La velocidad de los sitios web es una prioridad para las empresas en 2020.
Los sitios web más rápidos se clasifican mejor en los motores de búsqueda y también proporcionan mejores experiencias de usuario, lo que resulta en mayores tasas de conversión. No es de extrañar que los propietarios de sitios web exijan velocidades de carga de páginas más rápidas – dejando a los desarrolladores que lo hagan realidad.
La optimización de la base de datos es un paso esencial para mejorar el rendimiento del sitio web. Normalmente, los desarrolladores normalizan una base de datos relacional, lo que significa que la reestructuran para reducir la redundancia de datos y mejorar la integridad de los mismos. Sin embargo, a veces normalizar una base de datos no es suficiente, por lo que para mejorar aún más el rendimiento de la base de datos los desarrolladores hacen el camino inverso y recurren a la desnormalización de la base de datos.
En este artículo, nos adentramos en el tema de la desnormalización para saber cuándo es adecuado este método y cómo puedes hacerlo.
Cuándo desnormalizar una base de datos
¿Qué es la desnormalización de la base de datos? Antes de sumergirnos en el tema, hagamos hincapié en que la normalización sigue siendo el punto de partida, lo que significa que, en primer lugar, debes normalizar la estructura de una base de datos. La esencia de la normalización es poner cada dato en su lugar apropiado; esto asegura la integridad de los datos y facilita la actualización. Sin embargo, la recuperación de datos de una base de datos normalizada puede ser más lenta, ya que las consultas tienen que dirigirse a muchas tablas diferentes donde se almacenan distintos datos. La actualización, por el contrario, es más rápida, ya que todos los datos se almacenan en un único lugar.
La mayoría de las aplicaciones modernas necesitan poder recuperar datos en el menor tiempo posible. Y es entonces cuando se puede considerar la desnormalización de una base de datos relacional. Como su nombre indica, la desnormalización es lo contrario de la normalización. Cuando se normaliza una base de datos, se organizan los datos para garantizar la integridad y eliminar las redundancias. La desnormalización de la base de datos significa que usted pone deliberadamente los mismos datos en varios lugares, aumentando así la redundancia.
«¿Por qué desnormalizar una base de datos?», puede preguntarse. El objetivo principal de la desnormalización es acelerar significativamente la recuperación de datos. Sin embargo, la desnormalización no es una píldora mágica. Los desarrolladores deben utilizar esta herramienta sólo para fines particulares:
# 1 Para mejorar el rendimiento de las consultas
Típicamente, una base de datos normalizada requiere unir muchas tablas para obtener consultas; pero cuantas más uniones, más lenta es la consulta. Como contramedida, se puede añadir redundancia a una base de datos copiando valores entre las tablas padre e hija y, por tanto, reduciendo el número de uniones necesarias para una consulta.
#2 Para que una base de datos sea más cómoda de gestionar
Una base de datos normalizada no tiene valores calculados que son esenciales para las aplicaciones. Calcular estos valores sobre la marcha requeriría tiempo, ralentizando la ejecución de las consultas.
Se puede desnormalizar una base de datos para proporcionar valores calculados. Una vez generados y añadidos a las tablas, los programadores posteriores pueden crear fácilmente sus propios informes y consultas sin tener un conocimiento profundo del código o la API de la aplicación.
#3 Para facilitar y acelerar la elaboración de informes
A menudo, las aplicaciones necesitan proporcionar mucha información analítica y estadística. Generar informes a partir de datos en vivo lleva mucho tiempo y puede afectar negativamente al rendimiento general del sistema.
Denormalizar su base de datos puede ayudarle a superar este reto. Supongamos que necesita proporcionar un resumen total de ventas para uno o muchos usuarios; una base de datos normalizada agregaría y calcularía todos los detalles de las facturas varias veces. No hace falta decir que esto llevaría bastante tiempo, así que para acelerar este proceso, podría mantener el resumen de ventas del año hasta la fecha en una tabla que almacene los detalles de los usuarios.
Técnicas de desnormalización de la base de datos
Ahora que sabe cuándo debe recurrir a la desnormalización de la base de datos, probablemente se pregunte cómo hacerlo bien. Existen varias técnicas de desnormalización, cada una de ellas apropiada para una situación concreta. Vamos a explorarlas en profundidad:
Almacenamiento de datos derivables
Si necesita ejecutar un cálculo repetidamente durante las consultas, lo mejor es almacenar los resultados del mismo. Si el cálculo contiene registros de detalle, debe almacenar el cálculo derivado en la tabla maestra. Siempre que decida almacenar valores derivados, asegúrese de que los valores desnormalizados siempre sean recalculados por el sistema.
Aquí hay situaciones en las que almacenar valores derivables es apropiado:
- Cuando se necesitan frecuentemente valores derivables
- Cuando no se alteran frecuentemente los valores de origen
|
Ventajas
|
Desventajas |
|---|---|
| No es necesario necesidad de buscar valores de origen cada vez que se necesita un valor derivable | La ejecución de sentencias de lenguaje de manipulación de datos (DML) contra los datos de origen requiere recalcular los datos derivables | No es necesario realizar un cálculo para cada consulta o informe | Las inconsistencias de datos son posibles debido a la duplicación de datos |
Ejemplo

Como ejemplo de esta técnica de desnormalización, supongamos que estamos construyendo un servicio de mensajería de correo electrónico. Al recibir un mensaje, un usuario obtiene sólo un puntero a este mensaje; el puntero se almacena en la tabla User_messages. Esto se hace para evitar que el sistema de mensajería almacene múltiples copias de un mensaje de correo electrónico en caso de que se envíe a muchos destinatarios diferentes a la vez. ¿Pero qué pasa si un usuario borra un mensaje de su cuenta? En este caso, sólo se elimina la entrada correspondiente en la tabla User_messages. Así que para eliminar completamente el mensaje, hay que eliminar todos los registros de User_messages correspondientes.
La desnormalización de los datos en una de las tablas puede hacer esto mucho más sencillo: podemos añadir un users_received_count a la tabla Messages para mantener un registro de User_messages guardado para un mensaje específico. Cuando un usuario borra este mensaje (léase: elimina el puntero al mensaje real), la columna users_received_count se decrementa en uno. Naturalmente, cuando el users_received_count es igual a cero, el mensaje real puede ser eliminado por completo.
Usando tablas pre-unidas
Para pre-unir tablas, es necesario añadir una columna no clave a una tabla que no tiene ningún valor comercial. De este modo, se puede evitar la unión de tablas y, por tanto, acelerar las consultas. Sin embargo, debe asegurarse de que la columna desnormalizada se actualice cada vez que se modifique el valor de la columna maestra.
Esta técnica de desnormalización se puede utilizar cuando se tienen que hacer muchas consultas contra muchas tablas diferentes – y siempre que los datos antiguos sean aceptables.
| Desventajas | Desventajas |
|---|---|
| No es necesario utilizar joins múltiples | DML es necesario para actualizar la columna nodesnormalizada |
| Se pueden aplazar las actualizaciones mientras los datos antiguos sean tolerables | Una columna adicional requiere más trabajo y espacio en disco |
Ejemplo

Imagina que los usuarios de nuestro servicio de mensajería de correo electrónico quieren acceder a los mensajes por categorías. Mantener el nombre de una categoría justo en la tabla User_messages puede ahorrar tiempo y reducir el número de uniones necesarias.
En la tabla desnormalizada anterior, introducimos la columna category_name para almacenar la información sobre con qué categoría está relacionado cada registro de la tabla User_messages. Gracias a la desnormalización, sólo se requiere una consulta en la tabla User_messages para que un usuario pueda seleccionar todos los mensajes que pertenecen a una categoría específica. Por supuesto, esta técnica de desnormalización tiene una desventaja: esta columna extra puede requerir mucho espacio de almacenamiento.
Usando valores hardcoded
Si hay una tabla de referencia con registros constantes, puedes hardcodearlos en tu aplicación. De esta manera, no necesita unir tablas para obtener los valores de referencia.
Sin embargo, cuando se utilizan valores codificados, debe crear una restricción de verificación para validar los valores contra los valores de referencia. Esta restricción debe reescribirse cada vez que se requiera un nuevo valor en la tabla A.
Esta técnica de desnormalización de datos debe utilizarse si los valores son estáticos a lo largo del ciclo de vida de su sistema y siempre que el número de estos valores sea bastante pequeño. Ahora vamos a echar un vistazo a los pros y los contras de esta técnica:
| Desventajas | Desventajas |
|---|---|
| No es necesario implementar una tabla de búsqueda | Se requiere recodificar y replantear si los valores de búsquedavalores de búsqueda se alteran |
| No se unen a una tabla de búsqueda |
Ejemplo

Supongamos que necesitamos averiguar información de fondo sobre los usuarios de un servicio de mensajería electrónica, por ejemplo la clase, o tipo, de usuario. Hemos creado una tabla User_kinds para almacenar datos sobre los tipos de usuarios que necesitamos reconocer.
Los valores almacenados en esta tabla no es probable que cambien con frecuencia, por lo que podemos aplicar hardcoding. Podemos añadir una restricción de verificación a la columna o construir la restricción de verificación en la validación del campo para la aplicación en la que los usuarios se registran en nuestro servicio de mensajería de correo electrónico.
Mantener los detalles con el maestro
Puede haber casos en los que el número de registros de detalle por maestro sea fijo o cuando los registros de detalle se consulten con el maestro. En estos casos, se puede desnormalizar una base de datos añadiendo columnas de detalle a la tabla maestra. Esta técnica resulta más útil cuando hay pocos registros en la tabla de detalle.
| Desventajas | Desventajas |
|---|---|
| No es necesario utilizar joins | Aumento de la complejidad del DML |
| Ahorra espacio |
Ejemplo

Imagina que necesitamos limitar la cantidad máxima de espacio de almacenamiento que puede obtener un usuario. Para ello, necesitamos implementar restricciones en nuestro servicio de mensajería de correo electrónico: una para los mensajes y otra para los archivos. Dado que la cantidad de espacio de almacenamiento permitido para cada una de estas restricciones es diferente, tenemos que hacer un seguimiento de cada restricción individualmente. En una base de datos relacional normalizada, podríamos simplemente introducir dos tablas diferentes -Tipos_de_almacenamiento y Restricciones_de_almacenamiento- que almacenarían registros para cada usuario.
En cambio, podemos ir por un camino diferente y añadir columnas desnormalizadas a la tabla Usuarios:
espacio_de_mensaje_asignado
espacio_de_mensaje_disponible
espacio_de_archivo_asignado
espacio_de_archivo_disponible
En este caso, la tabla Usuarios desnormalizada almacena no sólo la información real de un usuario, sino también las restricciones, por lo que en términos de funcionalidad la tabla no se corresponde totalmente con su nombre.
Repetir un único detalle con su maestro
Cuando se trata de datos históricos, muchas consultas necesitan un único registro específico y rara vez requieren otros detalles. Con esta técnica de desnormalización de la base de datos, puede introducir una nueva columna de clave externa para almacenar este registro con su maestro. Cuando utilice este tipo de desnormalización, no olvide añadir código que actualice la columna desnormalizada cuando se añada un nuevo registro.
| Desventajas | Desventajas |
|---|---|
|
No es necesario crear uniones para las consultas que necesitan un solo registro
|
Es posible que se produzcan incoherencias en los datos al tener que repetir el valor de un registro |
Ejemplo
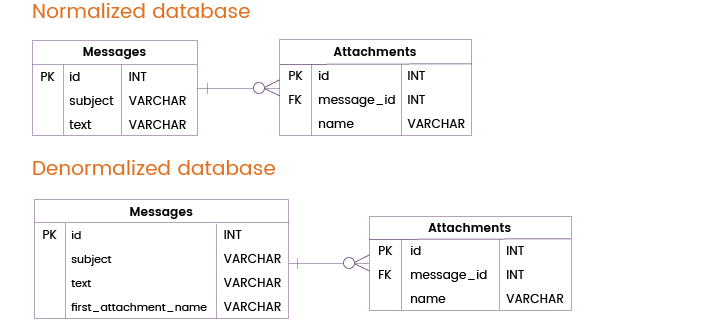
A menudo, los usuarios no sólo envían mensajes, sino también archivos adjuntos. La mayoría de los mensajes se envían sin adjunto o con un solo adjunto, pero en algunos casos los usuarios adjuntan varios archivos a un mensaje.
Podemos evitar una unión de tablas desnormalizando la tabla Mensajes mediante la adición de la columna first_attachment_name. Naturalmente, si un mensaje contiene más de un archivo adjunto, sólo el primer archivo adjunto se tomará de la tabla Mensajes mientras que los demás archivos adjuntos se almacenarán en una tabla separada de Adjuntos y, por lo tanto, requerirán uniones de tablas. Sin embargo, en la mayoría de los casos, esta técnica de desnormalización será realmente útil.
Añadir claves de cortocircuito
Si una base de datos tiene más de tres niveles de detalle maestro y necesita consultar sólo los registros de los niveles más bajos y más altos, puede desnormalizar su base de datos creando claves de cortocircuito que conecten los registros de los nietos de nivel más bajo con los registros de los abuelos de nivel superior. Esta técnica le ayuda a reducir el número de uniones de tablas cuando se ejecutan las consultas.
| Desventajas | Desventajas |
|---|---|
| Se unen menos tablas durante las consultas | Se necesitan utilizar más claves foráneas |
| Necesito código extra para asegurar la consistencia de los valores |
Ejemplo
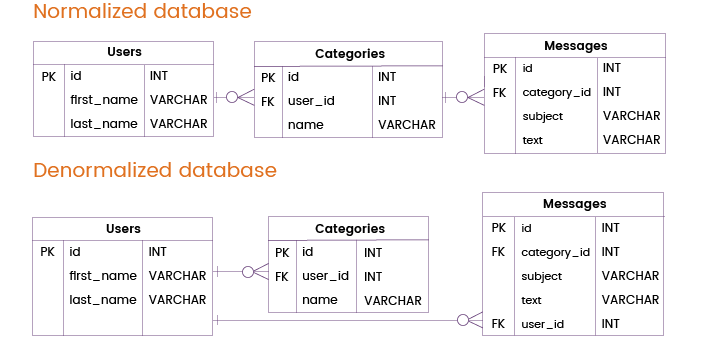
Ahora imaginemos que un servicio de mensajería de correo electrónico tiene que manejar consultas frecuentes que requieren datos de las tablas Usuarios y Mensajes solamente, sin dirigirse a la tabla Categorías. En una base de datos normalizada, dichas consultas necesitarían unir las tablas Usuarios y Categorías.
Para mejorar el rendimiento de la base de datos y evitar dichas uniones, podemos añadir una clave primaria o única de la tabla Usuarios directamente a la tabla Mensajes. De este modo, podemos proporcionar información sobre los usuarios y los mensajes sin consultar la tabla Categorías, lo que significa que podemos prescindir de una unión de tablas redundante.
Desventajas de la desnormalización de la base de datos
Ahora probablemente te estés preguntando: ¿desnormalizar o no desnormalizar?
Aunque la desnormalización parece la mejor manera de aumentar el rendimiento de una base de datos y, en consecuencia, de una aplicación en general, sólo debes recurrir a ella cuando otros métodos resulten ineficaces. Por ejemplo, a menudo el rendimiento insuficiente de la base de datos puede ser causado por consultas escritas incorrectamente, código de aplicación defectuoso, diseño de índices inconsistente o incluso una configuración de hardware inadecuada.
La desnormalización suena tentadora y extremadamente eficiente en teoría, pero viene con una serie de inconvenientes que debe conocer antes de seguir esta estrategia:
- Espacio de almacenamiento extra
Cuando desnormaliza una base de datos, tiene que duplicar muchos datos. Naturalmente, su base de datos requerirá más espacio de almacenamiento.
- Documentación adicional
- Cada uno de los pasos que dé durante la desnormalización debe estar debidamente documentado. Si cambia el diseño de su base de datos en algún momento posterior, tendrá que revisar todas las reglas que creó antes: es posible que no necesite algunas de ellas o que tenga que actualizar determinadas reglas de desnormalización.
- Anomalías potenciales en los datos
- Al desnormalizar una base de datos, debe entender que obtiene más datos que pueden ser modificados. En consecuencia, debe ocuparse de todos los casos de datos duplicados. Debe utilizar desencadenantes, procedimientos almacenados y transacciones para evitar anomalías en los datos.
- Más código
- Cuando se desnormaliza una base de datos se modifican las consultas de selección, y aunque esto aporta muchos beneficios tiene su precio: hay que escribir código adicional. También es necesario actualizar los valores de los nuevos atributos que se añaden a los registros existentes, lo que significa que se requiere aún más código.
- Operaciones más lentas
- La desnormalización de la base de datos puede acelerar las recuperaciones de datos, pero al mismo tiempo ralentiza las actualizaciones. Si su aplicación necesita realizar muchas operaciones de escritura en la base de datos, puede mostrar un rendimiento más lento que una base de datos normalizada similar. Así que asegúrese de implementar la desnormalización sin dañar la usabilidad de su aplicación.
Consejos para la desnormalización de bases de datos
Como puede ver, la desnormalización es un proceso serio que requiere mucho esfuerzo y habilidad. Si quieres desnormalizar bases de datos sin problemas, sigue estos útiles consejos:
- En lugar de intentar desnormalizar toda la base de datos de inmediato, céntrate en partes concretas que quieras acelerar.
- Haga todo lo posible para aprender el diseño lógico de su aplicación realmente bien para entender qué partes de su sistema es probable que se vean afectadas por la desnormalización.
- Analice con qué frecuencia se cambian los datos en su aplicación; si los datos cambian con demasiada frecuencia, mantener la integridad de su base de datos después de la desnormalización podría convertirse en un verdadero problema.
- Eche un vistazo a qué partes de su aplicación tienen problemas de rendimiento; a menudo, puede acelerar su aplicación ajustando las consultas en lugar de desnormalizar la base de datos.
- Aprenda más sobre las técnicas de almacenamiento de datos; elegir las más relevantes puede ayudarle a prescindir de la desnormalización.
Pensamientos finales
Siempre debe empezar por construir una base de datos normalizada limpia y de alto rendimiento. Sólo si necesitas que tu base de datos rinda más en tareas concretas (como la elaboración de informes) deberías optar por la desnormalización. Si desnormaliza, tenga cuidado y asegúrese de documentar todos los cambios que realice en la base de datos.
Antes de optar por la desnormalización, hágase las siguientes preguntas:
- ¿Puede mi sistema alcanzar un rendimiento suficiente sin desnormalización?
- ¿Podría el rendimiento de mi base de datos volverse inaceptable después de desnormalizarla?
- ¿Mi sistema se volverá menos fiable?
Si su respuesta a cualquiera de estas preguntas es afirmativa, entonces será mejor que prescinda de la desnormalización, ya que es probable que resulte ineficiente para su aplicación. Si, por el contrario, la desnormalización es tu única opción, primero debes normalizar la base de datos correctamente, y luego pasar a desnormalizarla, siguiendo cuidadosa y estrictamente las técnicas que hemos descrito en este artículo.
Para conocer más tendencias en el desarrollo de software, suscríbete a nuestro blog.