Jednym z częstych pytań, jakie zadaje mi wiele osób początkujących w T-SQL, jest pytanie o to, jak znaleźć dane w łańcuchu znaków i je wyodrębnić. Jest to bardzo częsta prośba, ponieważ nasze bazy danych zawierają wiele ciągów znaków. Często spotykamy się z tym, że osoby korzystające z aplikacji osadzają informacje w łańcuchu znaków, oczekując, że program będzie w stanie łatwo usunąć te informacje później. W tym artykule, przyjrzę się jak wyodrębnić te dane używając SUBSTRING, CHARINDEX i PATINDEX.
Jest to artykuł powracający do podstaw, który mam nadzieję będzie przydatny dla tych programistów i DBA, którzy są nowi w SQL Server i chcą poprawić swoje umiejętności. Nie krępuj się przekazać tego dalej.
Znajdź spójne PO
Jednym z przykładów jest numer faktury lub numer PO. Często widziałem te dane osadzone w polach tekstowych, z wymogiem późniejszego wyodrębnienia tego numeru z pola. Jest to powszechny typ danych, które są dodawane do pola w jakiejś tabeli, np. w tabeli Klienci. Możemy mieć użytkowników, lub aplikację, która zdecyduje się dodać te dane, aby zdenormalizować nasze dane.
Załóżmy, że mamy tabelę, która zawiera informacje takie jak ta:
CREATE TABLE Customers( CustomerID INT, CustomerName VARCHAR(500), CustomerNotes VARCHAR(MAX), Active TINYINT);GOINSERT dbo.Customers ( CustomerID , CustomerName , CustomerNotes , Active ) VALUES ( 1, 'Acme Inc', 'Last PO:20154402', 1) , ( 2, 'Roadrunner Enterprises', 'Last PO:20140322', 1 ) , ( 3, 'Wile E. Coyote and Sons', 'Unreliable payments', 0)
Jeśli spojrzę na dane, zobaczymy, że ktoś zdecydował się umieścić ważne informacje w polu notatek. Jestem pewien, że wiele doświadczonych osób wzdrygnie się na takie wykorzystanie pól w tabeli, ale zdarza się to częściej niż wielu z nas by chciało.
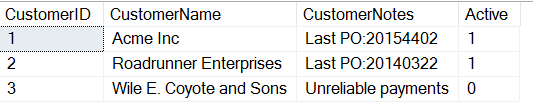
Jeśli teraz chcę wydobyć PO z tego pola, być może do raportu, który jest potrzebny, a być może dlatego, że zamierzam ETLować te dane w bardziej odpowiednie miejsce, mogę użyć funkcji SUBSTRING w T-SQL. Używam tej funkcji, gdy wiem, gdzie wewnątrz ciągu znaków chcę uzyskać dane.
W tym przypadku widzę, że pierwsze 8 znaków pola CustomerNotes to często „Last PO:”. Dzięki temu, mogę zacząć od 9 znaku i uzyskać następne 8 znaków (długość PO). Użyję tego zapytania.
SELECT CustomerID , 'PO' = SUBSTRING(CustomerNotes, 9, 8)FROM dbo.Customers
To zwraca PO, ale dostaję też inne dane.
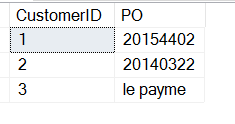
Nie ma obaw, mogę to łatwo odfiltrować (dyskusja na inny artykuł).
SELECT CustomerID , 'PO' = SUBSTRING(CustomerNotes, 9, 8)FROM dbo.Customers WHERE customerNotes LIKE '%PO%'
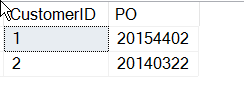
Teraz skończyłem, prawda? No, może nie.
A Inconsistent PO
W danych, które do tej pory oglądałem, numer PO jest zawsze w odpowiednim miejscu. Załóżmy jednak, że nie wszystkie osoby wprowadzające dane pracują z klientami w ten sam sposób. Oto trochę więcej danych, aby pokazać, co mam na myśli:
INSERT dbo.Customers ( CustomerID , CustomerName , CustomerNotes , Active ) VALUES ( 4, 'Beep Beep Enterprises', 'Remember their slogan: We go fast. Last PO:20154402', 1) , ( 5, 'Goldberg Supplies', 'Preferred. Last PO:20140322', 1 ) , ( 6, 'Bugs Deliveries', 'Fast Last PO:20145554', 0)
Następnie uruchommy nasz skrypt z góry. Otrzymamy następujące dane:
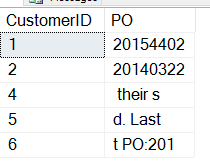
Nie do końca to, co chcemy. Problem polega na tym, że początek SUBSTRINGU nie jest tym, czego chcemy. Powinniśmy zacząć od lokalizacji numeru PO, być może od lokalizacji „PO:”. Jak możemy to uzyskać?
Mamy kilka opcji, ale wprowadź CHARINDEX i PATINDEX. Oba pozwalają nam przeszukiwać ciąg znaków i znaleźć inny ciąg wewnątrz niego. Każda z nich może tutaj zadziałać, ale pozwól, że pokażę Ci jak one działają na naszych danych testowych. Uruchomię to zapytanie:
SELECT CustomerID , CustomerNotes , 'Charindex_StartPO' = CHARINDEX('PO:', CustomerNotes) , 'Patindex_StartPO' = PATINDEX('%PO:%', CustomerNotes) , 'PO' = SUBSTRING(CustomerNotes, 9, 8) FROM dbo.Customers
I otrzymam następujące wyniki:
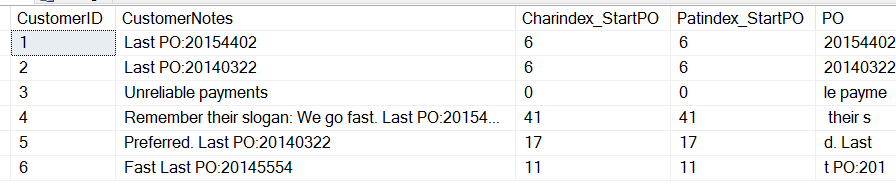
Zauważ, że obie funkcje zwracają tę samą wartość, pozycję początkową „P” w „PO”. Jest kilka różnic. CHARINDEX może zaczynać się od określonej pozycji w łańcuchu, podczas gdy PATINDEX może przyjmować symbole wieloznaczne. W tym uproszczonym przypadku, możemy użyć jednego z nich.
Użyję tutaj CHARINDEX, i zmienię moje zapytanie na takie:
SELECT CustomerID , 'PO' = SUBSTRING(CustomerNotes, CHARINDEX('PO:', CustomerNotes), 8) FROM dbo.Customers WHERE customerNotes LIKE '%PO%';
To daje mi to, co nie jest tym czego chcę.
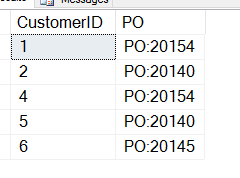
Zapomniałem, że CHARINDEX daje mi początkową pozycję PO, więc muszę dodać do tej wartości. Oto zapytanie, które działa:
SELECT CustomerID , 'PO' = SUBSTRING(CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3, 8) FROM dbo.Customers WHERE customerNotes LIKE '%PO%';
Zauważ, że dodałem 3 do wyniku funkcji CHARINDEX. Oto wyniki:
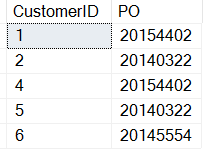
Zamówienia rosną
Wygląda na to, że jest to dobre zapytanie, ale wyobraźmy sobie, że dodajemy trochę więcej danych.
Zauważmy, że w tym przypadku mamy zamówienia zakupu, które zwiększyły swój rozmiar. Niektóre z nich mają 8 znaków, a niektóre 9. Oczywiście możemy wziąć tylko 9 znaków, ale moglibyśmy zwiększyć do 10 lub więcej. Dodatkowo, mamy inne notatki po PO w miejscach.
Zmodyfikujmy nasze zapytanie, aby zobaczyć co możemy zrobić. Do mojego CHARINDEX’a dodałem twist.
SELECT CustomerID , CustomerNotes , 'Start of PO' = CHARINDEX('PO:', CustomerNotes)+3 , 'End of PO' = CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) , 'PO' = SUBSTRING(CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3, 8) FROM dbo.Customers WHERE customerNotes LIKE '%PO%';
Oto wyniki:
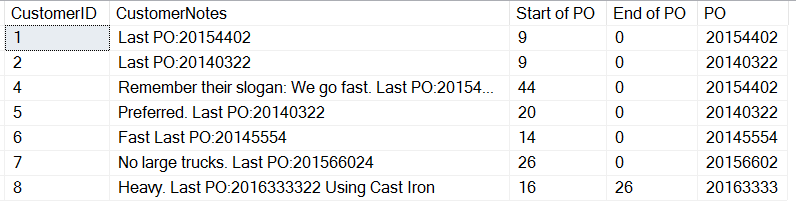
Jeśli przyjrzymy się bliżej, zobaczymy, że nasz ostatni wpis, z tekstem po PO daje nam wynik CHARINDEX. Jest to spowodowane tym, że szukamy ciągu znaków, otrzymujemy 0 jeśli nie znajdziemy żadnego wpisu. Tylko klient 8 ma spację po PO. Oznacza to, że możemy obliczyć długość PO dla ostatniego wpisu, ale co z pozostałymi wpisami, które mają inny format?
Możemy użyć tutaj instrukcji CASE, ponieważ mamy dwie możliwości. Jeden CASE sprawdzi obecność spacji i zwróci indeks spacji wewnątrz łańcucha. Drugi zwróci długość samego łańcucha, gdy spacja nie istnieje. To daje mi kod taki jak ten:
Update: Moja matematyka była niepoprawna. Zmieniłem z -3, na -2 w poniższym kodzie.
SELECT CustomerID , CustomerNotes , 'Start of PO' = CHARINDEX('PO:', CustomerNotes)+3 , 'End of PO' = CASE WHEN CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) = 0 THEN LEN(CustomerNotes) ELSE CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) END , 'Real End of PO' = CASE WHEN CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) = 0 THEN LEN(customernotes) ELSE CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) END - CHARINDEX('PO:', CustomerNotes) , 'PO' = SUBSTRING(CustomerNotes , CHARINDEX('PO:', CustomerNotes)+3 , CASE WHEN CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) = 0 THEN LEN(customernotes) ELSE CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) END - CHARINDEX('PO:', CustomerNotes) - 2 ) FROM dbo.Customers WHERE customerNotes LIKE '%PO%';
Jeśli spojrzymy na ten kod, jest on bardzo podobny do kodu SUBSTRING, którego używaliśmy wcześniej, ale teraz zamiast stałej długości, 8, dla liczby znaków do zwrócenia, zwracamy wartości z formułą. Formuła jest w zasadzie prawdziwym końcem PO (5 kolumna w zestawie wyników) i początkiem PO. Istnieje również instrukcja CASE dla przypadków, gdy otrzymujemy zero.
Jeśli teraz wykonamy obliczenia, możemy zobaczyć, jak długie są poszczególne PO. Dla większości PO jest to 8 znaków (11 znaków po początku litery „P” w „PO:”), ale 9 znaków dla klienta 7 i 11 dla klienta 8.
Niektórzy z Was mogą się zastanawiać nad tym -3 w kodzie, ale jeśli pamiętacie o zasadach arytmetyki, to tak naprawdę przeniosłem minus do ilości reprezentującej początek numeru PO.
Wnioski
To nie koniec możliwości dla PO osadzonych w polu a notes. Mógłbym mieć coś w stylu „test PO: 201530444. Nowy test” i to spowodowałoby problemy z naszym kodem. W rzeczywistości, jest wiele innych przypadków, które musiałbym obsłużyć w prawdziwym świecie.
Ten artykuł pochodzi z kilku problemów ekstrakcji ciągów, które musiałem rozwiązać w prawdziwym świecie, a tego typu problemy występują. Mam nadzieję, że dałem ci kilka umiejętności do przećwiczenia, które pomogą ci w manipulowaniu ciągami w SQL Server.
Jak w przypadku każdej techniki, której możesz się tutaj nauczyć, upewnij się, że ocenisz wpływ na wydajność. Wykonaj swój kod na dużym zestawie danych testowych i określ, jak dobrze ta technika może działać w porównaniu z innymi technikami. Zalecam użycie tabeli tally, aby wygenerować dane o skali większej niż tabele produkcyjne.
Manipulacje łańcuchowe mogą być kosztowne obliczeniowo w SQL Server, więc upewnij się, że rozumiesz wpływ swoich wyborów, zanim wdrożysz kod do systemu produkcyjnego.
Poprawność kodu jest bardzo ważna.