Interesowanie uczeniem maszynowym wzrosło w ostatnich latach, odkąd artykuł Harvard Business Review nazwał 'Data Scientist' 'Najseksowniejszą pracą XXI wieku'. Ale jeśli dopiero zaczynasz swoją przygodę z uczeniem maszynowym, może być trochę trudno się w nim odnaleźć. Dlatego właśnie wznawiamy nasz niezwykle popularny post o dobrych algorytmach uczenia maszynowego dla początkujących.
(Ten post został pierwotnie opublikowany na KDNuggets jako The 10 Algorithms Machine Learning Engineers Need to Know. Został ponownie umieszczony za zgodą i został ostatnio zaktualizowany w 2019 roku).
Ten post jest skierowany do początkujących. Jeśli masz już jakieś doświadczenie w nauce o danych i uczeniu maszynowym, możesz być bardziej zainteresowany tym bardziej dogłębnym samouczkiem na temat robienia uczenia maszynowego w Pythonie z scikit-learn, lub w naszych kursach uczenia maszynowego, które zaczynają się tutaj. Jeśli nie rozumiesz jeszcze różnic między „nauką o danych” a „uczeniem maszynowym”, ten artykuł oferuje dobre wyjaśnienie: uczenie maszynowe i nauka o danych – co je różni?
Algorytmy uczenia maszynowego to programy, które mogą uczyć się na podstawie danych i doskonalić się na podstawie doświadczenia, bez interwencji człowieka. Zadania uczenia się mogą obejmować uczenie się funkcji, która mapuje dane wejściowe na dane wyjściowe, uczenie się ukrytej struktury w nieoznakowanych danych lub 'uczenie oparte na instancji', gdzie etykieta klasy jest tworzona dla nowej instancji poprzez porównanie nowej instancji (wiersza) z instancjami z danych szkoleniowych, które były przechowywane w pamięci. Uczenie oparte na instancjach nie tworzy abstrakcji z konkretnych instancji.
Typy algorytmów uczenia maszynowego
Istnieją 3 typy algorytmów uczenia maszynowego (ML):
Algorytmy uczenia nadzorowanego:
Uczenie nadzorowane wykorzystuje etykietowane dane treningowe do nauki funkcji odwzorowania, która przekształca zmienne wejściowe (X) w zmienną wyjściową (Y). Innymi słowy, rozwiązuje f w następującym równaniu:
To pozwala nam dokładnie generować dane wyjściowe, gdy otrzymujemy nowe dane wejściowe.
Porozmawiamy o dwóch typach uczenia nadzorowanego: klasyfikacji i regresji.
Klasyfikacja jest używana do przewidywania wyniku danej próbki, gdy zmienna wyjściowa ma postać kategorii. Model klasyfikacyjny może spojrzeć na dane wejściowe i spróbować przewidzieć etykiety takie jak „chory” lub „zdrowy”
Regresja jest używana do przewidywania wyniku danej próbki, gdy zmienna wyjściowa ma postać wartości rzeczywistych. Na przykład, model regresji może przetwarzać dane wejściowe, aby przewidzieć ilość opadów, wzrost osoby, itp.
Pierwsze 5 algorytmów, które omówimy na tym blogu – Regresja liniowa, Regresja logistyczna, CART, Naïve-Bayes i K-Nearest Neighbors (KNN) – są przykładami uczenia nadzorowanego.
Ensembling jest innym rodzajem uczenia nadzorowanego. Oznacza to połączenie przewidywań wielu modeli uczenia maszynowego, które są indywidualnie słabe, w celu uzyskania dokładniejszych przewidywań dla nowej próbki. Algorytmy 9 i 10 z tego artykułu – Bagging z Random Forests, Boosting z XGBoost – są przykładami technik zespołowych.
Algorytmy uczenia nienadzorowanego:
Modele uczenia nienadzorowanego są używane, gdy mamy tylko zmienne wejściowe (X) i żadnych odpowiadających im zmiennych wyjściowych. Używają one nieoznakowanych danych treningowych do modelowania struktury danych.
Porozmawiamy o trzech typach uczenia bez nadzoru:
Asocjacja jest używana do odkrywania prawdopodobieństwa współwystępowania elementów w kolekcji. Jest ona szeroko wykorzystywana w analizie koszyków rynkowych. Na przykład, model asocjacyjny może być użyty do odkrycia, że jeśli klient kupuje chleb, to jest 80% prawdopodobieństwa, że kupi również jajka.
Klastrowanie jest używane do grupowania próbek w taki sposób, że obiekty w tym samym klastrze są bardziej podobne do siebie niż do obiektów z innego klastra.
Redukcja wymiarowości jest używana do zmniejszenia liczby zmiennych w zbiorze danych przy zapewnieniu, że ważne informacje są nadal przekazywane. Redukcja wymiarowości może być przeprowadzona przy użyciu metod ekstrakcji cech (Feature Extraction) oraz selekcji cech (Feature Selection). Selekcja cech wybiera podzbiór oryginalnych zmiennych. Ekstrakcja cech wykonuje transformację danych z przestrzeni wysokowymiarowej do przestrzeni niskowymiarowej. Przykład: Algorytm PCA jest podejściem typu Feature Extraction.
Algorytmy 6-8, które tu omawiamy – Apriori, K-means, PCA – są przykładami uczenia nienadzorowanego.
Uczenie wzmacniające:
Uczenie wzmacniające jest rodzajem algorytmu uczenia maszynowego, który pozwala agentowi zdecydować o najlepszym następnym działaniu w oparciu o jego aktualny stan poprzez uczenie się zachowań, które zmaksymalizują nagrodę.
Algorytmy wzmacniające zazwyczaj uczą się optymalnych działań metodą prób i błędów. Wyobraźmy sobie, na przykład, grę wideo, w której gracz musi poruszać się do pewnych miejsc w określonym czasie, aby zdobyć punkty. Algorytm wzmacniający grający w tę grę zacząłby od losowego poruszania się, ale z czasem, poprzez próby i błędy, nauczyłby się, gdzie i kiedy należy poruszać się postacią w grze, aby zmaksymalizować liczbę punktów.
Oszacowanie popularności algorytmów uczenia maszynowego
Skąd wzięliśmy te dziesięć algorytmów? Każda taka lista będzie z natury subiektywna. Badania, takie jak te, określiły ilościowo 10 najpopularniejszych algorytmów eksploracji danych, ale nadal polegają na subiektywnych odpowiedziach ankietowanych, zazwyczaj zaawansowanych praktyków akademickich. Na przykład, w badaniu linkowanym powyżej, osoby ankietowane to zwycięzcy ACM KDD Innovation Award, IEEE ICDM Research Contributions Award; członkowie komitetu programowego KDD ’06, ICDM ’06 i SDM ’06; oraz 145 uczestników ICDM ’06.
10 najpopularniejszych algorytmów wymienionych w tym poście zostało wybranych z myślą o początkujących adeptach uczenia maszynowego. Są to przede wszystkim algorytmy, których nauczyłem się na kursie 'Data Warehousing and Mining' (DWM) podczas studiów licencjackich z inżynierii komputerowej na Uniwersytecie w Bombaju. Ostatnie 2 algorytmy (metody zespołowe) zamieściłem szczególnie dlatego, że są one często wykorzystywane do wygrywania konkursów Kaggle.
Bez dalszych ceregieli, 10 najlepszych algorytmów uczenia maszynowego dla początkujących:
1. Regresja liniowa
W uczeniu maszynowym, mamy zestaw zmiennych wejściowych (x), które są używane do określenia zmiennej wyjściowej (y). Istnieje związek pomiędzy zmiennymi wejściowymi a zmienną wyjściową. Celem ML jest ilościowe określenie tej zależności.

W regresji liniowej związek między zmiennymi wejściowymi (x) i zmienną wyjściową (y) jest wyrażony jako równanie w postaci y = a + bx. Zatem celem regresji liniowej jest znalezienie wartości współczynników a i b. Tutaj a jest punktem przecięcia, a b jest nachyleniem linii.
Rysunek 1 pokazuje wykreślone wartości x i y dla zestawu danych. Celem jest dopasowanie linii, która jest najbliższa większości punktów. To zmniejszyłoby odległość („błąd”) między wartością y punktu danych a linią.
2. Regresja logistyczna
Prognozy regresji liniowej są wartościami ciągłymi (np. opady deszczu w cm), prognozy regresji logistycznej są wartościami dyskretnymi (np, czy student zdał/nie zdał) po zastosowaniu funkcji transformacji.
Regresja logistyczna najlepiej nadaje się do klasyfikacji binarnej: zestawów danych, gdzie y = 0 lub 1, gdzie 1 oznacza klasę domyślną. Na przykład, w przewidywaniu, czy zdarzenie wystąpi, czy nie, istnieją tylko dwie możliwości: że wystąpi (co oznaczamy jako 1) lub że nie wystąpi (0). Jeśli więc przewidywalibyśmy, czy pacjent jest chory, oznaczalibyśmy chorych pacjentów za pomocą wartości 1 w naszym zbiorze danych.
Regresja logistyczna nosi nazwę funkcji transformacji, którą wykorzystuje, zwanej funkcją logistyczną h(x)= 1/ (1 + ex). Tworzy ona krzywą w kształcie litery S.
W regresji logistycznej dane wyjściowe przyjmują postać prawdopodobieństw klasy domyślnej (w przeciwieństwie do regresji liniowej, gdzie dane wyjściowe są bezpośrednio produkowane). Ponieważ jest to prawdopodobieństwo, dane wyjściowe leżą w zakresie 0-1. Tak więc, na przykład, jeśli próbujemy przewidzieć, czy pacjenci są chorzy, wiemy już, że chorzy pacjenci są oznaczani jako 1, więc jeśli nasz algorytm przypisuje pacjentowi wynik 0.98, uważa on, że jest całkiem prawdopodobne, że pacjent jest chory.
Ta wartość wyjściowa (wartość y) jest generowana przez przekształcenie logiczne wartości x, przy użyciu funkcji logistycznej h(x)= 1/ (1 + e^ -x) . Następnie stosowany jest próg, aby zmusić to prawdopodobieństwo do klasyfikacji binarnej.
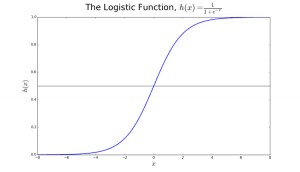
Wykres 2: Regresja logistyczna do określenia, czy guz jest złośliwy czy łagodny. Klasyfikowany jako złośliwy, jeśli prawdopodobieństwo h(x)>= 0,5. Źródło
Na rysunku 2, aby określić, czy guz jest złośliwy czy nie, domyślną zmienną jest y = 1 (guz = złośliwy). Zmienna x może być miarą guza, taką jak rozmiar guza. Jak pokazano na rysunku, funkcja logistyczna przekształca wartości x różnych instancji zbioru danych w zakres od 0 do 1. Jeśli prawdopodobieństwo przekroczy próg 0,5 (pokazany linią poziomą), guz jest klasyfikowany jako złośliwy.
Równanie regresji logistycznej P(x) = e ^ (b0 +b1x) / (1 + e(b0 + b1x)) można przekształcić w ln(p(x) / 1-p(x)) = b0 + b1x.
Celem regresji logistycznej jest wykorzystanie danych treningowych do znalezienia takich wartości współczynników b0 i b1, które zminimalizują błąd między przewidywanym wynikiem a rzeczywistym wynikiem. Współczynniki te są szacowane przy użyciu techniki Maximum Likelihood Estimation.
3. CART
Drzewa klasyfikacyjne i regresyjne (CART) są jedną z implementacji drzew decyzyjnych.
Węzłami nieterminalnymi drzew klasyfikacyjnych i regresyjnych są węzeł główny i węzeł wewnętrzny. Węzły końcowe to węzły liści. Każdy węzeł nieterminalny reprezentuje pojedynczą zmienną wejściową (x) i punkt podziału na tej zmiennej; węzły liści reprezentują zmienną wyjściową (y). Model jest używany do przewidywań w następujący sposób: należy przejść przez podziały drzewa, aby dotrzeć do węzła liścia i wyprowadzić wartość obecną w węźle liścia.
Drzewo decyzyjne na rysunku 3 poniżej klasyfikuje, czy dana osoba kupi samochód sportowy czy minivana w zależności od jej wieku i stanu cywilnego. Jeśli osoba ma ponad 30 lat i nie jest w związku małżeńskim, to przechodzimy przez drzewo w następujący sposób : 'powyżej 30 lat?' -> tak -> 'żonaty?' -> nie. Stąd, model wypisuje samochód sportowy.
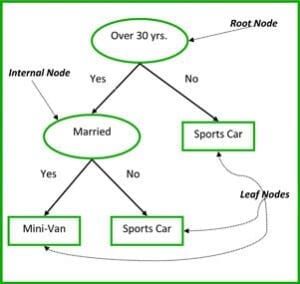
Rysunek 3: Części drzewa decyzyjnego. Źródło
4. Naiwny Bayes
Aby obliczyć prawdopodobieństwo wystąpienia jakiegoś zdarzenia, biorąc pod uwagę, że inne zdarzenie już wystąpiło, korzystamy z Twierdzenia Bayesa. Aby obliczyć prawdopodobieństwo prawdziwości hipotezy(h), biorąc pod uwagę naszą wcześniejszą wiedzę(d), używamy Twierdzenia Bayesa w następujący sposób:
gdzie:
- P(h|d) = Prawdopodobieństwo potomne. Prawdopodobieństwo, że hipoteza h jest prawdziwa, biorąc pod uwagę dane d, gdzie P(h|d)= P(d1| h) P(d2| h)….P(dn| h) P(d)
- P(d|h) = Prawdopodobieństwo. Prawdopodobieństwo wystąpienia danych d przy założeniu, że hipoteza h jest prawdziwa.
- P(h) = Wcześniejsze prawdopodobieństwo klasy. Prawdopodobieństwo, że hipoteza h jest prawdziwa (niezależnie od danych)
- P(d) = Prawdopodobieństwo predyktora. Prawdopodobieństwo danych (niezależnie od hipotezy)
Algorytm ten nazywany jest „naiwnym”, ponieważ zakłada, że wszystkie zmienne są od siebie niezależne, co jest naiwnym założeniem w rzeczywistych przykładach.
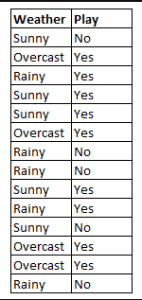
Rysunek 4: Użycie Naive Bayes do przewidywania stanu 'gry' przy użyciu zmiennej 'pogoda'.
Na przykładzie rysunku 4, jaki jest wynik, jeśli pogoda = 'słoneczna'?
Aby określić wynik play = 'tak' lub 'nie' biorąc pod uwagę wartość zmiennej weather = 'sunny', oblicz P(yes|sunny) i P(no|sunny) i wybierz wynik z większym prawdopodobieństwem.
->P(yes|sunny)= (P(sunny|yes) * P(yes)) / P(sunny) = (3/9 * 9/14 ) / (5/14) = 0,60
-> P(no|sunny)= (P(sunny|no) * P(no)) / P(sunny) = (2/5 * 5/14 ) / (5/14) = 0.40
Tak więc, jeśli pogoda = 'słoneczna', wynikiem jest gra = 'tak'.
5. KNN
Algorytm K-Nearest Neighbors wykorzystuje cały zbiór danych jako zbiór treningowy, zamiast dzielić zbiór danych na zbiór treningowy i testowy.
Gdy wynik jest wymagany dla nowej instancji danych, algorytm KNN przechodzi przez cały zbiór danych, aby znaleźć k-najbliższych instancji do nowej instancji, lub k liczbę instancji najbardziej podobnych do nowego rekordu, a następnie wyprowadza średnią wyników (dla problemu regresji) lub tryb (najczęstszą klasę) dla problemu klasyfikacji. Wartość k jest określana przez użytkownika.
Podobieństwo między instancjami jest obliczane przy użyciu miar takich jak odległość euklidesowa i odległość Hamminga.
Algorytmy uczenia nienadzorowanego
6. Apriori
Algorytm Apriori jest używany w transakcyjnej bazie danych do wydobywania zbiorów częstych elementów, a następnie generowania reguł asocjacyjnych. Jest on popularnie wykorzystywany w analizie koszyków rynkowych, gdzie sprawdza się kombinacje produktów, które często występują w bazie danych. W ogólności, regułę asocjacyjną dla „jeśli osoba kupuje pozycję X, to kupuje pozycję Y” zapisujemy jako : X -> Y.
Przykład: jeśli osoba kupuje mleko i cukier, to prawdopodobnie kupi też kawę w proszku. Można to zapisać w postaci reguły asocjacyjnej jako: {mleko,cukier} -> kawa w proszku. Reguły asocjacyjne są generowane po przekroczeniu progu wsparcia i pewności.
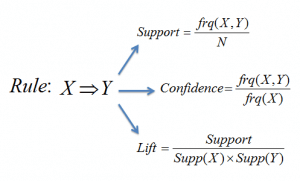
Figura 5: Formuły dla wsparcia, pewności i zniesienia dla reguły asocjacyjnej X->Y.
Pomiar wsparcia pomaga uciąć liczbę kandydujących zbiorów elementów, które należy rozważyć podczas generowania zbiorów elementów częstych. Ta miara wsparcia jest kierowana przez zasadę Apriori. Zasada Apriori mówi, że jeśli zbiór elementów jest częsty, to wszystkie jego podzbiory również muszą być częste.
7. K-means
K-means jest iteracyjnym algorytmem, który grupuje podobne dane w klastry.Oblicza on centroidy k klastrów i przypisuje punkt danych do tego klastra, który ma najmniejszą odległość między jego centroidem a punktem danych.
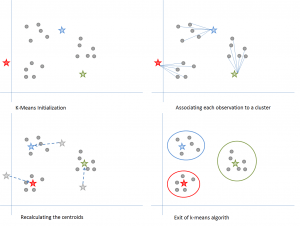
Rysunek 6: Etapy algorytmu K-means. Źródło
Oto jak to działa:
Zaczynamy od wybrania wartości k. Tutaj powiedzmy, że k = 3. Następnie losowo przypisujemy każdy punkt danych do dowolnego z 3 klastrów. Obliczamy centroidy klastrów dla każdego z nich. Czerwone, niebieskie i zielone gwiazdy oznaczają centroidy dla każdego z 3 klastrów.
Następnie przypisz każdy punkt do najbliższego centroidu klastra. Na powyższym rysunku górne 5 punktów zostało przypisanych do klastra z niebieską centroidą. W ten sam sposób przypisz punkty do klastrów z centroidami czerwonym i zielonym.
Następnie oblicz centroidy dla nowych klastrów. Stare centroidy to szare gwiazdy, nowe centroidy to czerwone, zielone i niebieskie gwiazdy.
Na koniec powtórz kroki 2-3, aż nie będzie przełączania punktów z jednego klastra do drugiego. Gdy nie ma przełączania przez 2 kolejne kroki, zakończ działanie algorytmu K-means.
8. PCA
Principal Component Analysis (PCA) jest używana do ułatwienia eksploracji i wizualizacji danych poprzez zmniejszenie liczby zmiennych. Odbywa się to poprzez uchwycenie maksymalnej wariancji w danych w nowym układzie współrzędnych z osiami zwanymi „głównymi składowymi”.
Każda składowa jest liniową kombinacją oryginalnych zmiennych i jest ortogonalna względem siebie. Ortogonalność między składowymi wskazuje, że korelacja między tymi składowymi wynosi zero.
Pierwsza główna składowa wychwytuje kierunek maksymalnej zmienności danych. Druga główna składowa wychwytuje pozostałą wariancję w danych, ale ma zmienne nieskorelowane z pierwszą składową. Podobnie, wszystkie kolejne główne składowe (PC3, PC4 i tak dalej) wychwytują pozostałą wariancję, będąc jednocześnie nieskorelowane z poprzednią składową.
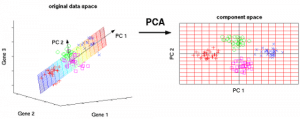
Ryc. 7: 3 oryginalne zmienne (geny) są zredukowane do 2 nowych zmiennych określanych jako główne składowe (PC’s). Źródło
Ensemble learning techniques:
Ensembling oznacza łączenie wyników wielu uczących (klasyfikatorów) w celu uzyskania lepszych wyników, poprzez głosowanie lub uśrednianie. Głosowanie jest używane podczas klasyfikacji, a uśrednianie podczas regresji. Idea jest taka, że zespoły uczące dają lepsze wyniki niż pojedyncze uczące.
Istnieją 3 rodzaje algorytmów ensemblingu: Bagging, Boosting i Stacking. Nie będziemy tutaj omawiać 'układania', ale jeśli chciałbyś uzyskać szczegółowe wyjaśnienie, oto solidne wprowadzenie z Kaggle.
9. Bagging z Random Forests
Pierwszym krokiem w baggingu jest stworzenie wielu modeli z zestawów danych stworzonych przy użyciu metody Bootstrap Sampling. W Bootstrap Sampling, każdy wygenerowany zbiór treningowy składa się z losowych podpróbek z oryginalnego zbioru danych.
Każdy z tych zbiorów treningowych ma taki sam rozmiar jak oryginalny zbiór danych, ale niektóre rekordy powtarzają się wielokrotnie, a niektóre w ogóle się nie pojawiają. Następnie cały oryginalny zestaw danych jest używany jako zestaw testowy. Tak więc, jeśli rozmiar oryginalnego zbioru danych wynosi N, to rozmiar każdego wygenerowanego zbioru treningowego wynosi również N, z liczbą unikalnych rekordów wynoszącą około (2N/3); rozmiar zbioru testowego wynosi również N.
Drugim krokiem w baggingu jest utworzenie wielu modeli poprzez użycie tego samego algorytmu na różnych wygenerowanych zbiorach treningowych.
To jest miejsce, w którym wkraczają Lasy Losowe. W przeciwieństwie do drzewa decyzyjnego, gdzie każdy węzeł jest dzielony na najlepszą cechę, która minimalizuje błąd, w Lasach Losowych wybieramy losowo cechy do skonstruowania najlepszego podziału. Powodem losowości jest to, że nawet z workowaniem, kiedy drzewa decyzyjne wybierają najlepszą cechę do podziału, kończą z podobną strukturą i skorelowanymi przewidywaniami. Ale bagging po podziale na losowy podzbiór cech oznacza mniejszą korelację między przewidywaniami z drzew cząstkowych.
Liczba cech do przeszukania w każdym punkcie podziału jest określona jako parametr algorytmu Random Forest.
Tak więc, w baggingu z Random Forest, każde drzewo jest skonstruowane przy użyciu losowej próbki rekordów i każdy podział jest skonstruowany przy użyciu losowej próbki predyktorów.
10. Boostowanie z AdaBoost
Adaboost to skrót od Adaptive Boosting. Bagging jest równoległym zespołem, ponieważ każdy model jest budowany niezależnie. Z drugiej strony, boosting jest zespołem sekwencyjnym, gdzie każdy model jest budowany w oparciu o korektę błędnych klasyfikacji poprzedniego modelu.
Bagging polega głównie na „prostym głosowaniu”, gdzie każdy klasyfikator głosuje, aby uzyskać ostateczny wynik – taki, który jest określony przez większość równoległych modeli; boosting polega na „ważonym głosowaniu”, gdzie każdy klasyfikator głosuje, aby uzyskać ostateczny wynik, który jest określony przez większość – ale modele sekwencyjne zostały zbudowane poprzez przypisanie większych wag błędnie sklasyfikowanym instancjom poprzednich modeli.
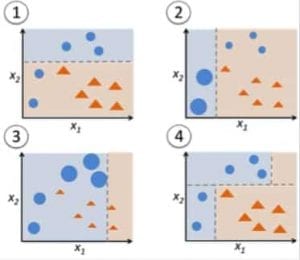
Rysunek 9: Adaboost dla drzewa decyzyjnego. Źródło
Na Rysunku 9, kroki 1, 2, 3 dotyczą słabego uczącego zwanego pniakiem decyzyjnym (1-poziomowe drzewo decyzyjne tworzące predykcję na podstawie wartości tylko 1 cechy wejściowej; drzewo decyzyjne, którego korzeń jest bezpośrednio połączony z liśćmi).
Proces konstruowania słabych uczących jest kontynuowany do momentu skonstruowania zdefiniowanej przez użytkownika liczby słabych uczących lub do momentu, w którym nie ma dalszej poprawy podczas treningu. Krok 4 łączy 3 pniaki decyzyjne z poprzednich modeli (a więc posiada 3 reguły podziału w drzewie decyzyjnym).
Początkowo rozpoczynamy od jednego pniaka decyzyjnego, aby podjąć decyzję dotyczącą jednej zmiennej wejściowej.
Wielkość punktów danych pokazuje, że zastosowaliśmy równe wagi, aby zaklasyfikować je jako koło lub trójkąt. Pniak decyzyjny wygenerował poziomą linię w górnej połowie, aby sklasyfikować te punkty. Widzimy, że dwa koła zostały błędnie zaklasyfikowane jako trójkąty. W związku z tym, przypiszemy tym dwóm okręgom wyższe wagi i zastosujemy kolejny pniak decyzyjny.
Po drugie, przejdź do innego pniaka drzewa decyzyjnego, aby podjąć decyzję dotyczącą innej zmiennej wejściowej.
Zauważamy, że rozmiar dwóch błędnie sklasyfikowanych okręgów z poprzedniego kroku jest większy niż pozostałych punktów. W wyniku przypisania wyższych wag, te dwa okręgi zostały poprawnie sklasyfikowane przez pionową linię po lewej stronie. Ale to teraz spowodowało błędną klasyfikację trzech okręgów na górze. Dlatego przypiszemy wyższe wagi tym trzem okręgom na górze i zastosujemy kolejny pień decyzyjny.
Po trzecie, wytrenuj kolejny pień drzewa decyzyjnego, aby podjąć decyzję dotyczącą innej zmiennej wejściowej.
Trzy błędnie sklasyfikowane okręgi z poprzedniego kroku są większe niż reszta punktów danych. Teraz, pionowa linia w prawo została wygenerowana, aby sklasyfikować okręgi i trójkąty.
Po czwarte, połącz pniaki decyzyjne.
Połączyliśmy separatory z 3 poprzednich modeli i obserwujemy, że złożona reguła z tego modelu klasyfikuje punkty danych poprawnie w porównaniu do każdego z pojedynczych słabych uczących.
Podsumowanie:
Podsumowując, omówiliśmy kilka najważniejszych algorytmów uczenia maszynowego dla nauki o danych:
- 5 technik uczenia nadzorowanego – Regresja liniowa, Regresja logistyczna, CART, Naïve Bayes, KNN.
- 3 techniki uczenia nienadzorowanego – Apriori, K-means, PCA.
- 2 techniki grupowania – Bagging z Random Forests, Boosting z XGBoost.
Nota redaktora: Ten artykuł został pierwotnie opublikowany na KDNuggets i został ponownie umieszczony za zgodą. Autorka Reena Shaw jest programistką i dziennikarką data science.

Reena Shaw jest miłośniczką wszystkich rzeczy związanych z danymi, pikantnego jedzenia i Alfreda Hitchcocka. Skontaktuj się z nią, korzystając z łączy w przycisku 'Czytaj więcej' po prawej stronie: Linkedin| |@ReenaShawLegacy