Ten post omawia podstawy Apache Parquet, który jest ważnym elementem architektury big data. Aby dowiedzieć się więcej o zarządzaniu plikami na obiektowym magazynie, sprawdź nasz przewodnik po partycjonowaniu danych na Amazon S3.
W zeszłorocznej konferencji Amazon re:Invent (kiedy prawdziwe konferencje były jeszcze czymś takim), AWS ogłosiło eksport jeziora danych – możliwość wyładowania wyniku zapytania Redshift do Amazon S3 w formacie Apache Parquet. W ogłoszeniu, AWS opisał Parquet jako „2x szybszy do rozładowania i zużywa do 6x mniej pamięci w Amazon S3, w porównaniu do formatów tekstowych”. Konwersja danych do formatów kolumnowych, takich jak Parquet lub ORC, jest również zalecana jako sposób na poprawę wydajności Amazon Athena.
Jasno widać, że Apache Parquet odgrywa ważną rolę w wydajności systemu podczas pracy z jeziorami danych. Przyjrzyjmy się bliżej, czym właściwie jest Parquet i dlaczego ma znaczenie dla przechowywania i analizy dużych danych.
Podstawy: Co to jest Apache Parquet?
Apache Parquet jest formatem plików zaprojektowanym do wspierania szybkiego przetwarzania złożonych danych, z kilkoma godnymi uwagi cechami:
1. Kolumnowy: W przeciwieństwie do formatów opartych na wierszach, takich jak CSV lub Avro, Apache Parquet jest zorientowany na kolumny – co oznacza, że wartości każdej kolumny tabeli są przechowywane obok siebie, a nie w każdym rekordzie:
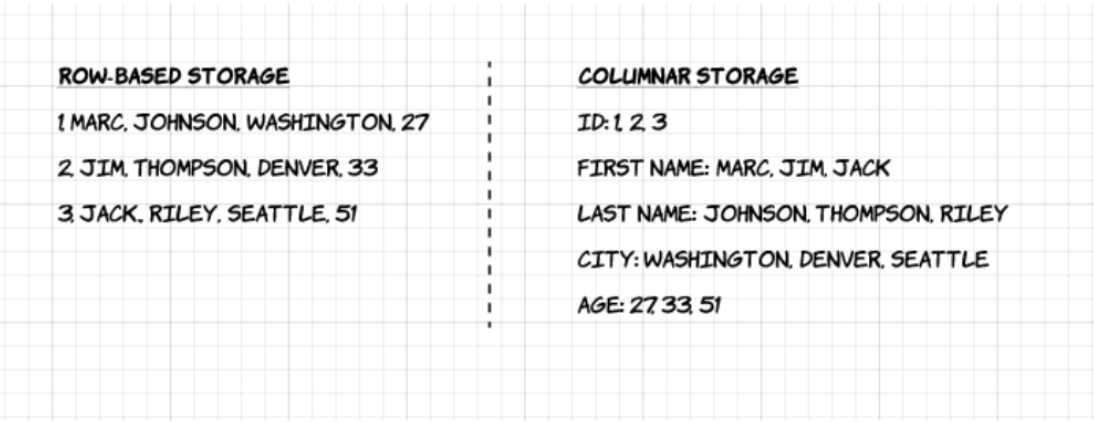
2. Open-source: Parquet jest darmowy w użyciu i open source na licencji Apache Hadoop, i jest kompatybilny z większością frameworków przetwarzania danych Hadoop.
3. Samoopisujący się: W Parquet metadane, w tym schemat i struktura, są osadzone w każdym pliku, co czyni go samoopisującym się formatem plików.
Wady Parquet Columnar Storage
Powyższe cechy formatu plików Apache Parquet tworzą kilka wyraźnych korzyści, jeśli chodzi o przechowywanie i analizowanie dużych ilości danych. Przyjrzyjmy się niektórym z nich bardziej szczegółowo.
Kompresja
Kompresja plików jest aktem wzięcia pliku i uczynienia go mniejszym. W Parquet, kompresja jest wykonywana kolumna po kolumnie i jest zbudowana tak, aby wspierać elastyczne opcje kompresji i rozszerzalne schematy kodowania dla każdego typu danych – np. różne kodowania mogą być używane do kompresji liczb całkowitych i łańcuchów znaków.
Dane Parquet mogą być kompresowane przy użyciu następujących metod kodowania:
- Kodowanie słownikowe: jest włączane automatycznie i dynamicznie dla danych z małą liczbą unikalnych wartości.
- Pakowanie bitów: Przechowywanie liczb całkowitych jest zwykle wykonywane z dedykowanymi 32 lub 64 bitami na liczbę całkowitą. Pozwala to na bardziej efektywne przechowywanie małych liczb całkowitych.
- Kodowanie długości przebiegu (RLE): gdy ta sama wartość występuje wiele razy, pojedyncza wartość jest przechowywana raz wraz z liczbą wystąpień. Parquet implementuje połączoną wersję kodowania bitowego i RLE, w której kodowanie zmienia się na podstawie tego, które daje najlepsze wyniki kompresji.

Wydajność
W przeciwieństwie do formatów plików opartych na wierszach jak CSV, Parquet jest zoptymalizowany pod kątem wydajności. Podczas wykonywania zapytań w systemie plików opartym na Parquet, można bardzo szybko skupić się tylko na istotnych danych. Co więcej, ilość skanowanych danych będzie znacznie mniejsza i spowoduje mniejsze zużycie operacji wejścia/wyjścia. Aby to zrozumieć, przyjrzyjmy się nieco głębiej temu, jak pliki Parquet są zbudowane.
Jak wspomnieliśmy powyżej, Parquet jest formatem samoopisującym się, więc każdy plik zawiera zarówno dane jak i metadane. Pliki Parquet składają się z grup wierszy, nagłówka i stopki. Każda grupa wierszy zawiera dane z tych samych kolumn. Te same kolumny są przechowywane razem w każdej grupie wierszy:
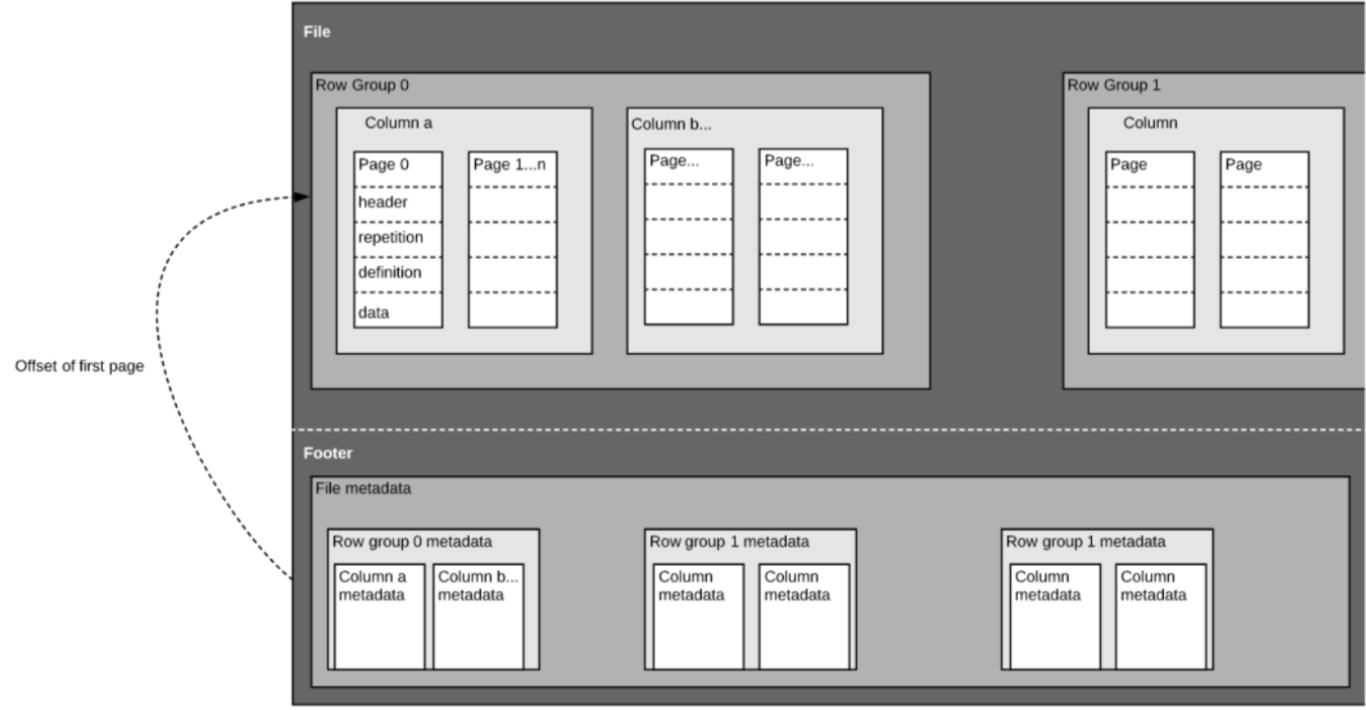
Ta struktura jest dobrze zoptymalizowana zarówno dla szybkiej wydajności zapytań, jak i niskiego I/O (minimalizacja ilości skanowanych danych). Na przykład, jeśli posiadasz tabelę z 1000 kolumn, które zazwyczaj będziesz odpytywał tylko przy użyciu małego podzbioru kolumn. Użycie plików Parquet pozwoli Ci pobrać tylko wymagane kolumny i ich wartości, załadować je do pamięci i odpowiedzieć na zapytanie. Jeśli użyty zostałby format pliku oparty na wierszach, taki jak CSV, cała tabela musiałaby zostać załadowana do pamięci, co skutkowałoby zwiększonym I/O i gorszą wydajnością.
Ewolucja schematu
Przy użyciu kolumnowych formatów plików, takich jak Parquet, użytkownicy mogą zacząć od prostego schematu i stopniowo dodawać kolejne kolumny do schematu w miarę potrzeb. W ten sposób użytkownicy mogą mieć wiele plików Parquet z różnymi, ale wzajemnie kompatybilnymi schematami. W takich przypadkach, Parquet wspiera automatyczne łączenie schematów pomiędzy tymi plikami.
Wsparcie open-source
Apache Parquet, jak wspomniano powyżej, jest częścią ekosystemu Apache Hadoop, który jest open-source i jest stale ulepszany i wspierany przez silną społeczność użytkowników i deweloperów. Przechowywanie danych w otwartych formatach oznacza, że unikasz uzależnienia od dostawcy i zwiększasz swoją elastyczność w porównaniu do zastrzeżonych formatów plików używanych przez wiele nowoczesnych, wysokowydajnych baz danych. Oznacza to, że możesz używać różnych silników zapytań, takich jak Amazon Athena, Qubole i Amazon Redshift Spectrum, w ramach tej samej architektury jeziora danych.
Column-oriented vs row based storage for analytic querying
Dane są często generowane i łatwiej konceptualizowane w wierszach. Jesteśmy przyzwyczajeni do myślenia w kategoriach arkusza kalkulacyjnego Excel, gdzie możemy zobaczyć wszystkie dane istotne dla konkretnego rekordu w jednym schludnym i zorganizowanym wierszu. Jednak w przypadku zapytań analitycznych na dużą skalę, przechowywanie danych w kolumnach ma znaczące zalety pod względem kosztów i wydajności.
Złożone dane, takie jak logi i strumienie zdarzeń, muszą być reprezentowane jako tabela z setkami lub tysiącami kolumn i wieloma milionami wierszy. Przechowywanie tej tabeli w formacie opartym na wierszach, takim jak CSV, oznaczałoby:
- Zapytania będą trwały dłużej, ponieważ więcej danych musi zostać przeskanowanych, zamiast tylko odpytywać podzbiór kolumn, których potrzebujemy, aby odpowiedzieć na zapytanie (co zazwyczaj wymaga agregacji na podstawie wymiaru lub kategorii)
- Przechowywanie będzie bardziej kosztowne, ponieważ CSV nie są kompresowane tak wydajnie jak Parquet
Formaty kolumnowe zapewniają lepszą kompresję i lepszą wydajność out-of-the-box, a także umożliwiają odpytywanie danych pionowo – kolumna po kolumnie.
Przykład: Parquet, CSV i Amazon Athena
Prezentujemy ten przykład znacznie dokładniej podczas naszego nadchodzącego webinarium z firmą Looker. Zapisz swoje miejsce tutaj.
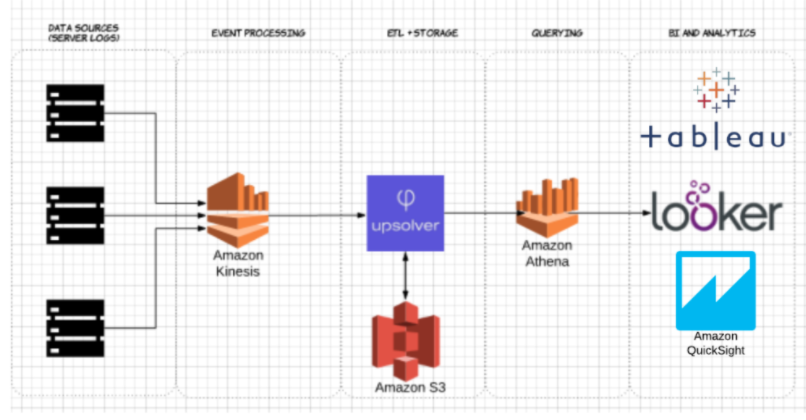
Aby zademonstrować wpływ kolumnowego przechowywania Parquet w porównaniu do alternatyw opartych na wierszach, spójrzmy na to, co dzieje się, gdy używasz Amazon Athena do zapytania o dane przechowywane na Amazon S3 w obu przypadkach.
Używając Upsolver, wprowadziliśmy zbiór danych CSV logów serwera do S3. W typowej architekturze AWS data lake, Athena zostałaby użyta do zapytania o dane bezpośrednio z S3. Zapytania te mogą być następnie wizualizowane za pomocą interaktywnych narzędzi do wizualizacji danych, takich jak Tableau czy Looker.
Testowaliśmy Athenę przeciwko temu samemu zbiorowi danych przechowywanemu jako skompresowane CSV oraz jako Apache Parquet.
To jest zapytanie, które uruchomiliśmy w Athenie:
SELECT tags_host AS host_id, AVG(fields_usage_active) as avg_usage
FROM server_usage
GROUP BY tags_host
HAVING AVG(fields_usage_active) > 0
LIMIT 10
I wyniki:
| CSV | Parkiet | Kolumny | |
| Czas zapytania (sekundy) | 735 | 211 | 18 |
| Skanowane dane (GB) | 372.2 | 10.29 | 18 |
- Skompresowane CSV: Skompresowany CSV ma 18 kolumn i waży 27 GB na S3. Athena musi przeskanować cały plik CSV, aby odpowiedzieć na zapytanie, więc zapłacilibyśmy za 27 GB zeskanowanych danych. Przy wyższych skalach miałoby to również negatywny wpływ na wydajność.
- Parquet: Konwertując nasze skompresowane pliki CSV do Apache Parquet, kończysz z podobną ilością danych w S3. Jednakże, ponieważ Parquet jest kolumnowy, Athena musi odczytać tylko te kolumny, które są istotne dla wykonywanego zapytania – mały podzbiór danych. W tym przypadku, Athena musiała przeskanować 0,22 GB danych, więc zamiast płacić za 27 GB zeskanowanych danych, płacimy tylko za 0,22 GB.
Czy używanie Parqueta wystarczy?
Używanie Parqueta to dobry początek, jednak optymalizacja zapytań do jeziora danych nie kończy się na tym. Często trzeba oczyścić, wzbogacić i przekształcić dane, wykonać złączenia o wysokiej kardynalności i wdrożyć wiele najlepszych praktyk, aby zapewnić, że odpowiedzi na zapytania będą udzielane szybko i efektywnie kosztowo.
Upsolver może uprościć potok ETL w jeziorze danych, automatycznie pobierać dane jako zoptymalizowany Parquet i przekształcać dane strumieniowe za pomocą funkcji podobnych do SQL lub Excel. Aby dowiedzieć się więcej, umów się na demo tutaj.
Chcesz dowiedzieć się więcej o optymalizacji swojego jeziora danych? Zapoznaj się z niektórymi z tych najlepszych praktyk dotyczących jeziora danych. Aby zobaczyć dodatkowe benchmarki i poznać najlepsze praktyki przygotowywania danych dla Atheny, weź udział w nadchodzącym webinarium Upsolver + Looker, które odbędzie się tutaj.