A velocidade do sítio Web é uma prioridade para as empresas em 2020.
Siteiros Web mais rápidos são mais bem classificados nos motores de busca e também proporcionam melhores experiências aos utilizadores, resultando em taxas de conversão mais elevadas. Não admira que os proprietários de sítios web exijam velocidades de carregamento de páginas mais rápidas – deixando os programadores a realizá-lo.
A optimização da base de dados é um passo essencial para melhorar o desempenho do sítio web. Tipicamente, os programadores normalizam uma base de dados relacional, o que significa que a reestruturam para reduzir a redundância de dados e melhorar a integridade dos dados. No entanto, por vezes, normalizar uma base de dados não é suficiente, pelo que para melhorar o desempenho de uma base de dados ainda mais os programadores vão ao contrário e recorrem à desnormalização da base de dados.
Neste artigo, damos uma vista de olhos mais atenta à desnormalização para descobrir quando este método é apropriado e como o pode fazer.
Quando se desnormaliza uma base de dados
O que é a desnormalização de uma base de dados? Antes de mergulhar no assunto, sublinhemos que a normalização continua a ser o ponto de partida, o que significa que deve antes de mais normalizar a estrutura de uma base de dados. A essência da normalização é colocar cada dado no seu devido lugar; isto assegura a integridade dos dados e facilita a sua actualização. No entanto, a recuperação de dados de uma base de dados normalizada pode ser mais lenta, uma vez que as consultas têm de se dirigir a muitas tabelas diferentes onde são armazenados diferentes pedaços de dados. A actualização, pelo contrário, torna-se mais rápida, pois todos os pedaços de dados são armazenados num único local.
A maioria das aplicações modernas precisa de ser capaz de recuperar dados no mais curto espaço de tempo possível. E é nessa altura que se pode considerar a desnormalização de uma base de dados relacional. Como o nome sugere, a desnormalização é o oposto de normalização. Quando se normaliza uma base de dados, organizam-se os dados para assegurar a integridade e eliminar redundâncias. A desnormalização de uma base de dados significa que coloca deliberadamente os mesmos dados em vários locais, aumentando assim a redundância.
“Porquê desnormalizar de todo uma base de dados?” pode perguntar. O principal objectivo da desnormalização é acelerar significativamente a recuperação de dados. Contudo, a desnormalização não é uma pílula mágica. Os programadores devem utilizar esta ferramenta apenas para fins particulares:
# 1 Para melhorar o desempenho da consulta
Tipicamente, uma base de dados normalizada requer a junção de muitas tabelas para ir buscar as consultas; mas quanto mais se junta, mais lenta é a consulta. Como contramedida, é possível adicionar redundância a uma base de dados, copiando valores entre tabelas de pais e filhos e, portanto, reduzindo o número de junções necessárias para uma consulta.
#2 Para tornar uma base de dados mais conveniente de gerir
Uma base de dados normalizada não tem valores calculados que são essenciais para as aplicações. O cálculo destes valores em tempo real exigiria tempo, atrasando a execução da consulta.
Pode desnormalizar uma base de dados para fornecer valores calculados. Uma vez gerados e adicionados às tabelas, os programadores a jusante podem facilmente criar os seus próprios relatórios e consultas sem terem um conhecimento profundo do código da aplicação ou API.
#3 Para facilitar e acelerar a elaboração de relatórios
Frequentemente, as aplicações precisam de fornecer muita informação analítica e estatística. A geração de relatórios a partir de dados em tempo real é morosa e pode ter um impacto negativo no desempenho global do sistema.
Desnormalizar a sua base de dados pode ajudá-lo a enfrentar este desafio. Suponha que precisa de fornecer um resumo de vendas total para um ou muitos utilizadores; uma base de dados normalizada agregaria e calcularia todos os detalhes das facturas várias vezes. Escusado será dizer que isto seria bastante demorado, por isso, para acelerar este processo, poderia manter o resumo de vendas do ano até à data numa tabela que armazenasse os detalhes do utilizador.
Técnicas de desnormalização da base de dados
Agora que sabe quando deve proceder à desnormalização da base de dados, está provavelmente a perguntar-se como fazê-lo correctamente. Existem várias técnicas de desnormalização, cada uma apropriada para uma situação particular. Vamos explorá-las em profundidade:
Armazenamento de dados derivados
Se precisar de executar um cálculo repetidamente durante as consultas, o melhor é armazenar os resultados do mesmo. Se o cálculo contiver registos detalhados, deverá armazenar o cálculo derivado na tabela principal. Sempre que decidir armazenar valores derivados, certifique-se de que os valores desnormalizados são sempre recalculados pelo sistema.
Existem situações em que o armazenamento de valores deriváveis é apropriado:
- Quando necessita frequentemente de valores deriváveis
- Quando não altera frequentemente os valores da fonte
| Vantagens | Disvantagens |
|---|---|
| No necessidade de procurar valores de origem cada vez que é necessário um valor derivável | Linguagem de manipulação de dados em execução (DML) declarações contra os dados de origem requerem um novo cálculo dos dados derivados |
| Não é necessário efectuar um cálculo para cada consulta ou relatório | São possíveis inconsistências de dados devido à duplicação de dados |
Exemplo

Como exemplo desta técnica de desnormalização, vamos supor que estamos a construir um serviço de mensagens de correio electrónico. Tendo recebido uma mensagem, um utilizador recebe apenas um ponteiro para esta mensagem; o ponteiro é armazenado na tabela User_messages. Isto é feito para evitar que o sistema de mensagens armazene múltiplas cópias de uma mensagem de correio electrónico no caso de ser enviada para muitos destinatários diferentes de cada vez. Mas e se um utilizador apagar uma mensagem da sua conta? Neste caso, apenas a respectiva entrada na tabela User_messages é realmente removida. Assim, para apagar completamente a mensagem, todos os registos de Mensagens_de_utilizador devem ser removidos.
Denormalização de dados numa das tabelas pode tornar isto muito mais simples: podemos adicionar uma contagem_de_utilizador_recebida à tabela de Mensagens para manter um registo de Mensagens_de_utilizador mantido para uma mensagem específica. Quando um utilizador apaga esta mensagem (ler: remove o ponteiro para a mensagem real), a coluna users_received_count é decretada por um. Naturalmente, quando a contagem_de_utilizadores_recebida_é igual a zero, a mensagem real pode ser apagada completamente.
Utilizar tabelas pré-juntas
Para tabelas pré-juntas, é necessário adicionar uma coluna não-chave a uma tabela que não tenha valor comercial. Desta forma, é possível evitar a junção de tabelas e, portanto, acelerar as consultas. No entanto, é necessário garantir que a coluna desnormalizada é actualizada sempre que o valor da coluna principal é alterado.
Esta técnica de desnormalização pode ser usada quando se tem de fazer muitas consultas contra muitas tabelas diferentes – e desde que os dados obsoletos sejam aceitáveis.
| Vantagens | Desvantagens |
|---|---|
| Não é necessário usar múltiplas uniões | DML é necessário para actualizar o nãocoluna desnormalizada |
| Pode adiar actualizações desde que os dados obsoletos sejam toleráveis | Uma coluna extra requer trabalho adicional e espaço em disco |
Exemplo

Imagine que os utilizadores do nosso serviço de mensagens de correio electrónico querem aceder a mensagens por categoria. Manter o nome de uma categoria direita na tabela User_messages pode poupar tempo e reduzir o número de entradas necessárias.
Na tabela desnormalizada acima, introduzimos a coluna category_name para armazenar informação sobre a categoria a que cada registo na tabela User_messages está relacionado. Graças à desnormalização, só é necessária uma consulta na tabela User_messages para permitir a um utilizador seleccionar todas as mensagens pertencentes a uma categoria específica. Claro que esta técnica de desnormalização tem um lado negativo – esta coluna extra pode requerer muito espaço de armazenamento.
Usar valores codificados
Se houver uma tabela de referência com registos constantes, pode codificá-los em código duro na sua aplicação. Desta forma, não precisa de juntar tabelas para ir buscar os valores de referência.
No entanto, ao utilizar valores codificados, deve criar uma restrição de verificação para validar os valores em relação aos valores de referência. Esta restrição deve ser reescrita sempre que for necessário um novo valor na tabela A.
Esta técnica de desnormalização de dados deve ser utilizada se os valores forem estáticos durante todo o ciclo de vida do seu sistema e desde que o número destes valores seja bastante reduzido. Agora vejamos os prós e os contras desta técnica:
| Vantagens | Desvantagens |
|---|---|
| Não é necessário implementar uma tabela de pesquisa | É necessário recodificar e restaurar se olhar…os valores acima são alterados |
| No se junta a uma tabela de pesquisa |
Exemplo

P>Ponhamos que precisamos de descobrir informações de fundo sobre os utilizadores de um serviço de mensagens de correio electrónico, por exemplo o tipo, ou tipo, de utilizador. Criámos uma tabela User_kinds para armazenar dados sobre os tipos de utilizadores que precisamos de reconhecer.
Os valores armazenados nesta tabela não são susceptíveis de ser alterados com frequência, pelo que podemos aplicar hardcoding. Podemos adicionar uma restrição de verificação à coluna ou construir a restrição de verificação no campo de validação para a aplicação onde os utilizadores entram no nosso serviço de mensagens de correio electrónico.
Keeping details with the master
Existem casos em que o número de registos de detalhe por master é fixo ou quando os registos de detalhe são consultados com o master. Nestes casos, é possível desnormalizar uma base de dados adicionando colunas de detalhes à tabela principal. Esta técnica revela-se mais útil quando há poucos registos na tabela de detalhes.
| Vantagens | Desvantagens |
|---|---|
| Não é necessário usar joins | Increased complexidade do DML |
| Poupa espaço |
Exemplo

Imagine que precisamos de limitar a quantidade máxima de espaço de armazenamento que um utilizador pode obter. Para o fazer, precisamos de implementar restrições no nosso serviço de mensagens electrónicas – uma para mensagens e outra para ficheiros. Uma vez que a quantidade de espaço de armazenamento permitida para cada uma destas restrições é diferente, precisamos de rastrear cada restrição individualmente. Numa base de dados relacional normalizada, poderíamos simplesmente introduzir duas tabelas diferentes – Tipos_de_armazenamento e Restrições_de_armazenamento – que armazenariam registos para cada utilizador.
Em vez disso, podemos seguir um caminho diferente e adicionar colunas desnormalizadas à tabela de Utilizadores:
message_space_allocated
message_space_available
file_space_allocated
file_space_available
Neste caso, a tabela de Utilizadores desnormalizados armazena não só a informação real sobre um utilizador mas também as restrições, pelo que em termos de funcionalidade a tabela não corresponde totalmente ao seu nome.
Repetir um único detalhe com o seu mestre
Quando se lida com dados históricos, muitas consultas necessitam de um único registo específico e raramente requerem outros detalhes. Com esta técnica de desnormalização da base de dados, pode introduzir uma nova coluna de chave estrangeira para armazenar este registo com o seu mestre. Ao utilizar este tipo de desnormalização, não se esqueça de adicionar código que actualizará a coluna desnormalizada quando um novo registo for adicionado.
| Vantagens | Desvantagens |
|---|---|
| Não é necessário criar adesões para consultas que necessitem um único registo | Oncoerências de dados são possíveis como um valor de registo deve ser repetido |
Exemplo
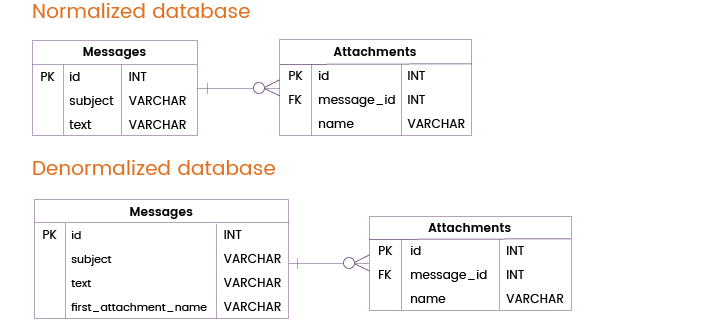
Muitas vezes, os utilizadores enviam não só mensagens mas também anexos. A maioria das mensagens é enviada sem anexo ou com um único anexo, mas em alguns casos os utilizadores anexam vários ficheiros a uma mensagem.
Podemos evitar a junção de uma tabela, desnormalizando a tabela de Mensagens através da adição da coluna do primeiro_nome_do_arquivo. Naturalmente, se uma mensagem contém mais do que um anexo, apenas o primeiro anexo será retirado da tabela Mensagens, enquanto outros anexos serão armazenados numa tabela separada Anexos e, por conseguinte, necessitarão de junções à tabela. Na maioria dos casos, contudo, esta técnica de desnormalização será realmente útil.
Adicionar chaves de curto-circuito
Se uma base de dados tiver mais de três níveis de detalhe principal e precisar de consultar apenas registos dos níveis mais baixos e mais altos, poderá desnormalizar a sua base de dados criando chaves de curto-circuito que liguem os registos dos netos de nível mais baixo aos registos dos avós de nível mais alto. Esta técnica ajuda-o a reduzir o número de uniões à tabela quando as consultas são executadas.
| Vantagens | Desvantagens |
|---|---|
| Menos tabelas são unidas durante as consultas | Need para usar mais chaves estrangeiras |
| Need extra code to ensure consistency of values |
Exemplo
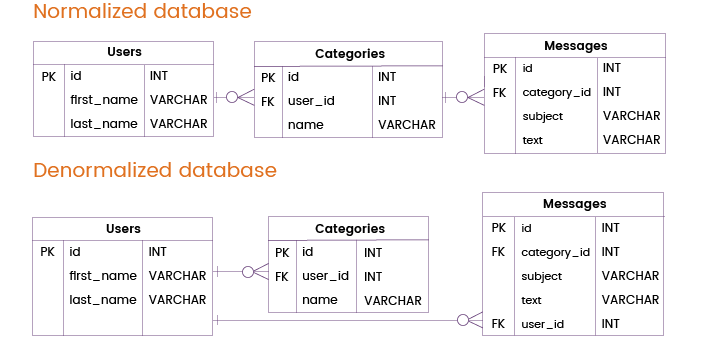
Agora vamos imaginar que um serviço de mensagens de correio electrónico tem de lidar com consultas frequentes que requerem dados apenas das tabelas Utilizadores e Mensagens, sem abordar a tabela de Categorias. Numa base de dados normalizada, tais consultas teriam de se juntar às tabelas de Utilizadores e Categorias.
Para melhorar o desempenho da base de dados e evitar tais junções, podemos adicionar uma chave primária ou única da tabela de Utilizadores directamente à tabela de Mensagens. Desta forma, podemos fornecer informações sobre utilizadores e mensagens sem consultar a tabela de Categorias, o que significa que podemos fazer sem uma tabela redundante de junção.
Drawbacks de desnormalização de bases de dados
Agora provavelmente está a pensar: desnormalizar ou não desnormalizar?
A desnormalização parece ser a melhor forma de aumentar o desempenho de uma base de dados e, consequentemente, de uma aplicação em geral, só se deve recorrer a ela quando outros métodos se revelarem ineficientes. Por exemplo, o desempenho muitas vezes insuficiente da base de dados pode ser causado por consultas escritas incorrectamente, código de aplicação defeituoso, desenho de índice inconsistente, ou mesmo configuração incorrecta do hardware.
Desnormalização parece tentador e extremamente eficiente em teoria, mas vem com uma série de inconvenientes que deve estar ciente antes de seguir com esta estratégia:
- Espaço de armazenamento extra
Quando desnormaliza uma base de dados, tem de duplicar muitos dados. Naturalmente, a sua base de dados necessitará de mais espaço de armazenamento.
- Documentação adicional
Todos os passos que der durante a desnormalização devem ser devidamente documentados. Se alterar a concepção da sua base de dados algum tempo depois, terá de rever todas as regras que criou antes: poderá não precisar de algumas delas ou poderá ter de actualizar determinadas regras de desnormalização.
- potenciais anomalias de dados
Ao desnormalizar uma base de dados, deverá compreender que obtém mais dados que podem ser modificados. Consequentemente, é necessário tratar de cada caso de dados duplicados. Deve usar triggers, procedimentos armazenados e transacções para evitar anomalias de dados.
- Mais código
Quando desnormalizar uma base de dados, modifica consultas seleccionadas, e embora isto traga muitos benefícios, tem o seu preço – precisa de escrever código extra. Também precisa de actualizar valores em novos atributos que acrescenta aos registos existentes, o que significa que é necessário ainda mais código.
- Operações mais lentas
Desnormalização de bases de dados pode acelerar as recuperações de dados mas, ao mesmo tempo, torna as actualizações mais lentas. Se a sua aplicação precisar de efectuar muitas operações de escrita na base de dados, pode mostrar um desempenho mais lento do que uma base de dados normalizada semelhante. Portanto, certifique-se de implementar a desnormalização sem prejudicar a usabilidade da sua aplicação.
Dicas de desnormalização da base de dados
Como pode ver, a desnormalização é um processo sério que requer muito esforço e perícia. Se quiser desnormalizar bases de dados sem quaisquer problemas, siga estas dicas úteis:
- Em vez de tentar desnormalizar toda a base de dados imediatamente, concentre-se em partes particulares que pretende acelerar.
- Faça o seu melhor para aprender o desenho lógico da sua aplicação realmente bem para compreender que partes do seu sistema são susceptíveis de ser afectadas pela desnormalização.
- Analize a frequência com que os dados são alterados na sua aplicação; se os dados mudarem com demasiada frequência, a manutenção da integridade da sua base de dados após a desnormalização pode tornar-se um problema real.
- Veja atentamente que partes da sua aplicação estão a ter problemas de desempenho; muitas vezes, pode acelerar a sua aplicação através de consultas de afinação em vez de desnormalizar a base de dados.
- Aprenda mais sobre técnicas de armazenamento de dados; escolher as mais relevantes pode ajudá-lo a passar sem desnormalização.
Pensamentos finais
Deve sempre começar por construir uma base de dados limpa e normalizada de alto desempenho. Só se precisar da sua base de dados para desempenhar melhor determinadas tarefas (tais como a elaboração de relatórios) é que deve optar pela desnormalização. Se desnormalizar, tenha cuidado e certifique-se de documentar todas as alterações que fizer à base de dados.
Antes de optar pela desnormalização, faça a si mesmo as seguintes perguntas:
- Pode o meu sistema alcançar desempenho suficiente sem desnormalização?
- Pode o desempenho da minha base de dados tornar-se inaceitável depois de eu o desnormalizar?
- Pode o meu sistema tornar-se menos fiável?
Se a sua resposta a qualquer uma destas perguntas for sim, então é melhor que o faça sem desnormalização, pois é provável que se revele ineficaz para a sua aplicação. Se, no entanto, a desnormalização for a sua única opção, deve primeiro normalizar correctamente a base de dados, depois passar à desnormalização, seguindo cuidadosa e rigorosamente as técnicas que descrevemos neste artigo.
Para mais informações sobre as últimas tendências no desenvolvimento de software, subscreva o nosso blog.