Harvard Business Reviewの記事で「データサイエンティスト」が「21世紀の最もセクシーな仕事」に選ばれて以来、機械学習を学ぶことへの関心が急上昇しています。 しかし、これから機械学習を始めようとしている方には、少し敷居が高いかもしれません。 そこで、初心者に適した機械学習のアルゴリズムについて、絶大な人気を誇る記事を再編集しました。
(この記事は元々、KDNuggetsにThe 10 Algorithms Machine Learning Engineers Need to Knowとして掲載されました。 許可を得て再掲しており、最終更新日は2019年です)
この投稿は、初心者を対象にしています。 データサイエンスや機械学習の経験がある方は、scikit-learnを使ってPythonで機械学習を行うことについてのより詳細なチュートリアルや、ここから始まる機械学習コースに興味があるかもしれません。 データサイエンス」と「機械学習」の違いがよくわからないという方は、こちらの記事を参考にしてみてください。機械学習とデータサイエンス – 何が違うのか?
機械学習アルゴリズムは、人間が介在しなくても、データから学習し、経験から改善することができるプログラムです。 学習タスクには、入力を出力にマッピングする関数の学習、ラベルのないデータの隠れた構造の学習、または「インスタンスベースの学習」があり、新しいインスタンス(行)を、メモリに保存された学習データのインスタンスと比較することで、新しいインスタンスのクラスラベルを生成します。
Types of Machine Learning Algorithms
機械学習(ML)のアルゴリズムには3つの種類があります:
Supervised Learning Algorithms:
教師付き学習では、ラベル付きの学習データを用いて、入力変数(X)を出力変数(Y)に変換するマッピング関数を学習します。 つまり、次の式でfを解くのです。
これにより、新しい入力が与えられたときに、正確に出力を生成することができます。
ここでは、分類と回帰という2種類の教師付き学習について説明します。
分類は、出力変数がカテゴリーの形をしている場合に、与えられたサンプルの結果を予測するために使用されます。 分類モデルは、入力データを見て、「病気」や「健康」などのラベルを予測しようとします。
回帰は、出力変数が実数値の形をしている場合に、与えられたサンプルの結果を予測するために使用されます。
回帰モデルは、入力データを処理して、降雨量や人の身長などを予測します。
このブログで取り上げた最初の5つのアルゴリズム、線形回帰、ロジスティック回帰、CART、ナイーブ・ベイズ、K-Nearest Neighbors(KNN)は、教師付き学習の例です。
アンサンブルも教師付き学習の一種です。 個々には弱い複数の機械学習モデルの予測を組み合わせて、新しいサンプルに対してより正確な予測を行うことを意味します。
教師なし学習アルゴリズム:
教師なし学習モデルは、入力変数(X)のみがあり、対応する出力変数がない場合に使用されます。
ここでは、3種類の教師なし学習について説明します。
Associationは、コレクション内のアイテムの共起の確率を発見するために使用されます。 これはマーケットバスケット分析に広く使われています。
クラスタリングは、同じクラスタ内のオブジェクトが他のクラスタのオブジェクトよりも互いに似ているように、サンプルをグループ化するために使用されます。
次元削減は、重要な情報を確実に伝えながら、データセットの変数の数を減らすために使用されます。 次元削減は、特徴抽出法と特徴選択法を用いて行うことができます。 特徴選択では、元の変数のサブセットを選択します。 特徴抽出法は、高次元空間から低次元空間へのデータ変換を行う。 例
ここで取り上げているApriori、K-means、PCAなどのアルゴリズム6~8は、教師なし学習の例です。
強化学習:
強化学習は機械学習アルゴリズムの一種であり、報酬を最大化する行動を学習することで、エージェントが現在の状態に基づいて次の最適な行動を決定することができます。
強化アルゴリズムは、通常、試行錯誤しながら最適な行動を学習していきます。例えば、プレイヤーが特定の時間に特定の場所に移動してポイントを獲得する必要があるビデオゲームを想像してみてください。
機械学習アルゴリズムの人気を測る
この10個のアルゴリズムはどこで入手したのでしょうか? このようなリストは、本質的に主観的なものです。 このような研究では、最も人気のあるデータ マイニング アルゴリズムの 10 種類を数値化していますが、それでも調査回答者の主観的な回答に頼っており、通常は高度な学術的実践者です。 例えば、上記のリンク先の研究では、調査対象者は、ACM KDD Innovation Award、IEEE ICDM Research Contributions Awardの受賞者、KDD ’06、ICDM ’06、SDM ’06のプログラム委員、ICDM ’06の145名の参加者でした。
この記事で紹介するトップ10のアルゴリズムは、機械学習の初心者を念頭に置いて選んだものです。 これらは主に、私がムンバイ大学でコンピュータ工学の学士号を取得した際に「Data Warehousing and Mining」(DWM)コースで学んだアルゴリズムです。
早速ですが、初心者向けの機械学習アルゴリズムのトップ10をご紹介します。 線形回帰
機械学習では、出力変数(y)を決定するために使用される入力変数(x)のセットがあります。 入力変数と出力変数の間には関係があります。

線形回帰では、入力変数(x)と出力変数(y)の関係は、y = a + bxという形の方程式で表されます。
図1は、あるデータセットのxとyの値をプロットしたものです。 目標は、ほとんどの点に最も近い直線をフィットさせることです。
2.ロジスティック回帰
線形回帰の予測は連続的な値 (例: 降雨量 (cm))であり、ロジスティック回帰の予測は離散的な値 (例: 学生の合否) です。
ロジスティック回帰は、y=0または1のデータセット(1がデフォルトクラスを表す)である二値分類に最も適しています。 例えば、ある事象が発生するかどうかを予測する場合、その事象が発生する(1とする)か、発生しない(0とする)かの2つの可能性しかありません。
ロジスティック回帰は、ロジスティック関数h(x)=1/(1+ex)と呼ばれる変換関数にちなんで名付けられました。
ロジスティック回帰では、出力はデフォルトクラスの確率の形をしています(出力が直接生成される線形回帰とは異なります)。 確率であるため、出力は0~1の範囲にあります。
この出力 (y-値) は、ロジスティック関数 h(x)=1/ (1 + e^ -x) を使用して、x-値を対数変換することで生成されます。
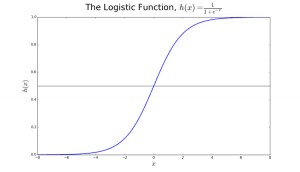
図2: ロジスティック回帰で腫瘍が悪性か良性かを判断する。 確率h(x)>=0.5の場合、悪性と分類される。 出典
図2では、腫瘍が悪性かどうかを判断するために、デフォルトの変数はy = 1(腫瘍 = 悪性)とします。 x変数は、腫瘍の大きさなど、腫瘍の測定値である可能性があります。 図に示すように、ロジスティック関数は、データセットのさまざまなインスタンスのx値を0から1の範囲に変換します。確率が0.5のしきい値(水平線で示す)を超えた場合、腫瘍は悪性と分類されます。
ロジスティック回帰式 P(x) = e ^ (b0 +b1x) / (1 + e(b0 + b1x)) は ln(p(x) / 1-p(x)) = b0 + b1x に変換できます。
ロジスティック回帰の目的は、予測された結果と実際の結果の間の誤差を最小にするような係数b0とb1の値をトレーニングデータから見つけることです。
3.CART
分類回帰木(CART)は決定木の1つの実装です。
分類回帰木の非終端ノードはルートノードとインターナルノードです。
分類木と回帰木の非終端ノードは、ルートノードとインターナルノードで、終端ノードはリーフノードです。 各非終端ノードは1つの入力変数(x)とその変数上の分岐点を表し、葉ノードは出力変数(y)を表します。
下の図3の決定木は、ある人がスポーツカーとミニバンのどちらを買うかを、その人の年齢と配偶者の有無によって分類しています。 もし、その人が30歳以上で結婚していなければ、次のようにツリーを歩きます。 30歳以上か」 ->>> いいえ。
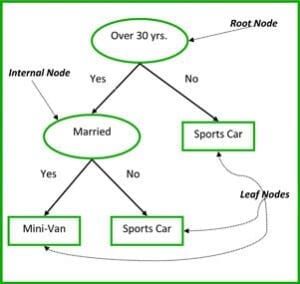
図3:決定木のパーツ。 出典
4.ナイーブ・ベイズ
ある事象が発生する確率を、別の事象が既に発生していることを前提に計算するには、ベイズの定理を使います。
where:
- P(h|d)=事後確率。 データdが与えられたときに仮説hが真である確率で、P(h|d)=P(d1|h)P(d2|h)….P(dn|h)P(d)
- P(d|h)=尤度。 仮説hが真であった場合のデータdの確率。
- P(h)=Class prior probabilityの略。 仮説hが真である確率(データに関係なく)
- P(d) = Predictor prior probability。 データの確率(仮説に関わらず)
このアルゴリズムは、すべての変数が互いに独立していると仮定しているため、「ナイーブ」と呼ばれていますが、これは実世界の例ではナイーブな仮定です。
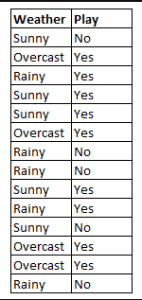
図 4: Naive Bayes を使用して、変数「天気」を使用して「プレイ」の状態を予測します。
図4を例にすると、weather = ‘sunny’の場合、どのような結果になるでしょうか。
変数weather = ‘sunny’の値が与えられたとき、結果play = ‘yes’ or ‘no’を決定するために、P(yes|sunny)とP(no|sunny)を計算し、より高い確率で結果を選択します。
->P(yes|sunny)=(P(sunny|yes) * P(yes)) / P(sunny) = (3/9 * 9/14 ) / (5/14) = 0.60
-> P(no|sunny)= (P(sunny|no) * P(no)) P(no|sunny)=(P(sunny|no) * P(no)) / P(sunny) = (2/5 * 5/14 ) / (5/14) = 0.40
つまり、天気=「晴れ」の場合、結果はプレイ=「はい」となります。
5. KNN
K-Nearest Neighborsアルゴリズムは、データセットをトレーニングセットとテストセットに分割するのではなく、データセット全体をトレーニングセットとして使用します。
新しいデータ インスタンスに結果が必要な場合、KNN アルゴリズムはデータ セット全体を調べて、新しいインスタンスに最も近い k 個のインスタンス、または新しいレコードに最も似ている k 個のインスタンスを見つけ、結果の平均 (回帰問題の場合) または分類問題の場合はモード (最も頻度の高いクラス) を出力します。
インスタンス間の類似性は、ユークリッド距離やハミング距離などの尺度を用いて計算されます。
教師なし学習アルゴリズム
6.Apriori
Aprioriアルゴリズムは、トランザクションデータベースにおいて、頻出するアイテムセットをマイニングし、アソシエーションルールを生成するために使用されます。 これは、データベース内で頻繁に共起する商品の組み合わせをチェックする、マーケットバスケット分析でよく使われます。 一般的に、「ある人が商品Xを購入したら、その人は商品Yを購入する」という連想ルールを次のように記述します。 X -> Y.
例:ある人がミルクと砂糖を購入した場合、その人はコーヒー パウダーを購入する可能性が高い。 これを連想ルールの形で書くと次のようになります。 {milk,sugar} -> コーヒーパウダー。
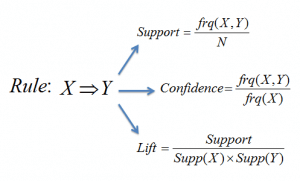
図5:連想ルールX->Yのサポート、信頼度、リフトの数式です。
サポート尺度は、頻出アイテムセット生成時に考慮すべきアイテムセット候補の数を剪定するのに役立ちます。 このサポートメジャーはAprioriの原則に導かれています。
7.K-means
K-meansは、類似したデータをクラスターにグループ化する反復アルゴリズムです。
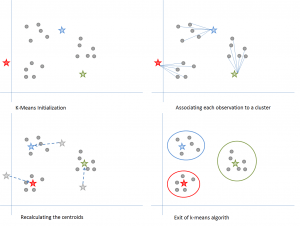
図6: K-meansアルゴリズムのステップ。 出典
以下のように動作します。
まず、kの値を選択します。 そして、各データポイントを3つのクラスターのいずれかにランダムに割り当てます。 それぞれのクラスターについて、クラスター・セントロイドを計算します。
次に、各点を最も近いクラスタ・セントロイドに再割り当てします。 上の図では、上の5つのポイントは青いセントロイドを持つクラスタに割り当てられました。 同じ手順で、赤と緑のセントロイドを持つクラスタに点を割り当てます。
そして、新しいクラスタのセントロイドを計算します。
最後に、あるクラスターから別のクラスターへのポイントの切り替えがなくなるまで、ステップ2-3を繰り返します。
8.PCA
主成分分析 (Principal Component Analysis: PCA) は、変数の数を減らすことで、データの探索と視覚化を容易にするために使用されます。 これは、データの最大分散を「主成分」と呼ばれる軸を持つ新しい座標系に取り込むことによって行われます。
各成分は、元の変数の線形結合であり、互いに直交しています。
第1主成分は、データの変動が最大となる方向を捉えます。
第1主成分は、データの変動性が最大となる方向を捉え、第2主成分は、データの残りの変動性を捉えますが、第1主成分とは無相関の変数を持ちます。
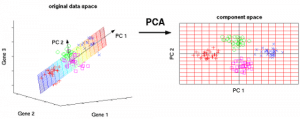
図7:3つの元の変数(遺伝子)は、主成分(PC)と呼ばれる2つの新しい変数に削減されます。 出典
アンサンブル学習手法:
アンサンブルとは、複数の学習者(分類器)の結果を、投票や平均化によって、より良い結果になるように組み合わせることです。 投票は分類の際に、平均化は回帰の際に使用されます。
アンサンブルのアルゴリズムには3種類あります。
アンサンブルのアルゴリズムには、Bagging、Boosting、Stackingの3種類があります。 ここでは「スタッキング」を取り上げませんが、詳しい説明が必要な場合は、Kaggleからのしっかりとした紹介があります。
9. Bagging with Random Forests
Bagging の最初のステップは、Bootstrap Sampling 法を使用して作成されたデータ セットで複数のモデルを作成することです。 Bootstrap Samplingでは、生成された各トレーニングセットは、元のデータセットからのランダムなサブサンプルで構成されています。
これらのトレーニングセットはそれぞれ元のデータセットと同じサイズですが、一部のレコードは複数回繰り返し、一部のレコードは全く現れません。 そして、元のデータセット全体をテストセットとして使用します。
Baggingの第2段階は、生成された異なるトレーニングセットに同じアルゴリズムを使用して複数のモデルを作成することです。 決定木では、各ノードはエラーを最小化する最適な特徴に基づいて分割されますが、ランダムフォレストでは、最適な分割を構築するために特徴のランダムな選択を行います。 ランダムにする理由は、バギングを行っても、決定木が分割する最適な特徴を選択すると、最終的には似たような構造になり、相関性のある予測結果が得られます。
各分割ポイントで検索される特徴の数は、ランダムフォレスト アルゴリズムのパラメータとして指定されます。
つまり、ランダムフォレストを使用したバギングでは、各ツリーはレコードのランダムなサンプルを使用して構築され、各分割は予測因子のランダムなサンプルを使用して構築されることになります。 AdaBoostによるブースティング
AdaboostはAdaptive Boostingの略です。 Baggingは、各モデルが独立して構築されるため、並列アンサンブルとなります。 一方、ブースティングは逐次的なアンサンブルで、各モデルは前のモデルの誤分類を修正することに基づいて構築されます。
バギングでは主に「単純投票」が行われ、各分類器が投票して最終的な結果(並列モデルの過半数によって決定されるもの)を得ます。ブースティングでは「加重投票」が行われ、各分類器が投票して最終的な結果(過半数によって決定されるもの)を得ますが、順次モデルは前のモデルの誤分類されたインスタンスに大きな重みを割り当てて構築されます。
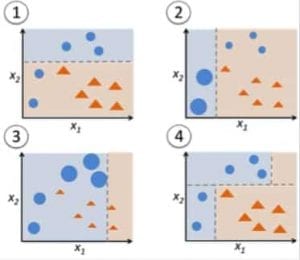
図9: 決定木に対するAdaboost。 出典
図9のステップ1、2、3では、決定スタンプと呼ばれる弱い学習者(1つの入力特徴の値のみに基づいて予測を行う1レベルの決定木、根がすぐに葉につながっている決定木)が登場します。
弱い学習者を構築するプロセスは、ユーザーが定義した数の弱い学習者が構築されるか、トレーニング中にそれ以上の改善が見られなくなるまで続きます。
まず、1つの入力変数に対する決定を行うために、1つの決定木の切り株から始めます。
データポイントのサイズは、それらを円形または三角形に分類するために、等しい重みを適用したことを示しています。 決定スタンプは、これらの点を分類するために、上半分に水平線を生成しました。 誤って三角形と予測された円が2つあることがわかります。
次に、別の入力変数に対する決定を行うために、別の決定木のスタンプに移動します。
前のステップで誤って分類された 2 つの円のサイズが、残りのポイントよりも大きいことがわかります。
より高い重みを割り当てた結果、これらの2つの円は、左の垂直線によって正しく分類されました。
高い重みを割り当てた結果、これらの 2 つの円は、左の垂直線によって正しく分類されました。
3つ目は、別の入力変数に対する決定を行うために、別の決定木のスタンプを訓練します。
前のステップで誤って分類された3つの円は、残りのデータ ポイントよりも大きくなっています。
第 4 に、決定木を結合します。
前の 3 つのモデルからのセパレータを結合し、このモデルからの複雑なルールが、個々の弱い学習者のどれと比較しても、データ ポイントを正しく分類していることを観察しました。
結論:
まとめると、データ サイエンスで最も重要な機械学習アルゴリズムのいくつかをカバーしました。
編集部注:この記事はKDNuggetsに掲載されたものを、許可を得て再掲載しています。

Reena Shawは、あらゆるデータ、スパイシーな食べ物、アルフレッド・ヒッチコックの愛好家です。 彼女への連絡は、右の「続きを読む」ボタンのリンクからどうぞ。 Linkedin||@ReenaShawLegacy
。