Este post cobre as bases do Apache Parquet, que é um importante bloco de construção em grande arquitectura de dados. Para saber mais sobre a gestão de ficheiros no armazenamento de objectos, consulte o nosso guia de Particionamento de Dados no Amazon S3.
Na conferência Amazon re:Inventory do ano passado (quando as conferências da vida real ainda eram uma coisa), AWS anunciou a exportação de dados do lago – a capacidade de descarregar o resultado de uma consulta Redshift para o Amazon S3 no formato Apache Parquet. No anúncio, AWS descreveu Parquet como “2x mais rápido para descarregar e consome até 6x menos armazenamento no Amazon S3, em comparação com os formatos de texto”. A conversão de dados para formatos colunares como Parquet ou ORC é também recomendada como meio de melhorar o desempenho do Amazon Athena.
É evidente que o Apache Parquet desempenha um papel importante no desempenho do sistema quando se trabalha com lagos de dados. Vamos analisar mais de perto o que Parquet realmente é, e porque é importante para o grande armazenamento e análise de dados.
The Basics: O que é Apache Parquet?
Apache Parquet é um formato de ficheiro concebido para suportar o processamento rápido de dados para dados complexos, com várias características notáveis:
1. Colunar: Ao contrário dos formatos baseados em linhas tais como CSV ou Avro, o Apache Parquet é orientado para colunas – o que significa que os valores de cada coluna da tabela são armazenados lado a lado, em vez dos valores de cada registo:
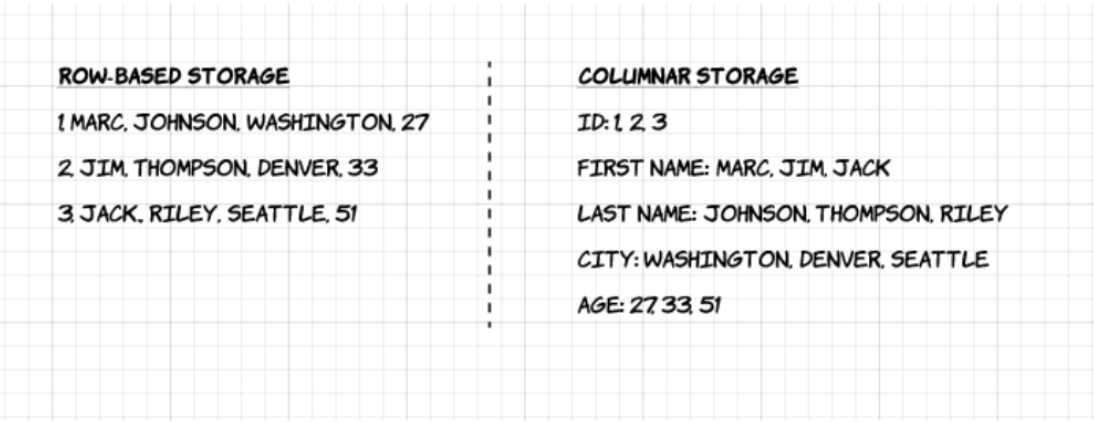
2. Código aberto: Parquet é livre de usar e de código aberto sob a licença Apache Hadoop, e é compatível com a maioria das estruturas de processamento de dados Hadoop.
3. Auto-descrição: Em Parquet, metadados incluindo esquema e estrutura são incorporados em cada ficheiro, tornando-o num formato de ficheiro auto-descritivo.
Vantagens do armazenamento Colunar Parquet
As características acima mencionadas do formato de ficheiro Apache Parquet criam vários benefícios distintos quando se trata de armazenamento e análise de grandes volumes de dados. Vamos olhar para alguns deles com mais profundidade.
Compressão
Compressão de ficheiro é o acto de pegar num ficheiro e torná-lo mais pequeno. Em Parquet, a compressão é executada coluna a coluna e é construída para suportar opções de compressão flexíveis e esquemas de codificação extensíveis por tipo de dados – por exemplo, diferentes codificações podem ser usadas para comprimir dados inteiros e de cadeia.
Parquet data can be compressed using these encoding methods:
- Codificação de dicionário: isto é activado automática e dinamicamente para dados com um pequeno número de valores únicos.
- Bit packing: O armazenamento de inteiros é normalmente feito com 32 ou 64 bits dedicados por inteiro. Isto permite um armazenamento mais eficiente de pequenos inteiros.
- codificação do comprimento de execução (RLE): quando o mesmo valor ocorre várias vezes, um único valor é armazenado uma vez juntamente com o número de ocorrências. Parquet implementa uma versão combinada de embalagem de bits e RLE, na qual os interruptores de codificação baseados em que produz os melhores resultados de compressão.

Desempenho
Ao contrário dos formatos de ficheiro baseados em linhas como o CSV, Parquet é optimizado para o desempenho. Ao executar consultas no seu sistema de ficheiros baseado em Parquet, pode concentrar-se muito rapidamente apenas nos dados relevantes. Além disso, a quantidade de dados digitalizados será muito menor e resultará numa menor utilização de E/S. Para compreender isto, vamos olhar um pouco mais profundamente para a forma como os ficheiros Parquet são estruturados.
Como mencionámos acima, Parquet é um formato autodescrito, pelo que cada ficheiro contém tanto dados como metadados. Os ficheiros Parquet são compostos por grupos de linhas, cabeçalho e rodapé. Cada grupo de linhas contém dados das mesmas colunas. As mesmas colunas são armazenadas juntas em cada grupo de linhas:
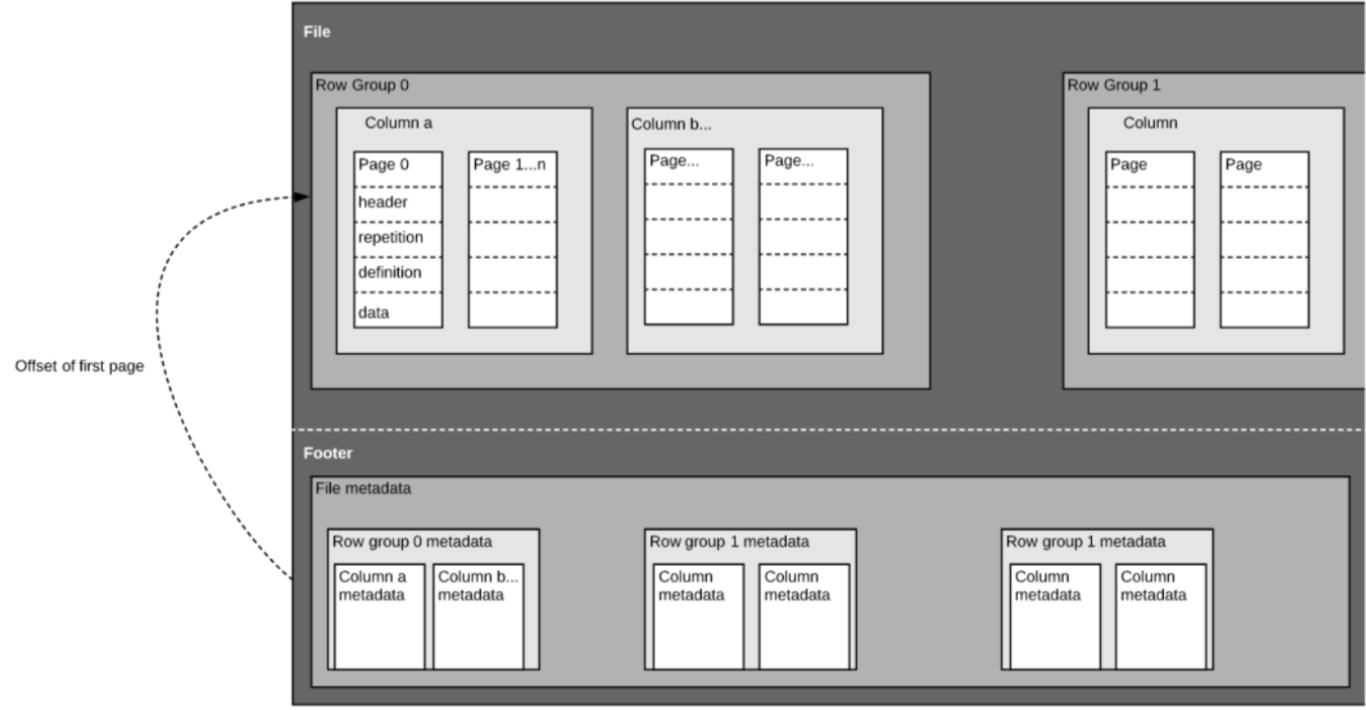
Esta estrutura é bem optimizada tanto para um rápido desempenho da consulta, como para um baixo I/O (minimizando a quantidade de dados digitalizados). Por exemplo, se tiver uma tabela com 1000 colunas, que normalmente só será consultada utilizando um pequeno subconjunto de colunas. A utilização de ficheiros Parquet permitir-lhe-á ir buscar apenas as colunas necessárias e os seus valores, carregar as que estão na memória e responder à consulta. Se fosse utilizado um formato de ficheiro baseado em linhas como o CSV, toda a tabela teria de ter sido carregada na memória, resultando num aumento de E/S e pior desempenho.
Schema evolution
Ao utilizar formatos de ficheiro de colunas como Parquet, os utilizadores podem começar com um esquema simples, e gradualmente adicionar mais colunas ao esquema conforme necessário. Desta forma, os utilizadores podem acabar com múltiplos ficheiros Parquet com esquemas diferentes mas mutuamente compatíveis. Nestes casos, Parquet suporta a fusão automática de esquemas entre estes ficheiros.
Open-source support
Apache Parquet, como mencionado acima, faz parte do ecossistema Apache Hadoop que é open-source e está a ser constantemente melhorado e apoiado por uma forte comunidade de utilizadores e programadores. Armazenar os seus dados em formatos abertos significa evitar o bloqueio de fornecedores e aumentar a sua flexibilidade, em comparação com formatos de ficheiros proprietários utilizados por muitas bases de dados modernas de alto desempenho. Isto significa que pode utilizar vários motores de consulta, tais como Amazon Athena, Qubole, e Amazon Redshift Spectrum, dentro da mesma arquitectura de lago de dados.
Coluna orientada vs armazenamento baseado em linhas para consulta analítica
Os dados são frequentemente gerados e mais facilmente conceptualizados em linhas. Estamos habituados a pensar em termos de folhas de cálculo Excel, onde podemos ver todos os dados relevantes para um registo específico numa fila limpa e organizada. Contudo, para consultas analíticas em grande escala, o armazenamento em colunas apresenta vantagens significativas em termos de custo e desempenho.
Dados complexos tais como registos e fluxos de eventos precisariam de ser representados como uma tabela com centenas ou milhares de colunas, e muitos milhões de filas. Armazenar esta tabela num formato baseado em linhas, como o CSV, significaria:
- As consultas demorarão mais tempo a correr, uma vez que mais dados precisam de ser digitalizados, em vez de apenas consultar o subconjunto de colunas, precisamos de responder a uma consulta (o que normalmente requer uma agregação baseada na dimensão ou categoria)
- Armazenamento será mais dispendioso, uma vez que os CSV não são comprimidos tão eficientemente como Parquet
Os formatos colunares permitem uma melhor compressão e um melhor desempenho out-of-the-box, e permitem consultar os dados verticalmente – coluna por coluna.
Exemplo: Parquet, CSV e Amazon Athena
Estamos a explorar este exemplo em muito maior profundidade no nosso próximo webinar com o Looker. Guarde aqui o seu lugar.
Para demonstrar o impacto do armazenamento de Parquet colunar em comparação com as alternativas baseadas em linhas, vejamos o que acontece quando se utiliza o Amazon Athena para consultar dados armazenados no Amazon S3 em ambos os casos.
Utilizando o Upsolver, ingerimos um conjunto de dados CSV dos registos do servidor para o S3. Numa arquitectura comum do lago de dados AWS, Athena seria utilizado para consultar os dados directamente a partir de S3. Estas consultas podem então ser visualizadas usando ferramentas interactivas de visualização de dados tais como Tableau ou Looker.
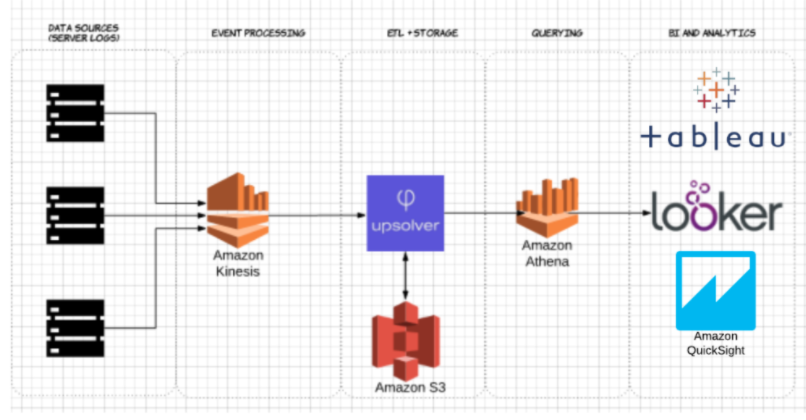
Testamos Athena contra o mesmo conjunto de dados armazenados como CSV comprimido, e como Apache Parquet.
Esta é a consulta que fizemos em Athena:
SELECT tags_host AS host_id, AVG(fields_usage_active) as avg_usage
FROM server_usage
GROUP BY tags_host
HAVING AVG(fields_usage_active) > 0
LIMIT 10
E os resultados:
| >/td>>CSV | Parquet | Colunas | |
| Tempo de consulta (segundos) | 735 | 211 | 18 |
| Dados digitalizados (GB) | 372.2 | 10.29 | 18 |
- CSVs comprimidos: O CSV comprimido tem 18 colunas e pesa 27 GB em S3. Athena tem de digitalizar todo o ficheiro CSV para responder à consulta, pelo que estaríamos a pagar por 27 GB de dados digitalizados. Em escalas superiores, isto também teria um impacto negativo no desempenho.
- Parquet: Convertendo os nossos ficheiros CSV comprimidos para Apache Parquet, acabamos com uma quantidade semelhante de dados em S3. Contudo, como Parquet é colunar, Athena precisa de ler apenas as colunas que são relevantes para a consulta que está a ser executada – um pequeno subconjunto dos dados. Neste caso, Athena teve de digitalizar 0,22 GB de dados, por isso, em vez de pagarmos por 27 GB de dados digitalizados, pagamos apenas por 0,22 GB.
Usa Parquet o suficiente?
Utilizar Parquet é um bom começo; no entanto, optimizar as consultas do lago de dados não acaba aí. Muitas vezes é necessário limpar, enriquecer e transformar os dados, realizar uniões de alta cardinalidade e implementar uma série de melhores práticas a fim de assegurar que as consultas são respondidas de forma consistente, rápida e rentável.
Pode usar o Upsolver para simplificar o seu gasoduto ETL do lago de dados, ingerir automaticamente dados como Parquet optimizado e transformar dados em fluxo com funções semelhantes a SQL ou Excel. Para saber mais, agende uma demonstração aqui.
Quer saber mais sobre a optimização do seu lago de dados? Verifique algumas destas melhores práticas de data lake. Para ver referências adicionais e aprender as melhores práticas ao preparar dados para Athena, junte-se ao próximo webinar Upsolver + Looker aqui mesmo.