この記事では、ビッグデータアーキテクチャの重要な構成要素であるApache Parquetの基本について説明します。
昨年のAmazon re:Inventカンファレンス(現実のカンファレンスがまだ存在していた時代)で、AWSはデータレイクエクスポートを発表しました。これはRedshiftのクエリの結果をApache Parquet形式でAmazon S3にアンロードする機能です。 発表の中でAWSは、Parquetについて「テキスト形式に比べて、アンロードが2倍速く、Amazon S3でのストレージ消費量が最大6倍少ない」と説明しています。 また、Amazon Athenaのパフォーマンスを向上させる手段として、データをParquetやORCなどの列挙型フォーマットに変換することも推奨されています。
データレイクを扱う上で、Apache Parquetがシステムのパフォーマンスに重要な役割を果たしていることは明らかです。 ここでは、Parquetとは何か、なぜビッグデータの保存と分析に重要なのかを詳しく見ていきましょう。
基礎知識。
Apache Parquetとは?
Apache Parquetは、複雑なデータの高速なデータ処理をサポートするために設計されたファイルフォーマットで、以下のような特徴があります:
1. 列指向。 CSV や Avro のような行ベースのフォーマットとは異なり、Apache Parquet は列指向です。つまり、テーブルの各列の値は、各レコードの値ではなく、隣り合って保存されます。 Parquetは、Apache Hadoopライセンスに基づいて無料で使用できるオープンソースであり、ほとんどのHadoopデータ処理フレームワークと互換性があります。
3:
Parquet Columnar Storageの利点
Apache Parquetファイルフォーマットの上記の特徴は、大量のデータを保存して分析する際に、いくつかの明確な利点を生み出します。
圧縮
ファイルの圧縮とは、ファイルを小さくすることです。
Parquet のデータは、以下のエンコーディング方法を使用して圧縮することができます。
- 辞書エンコーディング: これは、少数のユニークな値を持つデータに対して自動的かつ動的に有効になります
- ビットパッキング。 整数の格納は、通常、1つの整数につき32ビットまたは64ビットの専用ビットで行われます。 これにより、小さな整数をより効率的に保存することができます。
- Run length encoding (RLE): 同じ値が複数回出現する場合、単一の値を出現回数とともに1回だけ保存します。

パフォーマンス
CSVのような行ベースのファイルフォーマットとは対照的に、Parquetはパフォーマンスのために最適化されています。 Parquetベースのファイルシステムでクエリを実行する際には、関連するデータのみに非常に素早く集中することができます。 さらに、スキャンされるデータの量は非常に少なく、I/O使用量も少なくて済みます。
前述したように、Parquetは自己記述式のフォーマットなので、各ファイルにはデータとメタデータの両方が含まれています。 Parquetファイルは、行グループ、ヘッダー、フッターで構成されています。 各行グループには、同じカラムのデータが含まれています。 同じ列は各行グループにまとめて格納されています。
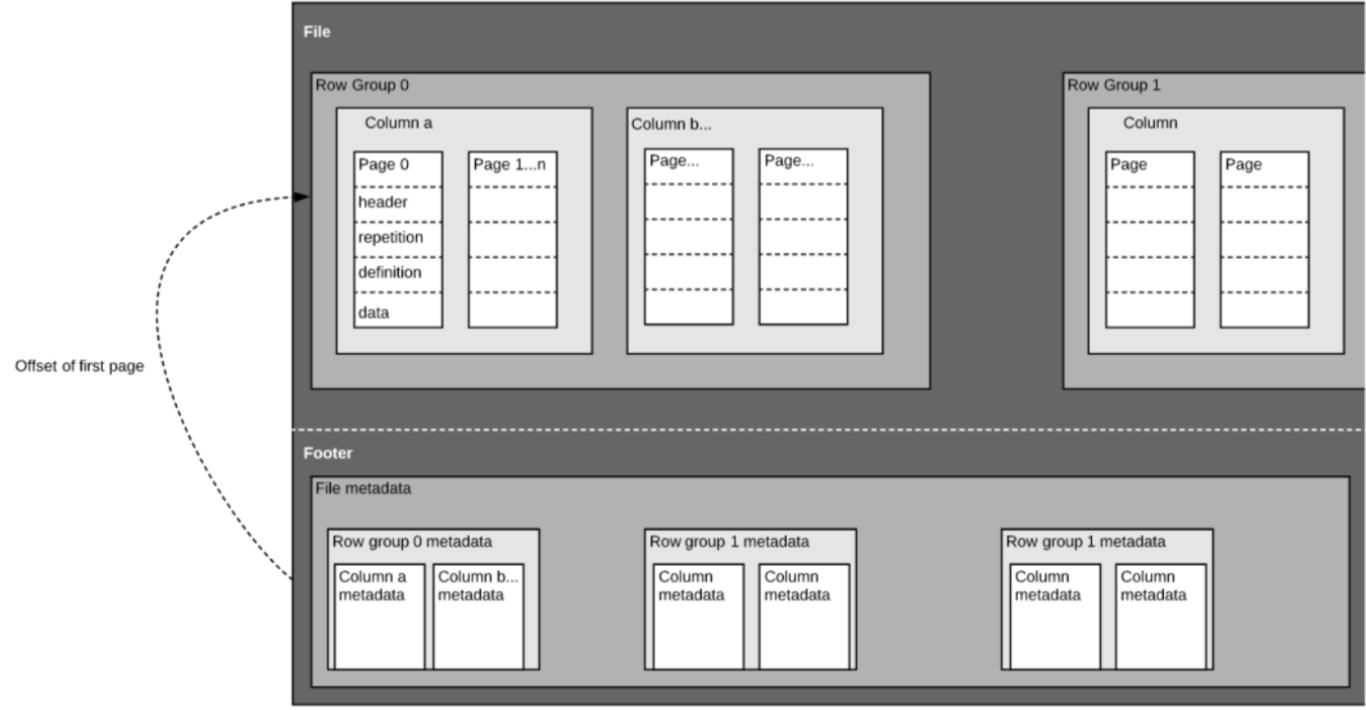
この構造は、高速なクエリパフォーマンスと低I/O(スキャンされるデータ量の最小化)の両方によく最適化されています。 例えば、1000個のカラムを持つテーブルがあり、通常はカラムの小さなサブセットを使ってのみクエリを実行するとします。 Parquetファイルを使用すれば、必要な列とその値だけを取得し、それらをメモリにロードしてクエリに応答することができます。
スキーマの進化
Parquet のような列指向のファイル形式を使用する場合、ユーザーはシンプルなスキーマから始めて、必要に応じて徐々にスキーマに列を追加していくことができます。 このようにして、異なるが相互に互換性のあるスキーマを持つ複数のParquetファイルを作成することができます。
オープンソースのサポート
Apache Parquetは、前述のようにオープンソースであるApache Hadoopエコシステムの一部であり、ユーザーと開発者の強力なコミュニティによって常に改善され、バックアップされています。 オープンなフォーマットでデータを保存することは、最近の高性能データベースの多くで使用されている独自のファイルフォーマットと比較して、ベンダーロックインを回避し、柔軟性を高めることにつながります。 これは、Amazon Athena、Qubole、Amazon Redshift Spectrumなどのさまざまなクエリエンジンを、同じデータレイクアーキテクチャ内で使用できることを意味します。
分析クエリのための列指向 vs 行ベースのストレージ
データは多くの場合、行で生成され、より簡単に概念化されます。 私たちは、特定のレコードに関連するすべてのデータを1つのきれいに整理された行で見ることができる、Excelスプレッドシートの観点から考えることに慣れています。
ログやイベントストリームなどの複雑なデータは、数百から数千の列と数百万の行を持つテーブルとして表現する必要があります。 このテーブルをCSVなどの行ベースのフォーマットで保存すると、以下のようになります。
- クエリに答えるために必要な列のサブセットのみをクエリするのではなく、より多くのデータをスキャンする必要があるため、クエリの実行に時間がかかります(通常、次元やカテゴリに基づいて集約する必要があります)
- CSV は Parquet ほど効率的に圧縮されないため、ストレージにコストがかかります
列形式は、より優れた圧縮とパフォーマンスの向上をすぐに実現し、データを列ごとに垂直方向にクエリすることができます。
例を示します。
例: Parquet、CSV、Amazon Athena
この例は、Looker と共同で開催する予定のウェビナーでさらに詳しく説明します。
列指向のParquetストレージが行指向のものと比べてどのような影響があるかを示すために、Amazon Athenaを使用して両方のケースでAmazon S3に保存されたデータを照会するとどうなるかを見てみましょう。
Upsolverを使用して、サーバーログのCSVデータセットをS3に取り込みました。 一般的なAWSデータレイクのアーキテクチャでは、Athenaを使用してS3から直接データをクエリします。
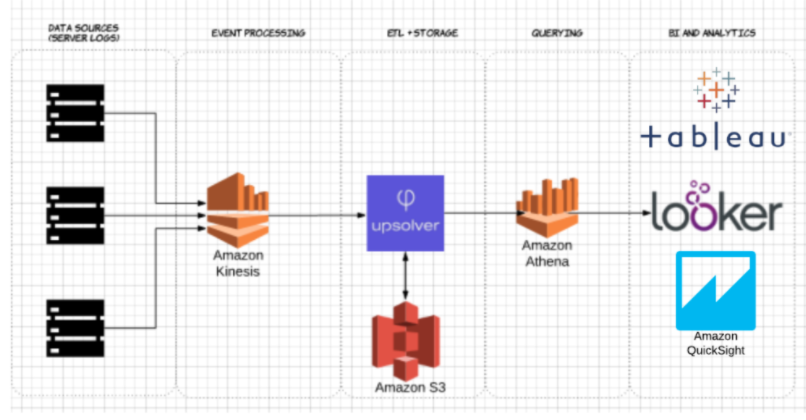
圧縮されたCSVとApache Parquetとして保存された同じデータセットに対してAthenaをテストしました。
これがAthenaで実行したクエリです。
SELECT tags_host AS host_id, AVG(fields_usage_active) as avg_usage
FROM server_usage
GROUP BY tags_host
HAVING AVG(fields_usage_active) > 0
LIMIT 10
そして、結果です。
| CSV | Parquet | Columns | |
| Query Time (second) | 735 | 211 | 18 |
| Data scanned (GB) | 372.2 | 10.29 | 18 |
- 圧縮されたCSVです。 圧縮されたCSVは18列で、S3上で27GBの重さがあります。 Athenaはクエリに答えるためにCSVファイル全体をスキャンする必要があるため、スキャンされた27GBのデータに対して料金を支払うことになります。 より高いスケールでは、これはパフォーマンスにも悪影響を及ぼします。
- Parquet。 圧縮されたCSVファイルをApache Parquetに変換すると、S3には同じような量のデータができあがります。 しかし、Parquetは列指向なので、Athenaは実行中のクエリに関連する列、つまりデータの小さなサブセットだけを読み取る必要があります。 この場合、Athenaは0.22GBのデータをスキャンする必要があったため、27GBのデータをスキャンするために料金を支払うのではなく、0.22GBに対してのみ料金を支払うことになります。
Parquetの使用だけでは不十分?
Parquetの使用は良いスタートですが、データレイククエリの最適化はそれだけでは終わりません。
Upsolverを使用すると、データレイクのETLパイプラインを簡素化し、最適化されたParquetとしてデータを自動的に取り込み、SQLやExcelのような関数でストリーミングデータを変換することができます。
データレイクの最適化についてもっと知りたいですか? データレイクのベスト・プラクティスをご覧ください。 その他のベンチマークやAthena向けのデータ準備に関するベストプラクティスについては、こちらのUpsolver + Lookerウェビナーにご参加ください
。