを期待している人も多いと思います。 この記事では、SUBSTRING、CHARINDEX、PATINDEXを使用して、このデータを抽出する方法を見てみましょう。
これは基本に立ち返った記事であり、SQL Serverを初めて使用する開発者やDBAがスキルを向上させるのに役立つことを願っています。
Find the Consistent PO
ひとつの例として、請求書番号やPO番号があります。 このデータがテキスト フィールドに埋め込まれていて、後でフィールドからこの番号を抽出する必要があるのをよく見かけます。 これは、Customerテーブルのようなテーブルのフィールドに追加される一般的なデータのタイプです。
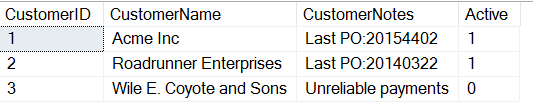
たとえば、次のような情報を含むテーブルがあったとします。
CREATE TABLE Customers( CustomerID INT, CustomerName VARCHAR(500), CustomerNotes VARCHAR(MAX), Active TINYINT);GOINSERT dbo.Customers ( CustomerID , CustomerName , CustomerNotes , Active ) VALUES ( 1, 'Acme Inc', 'Last PO:20154402', 1) , ( 2, 'Roadrunner Enterprises', 'Last PO:20140322', 1 ) , ( 3, 'Wile E. Coyote and Sons', 'Unreliable payments', 0)
データを見ると、誰かが重要な情報をノート フィールドに含めることにしたことがわかります。
必要なレポートのため、またはこのデータをより適切な場所にETLするために、このフィールドからPOを取得したい場合、T-SQLのSUBSTRING関数を使用することができます。
このケースでは、CustomerNotes フィールドの最初の 8 文字が、しばしば「Last PO: 」であることがわかります。 これにより、9文字目から始めて、次の8文字(POの長さ)を取得することができます。
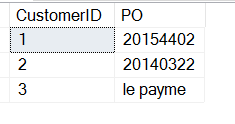
SELECT CustomerID , 'PO' = SUBSTRING(CustomerNotes, 9, 8)FROM dbo.Customers
これはPOを返しますが、他にもいくつかのデータを取得します。
心配ありません、これを簡単にフィルタリングすることができます (別の記事で説明します)。
一貫性のない PO
これまで見てきたデータでは、PO 番号は常に正しい場所にありました。 しかし、すべてのデータ入力者が同じように顧客と仕事をするわけではないと仮定しましょう。
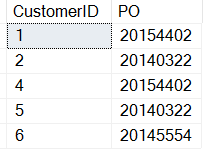
INSERT dbo.Customers ( CustomerID , CustomerName , CustomerNotes , Active ) VALUES ( 4, 'Beep Beep Enterprises', 'Remember their slogan: We go fast. Last PO:20154402', 1) , ( 5, 'Goldberg Supplies', 'Preferred. Last PO:20140322', 1 ) , ( 6, 'Bugs Deliveries', 'Fast Last PO:20145554', 0)
さて、上記のスクリプトを実行してみましょう。 次のようなデータが得られます:
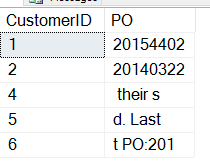
私たちが望むものではありません。 ここでの問題は、SUBSTRINGの開始位置が欲しいものではないことです。 PO番号の位置、おそらく「PO:」の位置で開始する必要があります。
いくつかの選択肢がありますが、CHARINDEXとPATINDEXを入力します。 どちらも、ある文字列を検索して、その中にある別の文字列を見つけることができます。 どちらでも構いませんが、テストデータでこれらがどのように機能するかをお見せしましょう。 このクエリを実行してみましょう:
SELECT CustomerID , CustomerNotes , 'Charindex_StartPO' = CHARINDEX('PO:', CustomerNotes) , 'Patindex_StartPO' = PATINDEX('%PO:%', CustomerNotes) , 'PO' = SUBSTRING(CustomerNotes, 9, 8) FROM dbo.Customers
そして、次のような結果が得られます:
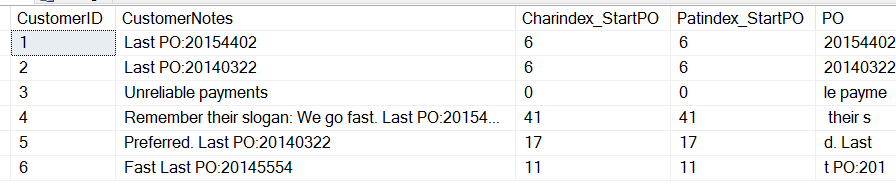
ここでは、両方の関数が同じ値、つまり「PO」の「P」の開始位置を返すことに注目してください。 いくつかの違いがあります。 CHARINDEXは、文字列の特定の位置から始めることができるのに対し、PATINDEXは、ワイルドカードを取ることができます。
ここではCHARINDEXを使用し、クエリを次のように変更します:
SELECT CustomerID , 'PO' = SUBSTRING(CustomerNotes, CHARINDEX('PO:', CustomerNotes), 8) FROM dbo.Customers WHERE customerNotes LIKE '%PO%';
これで次のようになりますが、これは私が望むものではありません。
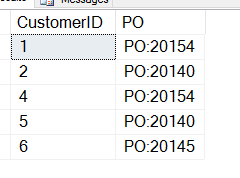
CHARINDEX が PO の開始位置を示すことを忘れていたので、この値に追加する必要があります。 以下は動作するクエリです:
SELECT CustomerID , 'PO' = SUBSTRING(CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3, 8) FROM dbo.Customers WHERE customerNotes LIKE '%PO%';
CHARINDEX 関数の結果に 3 を追加したことに注意してください。
The PO Grows
これは良いクエリのようですが、もう少しデータを追加することを想像してみましょう。
このケースでは、サイズが大きくなった発注書があります。 8文字のものもあれば、9文字のものもあります。 確かに、9文字だけでもいいのですが、10文字以上にすることも可能です。
このクエリを修正して、何ができるか見てみましょう。
SELECT CustomerID , CustomerNotes , 'Start of PO' = CHARINDEX('PO:', CustomerNotes)+3 , 'End of PO' = CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) , 'PO' = SUBSTRING(CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3, 8) FROM dbo.Customers WHERE customerNotes LIKE '%PO%';
結果は次のとおりです。
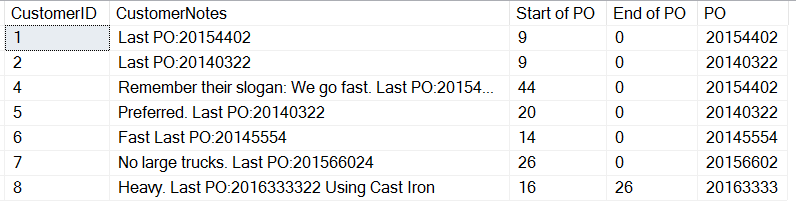
よく見ると、PO の後にテキストがある最後のエントリでは、CHARINDEX の結果が得られています。 これは、文字列を検索しているためで、エントリが見つからない場合は 0 を取得します。 POの後にスペースがあるのは顧客8だけです。
ここでは、2つの可能性があるので、CASE文を使うことができます。 1つのCASEは、スペースをチェックして、文字列内のスペースのインデックスを返します。 もう 1 つの CASE は、スペースが存在しない場合、文字列自体の長さを返します。 これにより、次のようなコードが得られます:
Update: 私の計算は間違っていました。
SELECT CustomerID , CustomerNotes , 'Start of PO' = CHARINDEX('PO:', CustomerNotes)+3 , 'End of PO' = CASE WHEN CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) = 0 THEN LEN(CustomerNotes) ELSE CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) END , 'Real End of PO' = CASE WHEN CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) = 0 THEN LEN(customernotes) ELSE CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) END - CHARINDEX('PO:', CustomerNotes) , 'PO' = SUBSTRING(CustomerNotes , CHARINDEX('PO:', CustomerNotes)+3 , CASE WHEN CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) = 0 THEN LEN(customernotes) ELSE CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) END - CHARINDEX('PO:', CustomerNotes) - 2 ) FROM dbo.Customers WHERE customerNotes LIKE '%PO%';
このコードを見ると、以前に使用した SUBSTRING コードと非常によく似ていますが、返す文字数を 8 という固定長にする代わりに、数式で値を返しています。 この式は結局、POの実質的な終わり(結果セットの5列目)とPOの始まりを表しています。
さて、計算してみると、各POの長さがわかります。 ほとんどの PO では、これは 8 文字 (「PO: 」の「P」の始まりの後の 11 文字) ですが、顧客 7 では 9 文字、顧客 8 では 11 文字です。
コード内の -3 を疑問に思う方もいらっしゃるかもしれませんが、算術のルールを覚えておけば、実際に PO 番号の先頭を表す量にマイナスを通しています。 例えば、「test PO: 201530444.New Test」のようにすることもできます。 New test」のようにすることもできますが、そうすると私たちのコードに問題が生じます。
この記事は、私が現実世界で解決しなければならなかったいくつかの文字列抽出の問題から生まれたもので、この種の問題は実際に発生します。
ここで学んだテクニックと同様に、パフォーマンスへの影響を必ず評価してください。 大規模なテスト データに対してコードを実行し、このテクニックが他のテクニックと比べてどの程度機能するかを判断してください。 本番のテーブルよりも大きなスケールのデータを生成するために、集計テーブルを使用することをお勧めします。
文字列操作は、SQL Server では計算量が多いため、コードを本番システムに展開する前に、選択の影響を理解しておく必要があります。