Questo post copre le basi di Apache Parquet, che è un elemento importante nell’architettura dei big data. Per saperne di più sulla gestione dei file sull’object storage, date un’occhiata alla nostra guida al partizionamento dei dati su Amazon S3.
Nella conferenza Amazon re:Invent dello scorso anno (quando le conferenze reali erano ancora una cosa), AWS ha annunciato l’esportazione dei data lake – la possibilità di scaricare il risultato di una query Redshift su Amazon S3 in formato Apache Parquet. Nell’annuncio, AWS ha descritto Parquet come “2 volte più veloce da scaricare e consuma fino a 6 volte meno storage in Amazon S3, rispetto ai formati di testo”. La conversione dei dati in formati colonnari come Parquet o ORC è anche raccomandata come mezzo per migliorare le prestazioni di Amazon Athena.
È chiaro che Apache Parquet gioca un ruolo importante nelle prestazioni del sistema quando si lavora con i data lakes. Diamo uno sguardo più da vicino a ciò che Parquet è in realtà, e perché è importante per l’archiviazione e l’analisi dei big data.
Le basi: Cos’è Apache Parquet?
Apache Parquet è un formato di file progettato per supportare l’elaborazione veloce di dati complessi, con diverse caratteristiche degne di nota:
1. Colonnare: A differenza dei formati basati sulle righe come CSV o Avro, Apache Parquet è orientato alle colonne – il che significa che i valori di ogni colonna della tabella sono memorizzati uno accanto all’altro, piuttosto che quelli di ogni record:
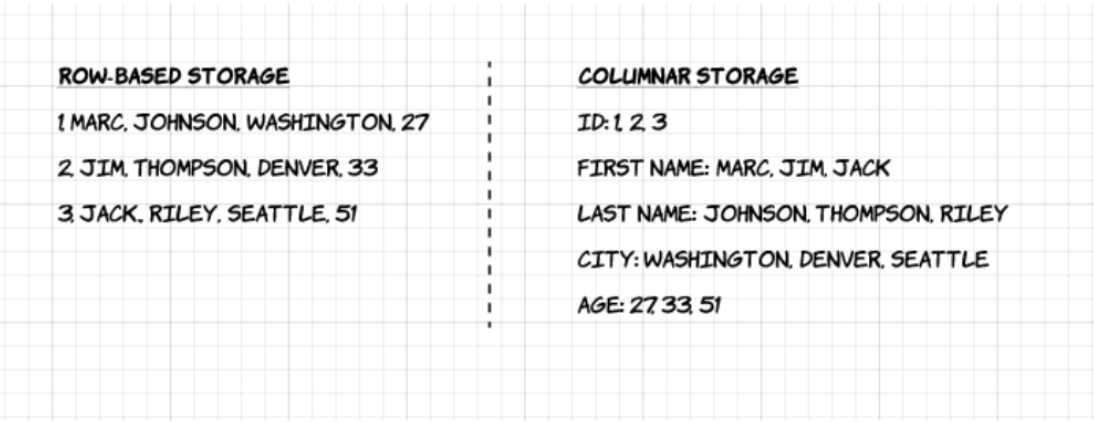
2. Open-source: Parquet è libero da usare e open source sotto la licenza Apache Hadoop, ed è compatibile con la maggior parte dei framework di elaborazione dati Hadoop.
3. Autodescrizione: In Parquet, i metadati che includono lo schema e la struttura sono incorporati in ogni file, rendendolo un formato di file auto-descrittivo.
Svantaggi dell’archiviazione colonnare Parquet
Le suddette caratteristiche del formato di file Apache Parquet creano diversi vantaggi distinti quando si tratta di archiviare e analizzare grandi volumi di dati. Vediamo alcuni di essi in modo più approfondito.
Compressione
La compressione dei file è l’atto di prendere un file e renderlo più piccolo. In Parquet, la compressione viene eseguita colonna per colonna ed è costruita per supportare opzioni di compressione flessibili e schemi di codifica estendibili per tipo di dati – ad esempio, si possono usare codifiche diverse per comprimere dati interi e stringhe.
I dati di Parquet possono essere compressi usando questi metodi di codifica:
- Codifica dizionario: è abilitata automaticamente e dinamicamente per dati con un piccolo numero di valori unici.
- Imballaggio di bit: La memorizzazione degli interi è di solito fatta con 32 o 64 bit dedicati per ogni intero. Questo permette una memorizzazione più efficiente di piccoli numeri interi.
- Run length encoding (RLE): quando lo stesso valore ricorre più volte, un singolo valore viene memorizzato una volta sola insieme al numero di occorrenze. Parquet implementa una versione combinata di bit packing e RLE, in cui la codifica cambia in base a quale produce i migliori risultati di compressione.

Performance
A differenza dei formati di file basati su righe come CSV, Parquet è ottimizzato per le performance. Quando si eseguono delle query sul file-system basato su Parquet, ci si può concentrare solo sui dati rilevanti molto rapidamente. Inoltre, la quantità di dati scansionati sarà molto più piccola e risulterà in un minore utilizzo di I/O. Per capire questo, guardiamo un po’ più in profondità come sono strutturati i file Parquet.
Come abbiamo detto sopra, Parquet è un formato auto-descritto, quindi ogni file contiene sia dati che metadati. I file Parquet sono composti da gruppi di righe, intestazione e piè di pagina. Ogni gruppo di righe contiene dati dalle stesse colonne. Le stesse colonne sono memorizzate insieme in ogni gruppo di righe:
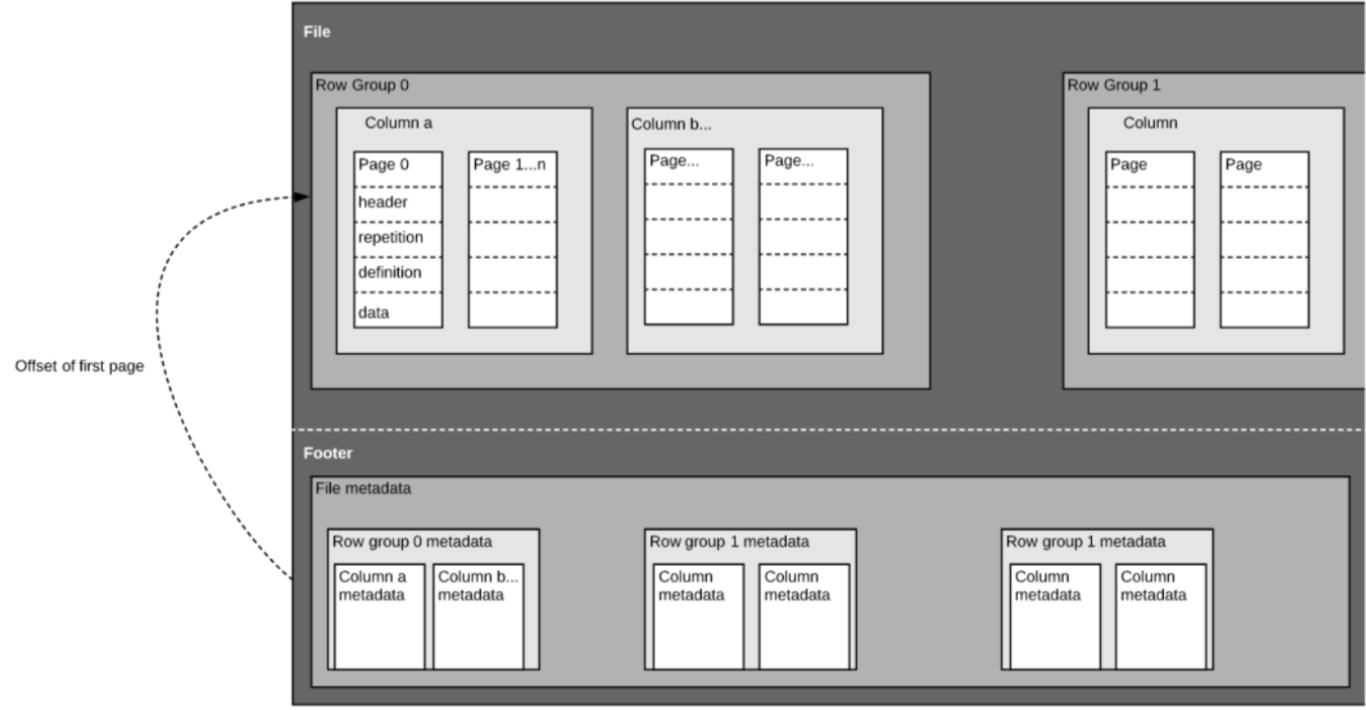
Questa struttura è ben ottimizzata sia per le prestazioni veloci delle query, sia per un basso I/O (riducendo al minimo la quantità di dati scansionati). Per esempio, se avete una tabella con 1000 colonne, che di solito interrogherete solo usando un piccolo sottoinsieme di colonne. L’utilizzo di file Parquet vi permetterà di recuperare solo le colonne necessarie e i loro valori, caricarle in memoria e rispondere alla query. Se si usasse un formato di file basato sulle righe come CSV, l’intera tabella dovrebbe essere caricata in memoria, con conseguente aumento dell’I/O e peggiori prestazioni.
Evoluzione dello schema
Quando si usano formati di file a colonne come Parquet, gli utenti possono iniziare con uno schema semplice, e aggiungere gradualmente più colonne allo schema secondo necessità. In questo modo, gli utenti possono ritrovarsi con più file Parquet con schemi diversi ma reciprocamente compatibili. In questi casi, Parquet supporta la fusione automatica degli schemi tra questi file.
Supporto open-source
Apache Parquet, come già detto, fa parte dell’ecosistema Apache Hadoop che è open-source e viene costantemente migliorato e supportato da una forte comunità di utenti e sviluppatori. Memorizzare i vostri dati in formati aperti significa evitare il vendor lock-in e aumentare la vostra flessibilità, rispetto ai formati di file proprietari utilizzati da molti moderni database ad alte prestazioni. Questo significa che è possibile utilizzare diversi motori di query come Amazon Athena, Qubole e Amazon Redshift Spectrum, all’interno della stessa architettura di data lake.
Column-oriented vs row-based storage per l’interrogazione analitica
I dati sono spesso generati e più facilmente concettualizzati in righe. Siamo abituati a pensare in termini di fogli di calcolo Excel, dove possiamo vedere tutti i dati rilevanti per un record specifico in una riga ordinata e organizzata. Tuttavia, per l’interrogazione analitica su larga scala, l’archiviazione a colonne presenta vantaggi significativi per quanto riguarda i costi e le prestazioni.
Dati complessi come i log e i flussi di eventi dovrebbero essere rappresentati come una tabella con centinaia o migliaia di colonne e molti milioni di righe. Memorizzare questa tabella in un formato basato sulle righe come CSV significherebbe:
- Le query impiegheranno più tempo per essere eseguite poiché è necessario scansionare più dati, piuttosto che interrogare solo il sottoinsieme di colonne di cui abbiamo bisogno per rispondere a una query (che tipicamente richiede un’aggregazione basata sulla dimensione o sulla categoria)
- Lo stoccaggio sarà più costoso poiché i CSV non sono compressi in modo efficiente come Parquet
I formati colonnari forniscono una migliore compressione e migliori prestazioni out-of-the-box, e consentono di interrogare i dati verticalmente – colonna per colonna.
Esempio: Parquet, CSV e Amazon Athena
Esamineremo questo esempio in modo molto più approfondito nel nostro prossimo webinar con Looker. Risparmiate il vostro posto qui.
Per dimostrare l’impatto dello storage colonnare Parquet rispetto alle alternative basate sulle righe, guardiamo cosa succede quando si usa Amazon Athena per interrogare i dati memorizzati su Amazon S3 in entrambi i casi.
Usando Upsolver, abbiamo ingerito un dataset CSV di log del server su S3. In una comune architettura AWS data lake, Athena verrebbe utilizzato per interrogare i dati direttamente da S3. Queste query possono poi essere visualizzate utilizzando strumenti interattivi di visualizzazione dei dati come Tableau o Looker.
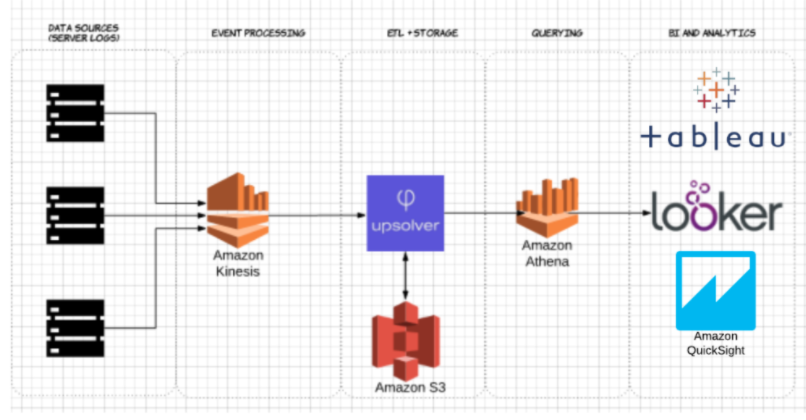
Abbiamo testato Athena contro lo stesso dataset memorizzato come CSV compresso e come Apache Parquet.
Questa è la query che abbiamo eseguito in Athena:
SELECT tags_host AS host_id, AVG(fields_usage_active) as avg_usage
FROM server_usage
GROUP BY tags_host
HAVING AVG(fields_usage_active) > 0
LIMIT 10
E i risultati:
| CSV | Parquet | Colonne | |
| Tempo di interrogazione (secondi) | 735 | 211 | 18 |
| Dati scansionati (GB) | 372.2 | 10.29 | 18 |
- CSV compressi: Il CSV compresso ha 18 colonne e pesa 27 GB su S3. Athena deve scansionare l’intero file CSV per rispondere alla query, quindi pagheremmo per 27 GB di dati scansionati. A scale più alte, questo avrebbe anche un impatto negativo sulle prestazioni.
- Parquet: Convertendo i nostri file CSV compressi in Apache Parquet, si finisce con una quantità simile di dati in S3. Tuttavia, poiché Parquet è colonnare, Athena ha bisogno di leggere solo le colonne che sono rilevanti per la query in esecuzione – un piccolo sottoinsieme dei dati. In questo caso, Athena ha dovuto scansionare 0,22 GB di dati, quindi invece di pagare per 27 GB di dati scansionati, paghiamo solo per 0,22 GB.
Utilizzare Parquet è sufficiente?
Utilizzare Parquet è un buon inizio; tuttavia, l’ottimizzazione delle query dei data lake non finisce qui. Spesso è necessario pulire, arricchire e trasformare i dati, eseguire join ad alta cardinalità e implementare una serie di best practice per garantire che le query trovino risposte coerenti in modo rapido ed economico.
È possibile utilizzare Upsolver per semplificare la pipeline ETL del data lake, ingerire automaticamente i dati come Parquet ottimizzato e trasformare i dati in streaming con funzioni SQL o Excel-like. Per saperne di più, programmate una demo proprio qui.
Vuoi saperne di più sull’ottimizzazione del tuo data lake? Dai un’occhiata ad alcune di queste best practice per i laghi di dati. Per vedere ulteriori benchmark e imparare le best practice per la preparazione dei dati per Athena, partecipa al prossimo webinar di Upsolver + Looker proprio qui.