Szybkość stron internetowych jest priorytetem dla firm w 2020 roku.
Szybsze strony internetowe zajmują wyższe pozycje w wyszukiwarkach, a także zapewniają lepsze doświadczenia użytkowników, co skutkuje wyższym współczynnikiem konwersji. Nic dziwnego, że właściciele stron internetowych domagają się szybszego ładowania stron, pozostawiając programistom zadanie jego realizacji.
Optymalizacja bazy danych jest niezbędnym krokiem do poprawy wydajności strony. Zazwyczaj programiści normalizują relacyjną bazę danych, co oznacza, że restrukturyzują ją w celu zmniejszenia nadmiarowości danych i zwiększenia ich integralności. Jednakże, czasami normalizacja bazy danych nie wystarcza, więc aby jeszcze bardziej poprawić jej wydajność, programiści idą w drugą stronę i uciekają się do denormalizacji bazy danych.
W tym artykule przyjrzymy się bliżej denormalizacji, aby dowiedzieć się kiedy ta metoda jest odpowiednia i jak można ją przeprowadzić.
Kiedy denormalizować bazę danych
Co to jest denormalizacja bazy danych? Zanim zagłębimy się w temat, podkreślmy, że punktem wyjścia nadal pozostaje normalizacja, co oznacza, że w pierwszej kolejności należy znormalizować strukturę bazy danych. Istotą normalizacji jest umieszczenie każdego elementu danych na właściwym dla niego miejscu, co zapewnia integralność danych i ułatwia ich aktualizację. Jednakże, pobieranie danych z normalizowanej bazy danych może być wolniejsze, ponieważ zapytania muszą kierować się do wielu różnych tabel, w których przechowywane są różne elementy danych. Aktualizacja, przeciwnie, staje się szybsza, ponieważ wszystkie elementy danych są przechowywane w jednym miejscu.
Większość nowoczesnych aplikacji musi być w stanie pobierać dane w jak najkrótszym czasie. I właśnie wtedy można rozważyć denormalizację relacyjnej bazy danych. Jak sama nazwa wskazuje, denormalizacja jest przeciwieństwem normalizacji. Kiedy normalizujesz bazę danych, porządkujesz dane, aby zapewnić integralność i wyeliminować nadmiarowość. Denormalizacja bazy danych oznacza, że celowo umieszczasz te same dane w kilku miejscach, zwiększając w ten sposób nadmiarowość.
„Po co w ogóle denormalizować bazę danych?”, możesz zapytać. Głównym celem denormalizacji jest znaczne przyspieszenie wyszukiwania danych. Jednakże, denormalizacja nie jest magiczną pigułką. Deweloperzy powinni używać tego narzędzia tylko do określonych celów:
# 1 Aby zwiększyć wydajność zapytań
Typowo, znormalizowana baza danych wymaga łączenia wielu tabel w celu pobierania zapytań; ale im więcej łączeń, tym wolniejsze zapytanie. Jako środek zaradczy, możesz dodać redundancję do bazy danych poprzez kopiowanie wartości pomiędzy tabelami nadrzędnymi i podrzędnymi, a tym samym zmniejszyć liczbę złączeń wymaganych dla zapytania.
#2 Aby uczynić bazę danych wygodniejszą w zarządzaniu
Normalizowana baza danych nie posiada obliczanych wartości, które są niezbędne dla aplikacji. Obliczanie tych wartości w locie wymagałoby czasu, spowalniając wykonywanie zapytań.
Możesz zdenormalizować bazę danych, aby zapewnić obliczane wartości. Po ich wygenerowaniu i dodaniu do tabel, kolejni programiści mogą łatwo tworzyć własne raporty i zapytania bez konieczności posiadania dogłębnej wiedzy na temat kodu aplikacji lub API.
#3 Ułatwienie i przyspieszenie raportowania
Często aplikacje muszą dostarczać wiele informacji analitycznych i statystycznych. Generowanie raportów z danych na żywo jest czasochłonne i może negatywnie wpłynąć na ogólną wydajność systemu.
Denormalizacja bazy danych może pomóc w sprostaniu temu wyzwaniu. Załóżmy, że musisz dostarczyć podsumowanie całkowitej sprzedaży dla jednego lub wielu użytkowników; znormalizowana baza danych zagregowałaby i obliczyła wszystkie szczegóły faktur wiele razy. Nie trzeba dodawać, że byłoby to dość czasochłonne, więc aby przyspieszyć ten proces, możesz przechowywać podsumowanie sprzedaży od początku roku do końca roku w tabeli przechowującej dane użytkownika.
Techniki denormalizacji bazy danych
Gdy już wiesz, kiedy powinieneś dokonać denormalizacji bazy danych, zastanawiasz się pewnie, jak zrobić to dobrze. Istnieje kilka technik denormalizacji, z których każda jest odpowiednia dla konkretnej sytuacji. Przyjrzyjmy się im bliżej:
Przechowywanie danych pochodnych
Jeśli musisz wykonywać obliczenia wielokrotnie podczas zapytań, najlepiej jest przechowywać ich wyniki. Jeśli kalkulacja zawiera rekordy szczegółowe, powinieneś przechowywać pochodną kalkulacji w tabeli głównej. Jeśli zdecydujesz się na przechowywanie wartości pochodnych, upewnij się, że wartości zdenormalizowane są zawsze przeliczane przez system.
Oto sytuacje, w których przechowywanie wartości pochodnych jest właściwe:
- Gdy często potrzebujesz wartości pochodnych
- Gdy nie zmieniasz często wartości źródłowych
| Wady | Disadvantages |
|---|---|
| Nie ma potrzeby potrzeby wyszukiwania wartości źródłowych za każdym razem, gdy potrzebna jest wartość pochodna | Running data manipulation language (DML) w stosunku do danych źródłowych wymaga ponownego obliczenia danych pochodnych |
| Nie ma potrzeby wykonywania obliczeń dla każdego zapytania lub raportu | Możliwe są niespójności danych ze względu na duplikację danych |
Przykład

Jako przykład zastosowania tej techniki denormalizacji, załóżmy, że budujemy usługę wysyłania wiadomości e-mail. Po otrzymaniu wiadomości, użytkownik otrzymuje tylko wskaźnik do tej wiadomości; wskaźnik jest przechowywany w tabeli User_messages. Jest to zrobione po to, aby zapobiec przechowywaniu przez system wiadomości wielu kopii wiadomości e-mail w przypadku, gdy jest ona wysyłana do wielu różnych odbiorców jednocześnie. Co jednak w przypadku, gdy użytkownik usunie wiadomość ze swojego konta? W takim przypadku usuwany jest tylko odpowiedni wpis w tabeli User_messages. Aby więc całkowicie usunąć wiadomość, należy usunąć wszystkie rekordy User_messages dla tej wiadomości.
Denormalizacja danych w jednej z tabel może to znacznie uprościć: możemy dodać users_received_count do tabeli Messages, aby zachować zapis User_messages przechowywanych dla konkretnej wiadomości. Kiedy użytkownik usuwa tę wiadomość (czytaj: usuwa wskaźnik do rzeczywistej wiadomości), kolumna users_received_count jest dekrementowana o jeden. Naturalnie, gdy users_received_count równa się zero, rzeczywista wiadomość może zostać całkowicie usunięta.
Używanie wstępnie połączonych tabel
Aby wstępnie połączyć tabele, musisz dodać kolumnę bez klucza do tabeli, która nie ma wartości biznesowej. W ten sposób można uniknąć łączenia tabel, a tym samym przyspieszyć zapytania. Należy jednak zadbać o to, aby zdenormalizowana kolumna była aktualizowana za każdym razem, gdy zmieni się wartość kolumny nadrzędnej.
Ta technika denormalizacji może być używana, gdy trzeba wykonać wiele zapytań do wielu różnych tabel – i tak długo, jak nieświeże dane są akceptowalne.
| Wady | Wady |
|---|---|
| Nie ma potrzeby używania wielokrotnych złączeń | DML jest wymagany do aktualizacji niezdenormalizowanej kolumny |
| Możesz odłożyć aktualizacje tak długo, jak długo nieświeże dane są tolerowane | Dodatkowa kolumna wymaga dodatkowej pracy i miejsca na dysku |
Przykład

Wyobraźmy sobie, że użytkownicy naszej usługi wiadomości e-mail chcą mieć dostęp do wiadomości według kategorii. Przechowywanie nazwy kategorii bezpośrednio w tabeli User_messages może zaoszczędzić czas i zmniejszyć liczbę koniecznych złączeń.
W powyższej zdenormalizowanej tabeli wprowadziliśmy kolumnę category_name w celu przechowywania informacji o tym, z jaką kategorią związany jest każdy rekord w tabeli User_messages. Dzięki denormalizacji wystarczy wykonać zapytanie do tabeli User_messages, aby użytkownik mógł wybrać wszystkie wiadomości należące do określonej kategorii. Oczywiście ta technika denormalizacji ma swoją wadę – ta dodatkowa kolumna może wymagać dużo miejsca na dysku.
Używanie twardo zakodowanych wartości
Jeśli istnieje tabela referencyjna ze stałymi rekordami, możesz je twardo zakodować w swojej aplikacji. W ten sposób nie musisz łączyć tabel, aby pobrać wartości referencyjne.
Jednakże, gdy używasz wartości zakodowanych na sztywno, powinieneś utworzyć ograniczenie sprawdzające, aby zweryfikować wartości względem wartości referencyjnych. Ograniczenie to musi być przepisane za każdym razem, gdy wymagana jest nowa wartość w tabeli A.
Ta technika denormalizacji danych powinna być używana, jeśli wartości są statyczne przez cały cykl życia systemu i tak długo, jak liczba tych wartości jest dość mała. Przyjrzyjmy się teraz wadom i zaletom tej techniki:
| Zalety | Wady |
|---|---|
| Nie ma potrzeby implementacji tabeli wyszukującej | Kodowanie i przekształcanie jest wymagane, jeśli wartościwartości są zmieniane |
| Nie wymaga dołączania do tabeli wyszukującej |
Przykład
.

Przypuśćmy, że potrzebujemy dowiedzieć się podstawowych informacji o użytkownikach usługi wiadomości e-mail, na przykład rodzaj lub typ użytkownika. Stworzyliśmy tabelę User_kinds do przechowywania danych o rodzajach użytkowników, których musimy rozpoznać.
Wartości przechowywane w tej tabeli nie będą prawdopodobnie często zmieniane, więc możemy zastosować hardcoding. Możemy dodać ograniczenie wyboru do kolumny lub wbudować ograniczenie wyboru w walidację pola dla aplikacji, w której użytkownicy logują się do naszej usługi wiadomości e-mail.
Utrzymywanie szczegółów z wzorcem
Mogą wystąpić przypadki, gdy liczba rekordów szczegółów na wzorzec jest stała lub gdy rekordy szczegółów są odpytywane z wzorca. W takich przypadkach, możesz zdenormalizować bazę danych poprzez dodanie kolumn szczegółów do tabeli nadrzędnej. Technika ta okazuje się najbardziej przydatna, gdy w tabeli szczegółów znajduje się niewiele rekordów.
| Wady | Wady |
|---|---|
| Nie trzeba używać złączeń | Powiększona złożoność DML |
| Zapewnia oszczędność miejsca |
Przykład
.

Wyobraźmy sobie, że musimy ograniczyć maksymalną ilość przestrzeni dyskowej, jaką może otrzymać użytkownik. Aby to zrobić, musimy zaimplementować ograniczenia w naszej usłudze wiadomości e-mail – jedno dla wiadomości, a drugie dla plików. Ponieważ ilość dozwolonej przestrzeni dyskowej dla każdego z tych ograniczeń jest inna, musimy śledzić każde ograniczenie indywidualnie. W znormalizowanej relacyjnej bazie danych moglibyśmy po prostu wprowadzić dwie różne tabele – Storage_types i Storage_restraints – które przechowywałyby rekordy dla każdego użytkownika.
Zamiast tego możemy pójść inną drogą i dodać zdenormalizowane kolumny do tabeli Users:
message_space_allocated
message_space_available
file_space_allocated
file_space_available
W tym przypadku zdenormalizowana tabela Users przechowuje nie tylko faktyczne informacje o użytkowniku, ale również ograniczenia, więc pod względem funkcjonalności tabela nie do końca odpowiada swojej nazwie.
Replikacja pojedynczego szczegółu z jego wzorcem
Gdy masz do czynienia z danymi historycznymi, wiele zapytań wymaga konkretnego pojedynczego rekordu i rzadko wymaga innych szczegółów. Dzięki tej technice denormalizacji bazy danych, możesz wprowadzić nową kolumnę klucza obcego do przechowywania tego rekordu z jego masterem. Podczas korzystania z tego typu denormalizacji nie zapomnij dodać kodu, który będzie aktualizował zdenormalizowaną kolumnę, gdy zostanie dodany nowy rekord.
| Wady | Wady |
|---|---|
| Nie ma potrzeby tworzenia złączeń dla zapytań, które wymagają pojedynczego rekordu | Możliwe są niespójności danych, ponieważ wartość rekordu musi być powtarzana |
Przykład
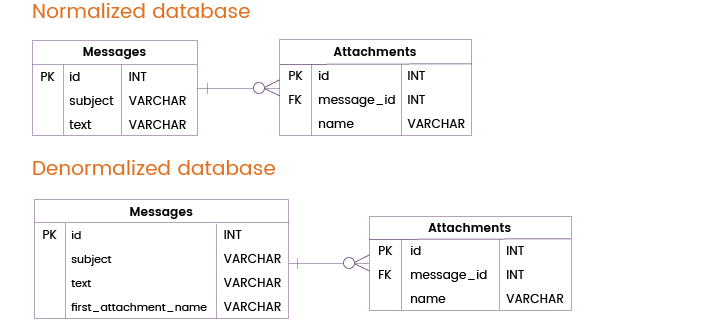
Często, użytkownicy wysyłają nie tylko wiadomości, ale również załączniki. Większość wiadomości jest wysyłana bez załącznika lub z jednym załącznikiem, ale w niektórych przypadkach użytkownicy dołączają do wiadomości kilka plików.
Możemy uniknąć złączenia tabel poprzez denormalizację tabeli Messages poprzez dodanie kolumny first_attachment_name. Oczywiście, jeśli wiadomość zawiera więcej niż jeden załącznik, tylko pierwszy załącznik zostanie pobrany z tabeli Messages, podczas gdy inne załączniki będą przechowywane w oddzielnej tabeli Attachments i dlatego będą wymagały złączenia tabel. W większości przypadków jednak ta technika denormalizacji będzie naprawdę pomocna.
Dodawanie kluczy zwarciowych
Jeśli baza danych ma ponad trzy poziomy szczegółów nadrzędnych i potrzebujesz odpytywać tylko rekordy z najniższego i najwyższego poziomu, możesz denormalizować swoją bazę danych poprzez tworzenie kluczy zwarciowych, które łączą rekordy wnuków z rekordami dziadków z najniższego poziomu. Ta technika pozwala zredukować liczbę złączeń tabel podczas wykonywania zapytań.
| Zalety | Wady |
|---|---|
| Mniej tabel jest łączonych podczas zapytań | Musimy używać więcej kluczy obcych |
| Potrzebny dodatkowy kod, aby zapewnić spójność wartości |
Przykład
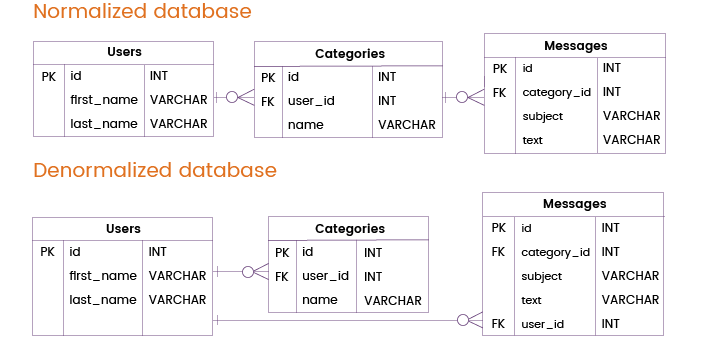
Wyobraźmy sobie teraz, że serwis do obsługi wiadomości e-mail musi obsługiwać częste zapytania, które wymagają danych tylko z tabel Użytkownicy i Wiadomości, bez odwoływania się do tabeli Kategorie. W znormalizowanej bazie danych takie zapytania musiałyby łączyć tabele Użytkownicy i Kategorie.
Aby poprawić wydajność bazy danych i uniknąć takich łączeń, możemy dodać klucz główny lub unikalny z tabeli Użytkownicy bezpośrednio do tabeli Wiadomości. W ten sposób możemy uzyskać informacje o użytkownikach i wiadomościach bez konieczności odwoływania się do tabeli Kategorie, a więc bez zbędnego złączenia tabel.
Wady denormalizacji bazy danych
Zastanawiasz się pewnie: denormalizować czy nie denormalizować?
Choć denormalizacja wydaje się najlepszym sposobem na zwiększenie wydajności bazy danych, a co za tym idzie, aplikacji w ogóle, powinieneś sięgać po nią tylko wtedy, gdy inne metody okażą się nieefektywne. Na przykład, często niewystarczająca wydajność bazy danych może być spowodowana niepoprawnie napisanymi zapytaniami, błędnym kodem aplikacji, niespójnym projektem indeksów, a nawet niewłaściwą konfiguracją sprzętu.
Denormalizacja brzmi kusząco i jest niezwykle wydajna w teorii, ale wiąże się z kilkoma wadami, o których musisz wiedzieć, zanim zdecydujesz się na tę strategię:
- Dodatkowa przestrzeń dyskowa
Gdy denormalizujesz bazę danych, musisz zduplikować wiele danych. Naturalnie, Twoja baza danych będzie wymagała więcej miejsca do przechowywania danych.
- Dodatkowa dokumentacja
Każdy pojedynczy krok, który wykonujesz podczas denormalizacji, musi być odpowiednio udokumentowany. Jeśli później zmienisz projekt bazy danych, będziesz musiał zrewidować wszystkie stworzone wcześniej reguły: być może niektóre z nich nie będą potrzebne lub będziesz musiał uaktualnić poszczególne reguły denormalizacji.
- Potencjalne anomalie danych
Podczas denormalizacji bazy danych, powinieneś zrozumieć, że otrzymujesz więcej danych, które mogą być modyfikowane. W związku z tym, musisz zadbać o każdy przypadek duplikacji danych. Powinieneś używać wyzwalaczy, procedur składowanych i transakcji, aby uniknąć anomalii danych.
- Więcej kodu
- Podczas denormalizacji bazy danych modyfikujesz zapytania select i chociaż przynosi to wiele korzyści, ma to swoją cenę – musisz napisać dodatkowy kod. Musisz również aktualizować wartości w nowych atrybutach, które dodajesz do istniejących rekordów, co oznacza, że potrzeba jeszcze więcej kodu.
- Spowolnienie operacji
- Denormalizacja bazy danych może przyspieszyć pobieranie danych, ale jednocześnie spowalnia ich aktualizację. Jeśli Twoja aplikacja musi wykonywać wiele operacji zapisu do bazy danych, może wykazywać wolniejszą wydajność niż podobna znormalizowana baza danych. Upewnij się więc, że wdrożenie denormalizacji nie zaszkodzi użyteczności Twojej aplikacji.
Wskazówki dotyczące denormalizacji bazy danych
Jak widzisz, denormalizacja jest poważnym procesem, który wymaga wiele wysiłku i umiejętności. Jeśli chcesz bezproblemowo denormalizować bazy danych, skorzystaj z poniższych wskazówek:
- Nie próbuj od razu denormalizować całej bazy danych, skup się na poszczególnych jej częściach, które chcesz przyspieszyć.
- Daj z siebie wszystko, aby dobrze poznać logiczny projekt swojej aplikacji, aby zrozumieć, na jakie części systemu denormalizacja może mieć wpływ.
- Zanalizuj, jak często dane są zmieniane w Twojej aplikacji; jeśli dane zmieniają się zbyt często, utrzymanie integralności bazy danych po denormalizacji może stać się prawdziwym problemem.
- Przyjrzyjrzyj się uważnie, które części aplikacji mają problemy z wydajnością; często można przyspieszyć działanie aplikacji poprzez dopracowanie zapytań zamiast denormalizacji bazy danych.
- Poznaj więcej technik przechowywania danych; wybranie najbardziej odpowiednich może pomóc obejść się bez denormalizacji.
Podsumowanie
Zawsze powinieneś zacząć od zbudowania czystej i wydajnej znormalizowanej bazy danych. Tylko jeśli potrzebujesz, aby Twoja baza danych wykonywała lepiej określone zadania (takie jak raportowanie), powinieneś zdecydować się na denormalizację. W przypadku denormalizacji należy zachować ostrożność i udokumentować wszystkie zmiany w bazie danych.
Przed przystąpieniem do denormalizacji należy zadać sobie następujące pytania:
- Czy mój system może osiągnąć wystarczającą wydajność bez denormalizacji?
- Czy wydajność mojej bazy danych może stać się nie do zaakceptowania po denormalizacji?
- Czy mój system stanie się mniej niezawodny?
Jeśli odpowiedź na którekolwiek z tych pytań jest twierdząca, to lepiej zrezygnować z denormalizacji, ponieważ prawdopodobnie okaże się ona nieefektywna dla Twojej aplikacji. Jeśli jednak denormalizacja jest jedyną opcją, należy najpierw poprawnie znormalizować bazę danych, a następnie przejść do jej denormalizacji, uważnie i ściśle stosując się do technik opisanych w tym artykule.
Aby uzyskać więcej informacji na temat najnowszych trendów w rozwoju oprogramowania, zapisz się na nasz blog.
Więcej informacji na temat najnowszych trendów w rozwoju oprogramowania znajdziesz na naszym blogu.