Una pregunta común que veo de mucha gente nueva en T-SQL es cómo encontrar datos en una cadena y extraerlos. Esta es una petición muy común, ya que nuestras bases de datos contienen muchas cadenas. A menudo nos encontramos con que la gente que utiliza aplicaciones incrusta información en una cadena, con la expectativa de que el programa será capaz de eliminar fácilmente esa información más tarde. En este artículo, voy a ver cómo extraer estos datos utilizando SUBSTRING, CHARINDEX y PATINDEX.
Este es un artículo de vuelta a lo básico que espero que sea útil para aquellos desarrolladores y DBAs que son nuevos en SQL Server y buscan mejorar sus habilidades. Siéntase libre de pasar esto.
Encuentre el PO consistente
Un ejemplo es un número de factura o número de PO. A menudo he visto estos datos incrustados en campos de texto, con un requisito posterior para extraer este número del campo. Este es un tipo común de datos que se añade a un campo en una tabla en algún lugar, como en una tabla de Clientes. Es posible que los usuarios, o una aplicación, decidan añadir estos datos para desnormalizar nuestros datos.
Supongamos que tenemos una tabla que contiene información como esta:
CREATE TABLE Customers( CustomerID INT, CustomerName VARCHAR(500), CustomerNotes VARCHAR(MAX), Active TINYINT);GOINSERT dbo.Customers ( CustomerID , CustomerName , CustomerNotes , Active ) VALUES ( 1, 'Acme Inc', 'Last PO:20154402', 1) , ( 2, 'Roadrunner Enterprises', 'Last PO:20140322', 1 ) , ( 3, 'Wile E. Coyote and Sons', 'Unreliable payments', 0)
Si miro los datos, vemos que alguien ha decidido incluir información importante en el campo notas. Estoy seguro de que mucha gente experimentada se acobardará ante este uso de los campos de una tabla, pero esto ocurre más a menudo de lo que a muchos nos gustaría.
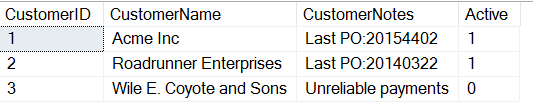
Si ahora quiero sacar la OP de este campo, quizás para un informe que sea necesario, o quizás porque voy a ETL estos datos a un lugar más apropiado, puedo utilizar la función SUBSTRING en T-SQL. Utilizo esta función cuando sé dónde dentro de una cadena estoy buscando obtener datos.
En este caso, puedo ver que los primeros 8 caracteres del campo CustomerNotes suelen ser «Last PO:». Con esto, puedo empezar en el noveno carácter y luego obtener los siguientes 8 caracteres (longitud del PO). Usaré esta consulta.
SELECT CustomerID , 'PO' = SUBSTRING(CustomerNotes, 9, 8)FROM dbo.Customers
Esto me devolverá los POs, pero obtengo otros datos.
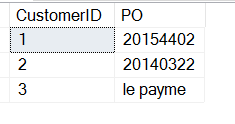
No te preocupes, puedo filtrar esto fácilmente (una discusión para otro artículo).
SELECT CustomerID , 'PO' = SUBSTRING(CustomerNotes, 9, 8)FROM dbo.Customers WHERE customerNotes LIKE '%PO%'
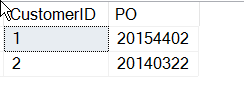
Ahora, ya he terminado, ¿no? Bueno, puede que no.
Un PO inconsistente
En los datos que he mirado hasta ahora, el número de PO está siempre en el lugar correcto. Sin embargo, supongamos que no todas nuestras personas de entrada de datos trabajan con los clientes de la misma manera. Aquí un poco más de datos para mostrar lo que quiero decir:
INSERT dbo.Customers ( CustomerID , CustomerName , CustomerNotes , Active ) VALUES ( 4, 'Beep Beep Enterprises', 'Remember their slogan: We go fast. Last PO:20154402', 1) , ( 5, 'Goldberg Supplies', 'Preferred. Last PO:20140322', 1 ) , ( 6, 'Bugs Deliveries', 'Fast Last PO:20145554', 0)
Ahora vamos a ejecutar nuestro script de arriba. Obtenemos estos datos:
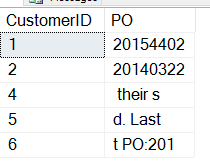
No es exactamente lo que queremos. El problema aquí es que el inicio del SUBSTRING no es el que queremos. Necesitamos empezar con la ubicación del número de pedido, quizás con la ubicación de «PO:». ¿Cómo podemos conseguirlo?
Tenemos un par de opciones, pero introduce CHARINDEX y PATINDEX. Ambos nos permiten buscar una cadena y encontrar otra dentro de ella. Cualquiera de ellas puede funcionar aquí, pero déjame mostrarte cómo funcionan en nuestros datos de prueba. Ejecutaré esta consulta:
SELECT CustomerID , CustomerNotes , 'Charindex_StartPO' = CHARINDEX('PO:', CustomerNotes) , 'Patindex_StartPO' = PATINDEX('%PO:%', CustomerNotes) , 'PO' = SUBSTRING(CustomerNotes, 9, 8) FROM dbo.Customers
Y obtendré estos resultados:
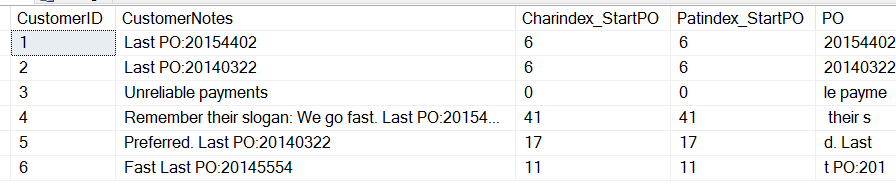
Nota que aquí podemos ver que ambas funciones devuelven el mismo valor, la posición inicial de la «P» en «PO». Hay algunas diferencias. CHARINDEX puede empezar en una posición determinada de la cadena mientras que PATINDEX puede tomar comodines. En este caso simplista, podemos usar cualquiera de los dos.
Usaré CHARINDEX aquí, y alteraré mi consulta a esto:
SELECT CustomerID , 'PO' = SUBSTRING(CustomerNotes, CHARINDEX('PO:', CustomerNotes), 8) FROM dbo.Customers WHERE customerNotes LIKE '%PO%';
Eso me da esto, que no es lo que quiero.
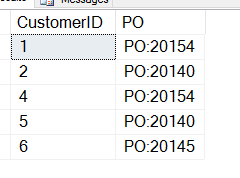
He olvidado que CHARINDEX me da la posición inicial de la OP, por lo que debo sumar a este valor. Aquí hay una consulta que funciona:
SELECT CustomerID , 'PO' = SUBSTRING(CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3, 8) FROM dbo.Customers WHERE customerNotes LIKE '%PO%';
Nota que he sumado 3 al resultado de la función CHARINDEX. Estos son los resultados:
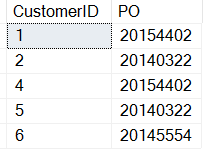
El pedido crece
Parece que esta es una buena consulta, pero imaginemos que añadimos un poco más de datos.
Nota que en este caso, tenemos pedidos que han crecido en tamaño. Algunos tienen 8 caracteres y otros 9. Ciertamente podemos coger sólo 9 caracteres, pero podríamos crecer hasta 10 o más. Además, tenemos otras notas después del pedido en lugares.
Modifiquemos nuestra consulta para ver qué podemos hacer. He añadido un giro a mi CHARINDEX.
SELECT CustomerID , CustomerNotes , 'Start of PO' = CHARINDEX('PO:', CustomerNotes)+3 , 'End of PO' = CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) , 'PO' = SUBSTRING(CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3, 8) FROM dbo.Customers WHERE customerNotes LIKE '%PO%';
Aquí están los resultados:
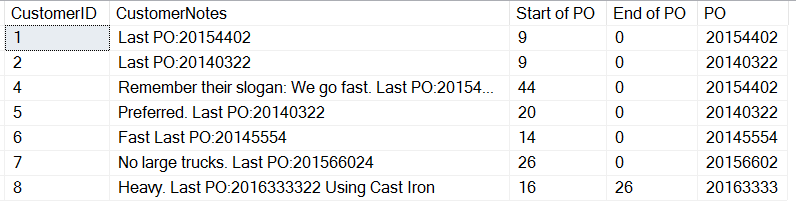
Si nos fijamos bien, vemos que nuestra última entrada, con texto después del PO nos da un resultado CHARINDEX. Esto es porque estamos buscando una cadena, obtenemos un 0 si no se encuentra ninguna entrada. Sólo el cliente 8 tiene un espacio después del PO. Esto significa que podemos calcular la longitud del PO para la última entrada, pero ¿qué pasa con todas las otras entradas que tienen un formato diferente?
Podemos utilizar una sentencia CASE aquí, ya que tenemos dos posibilidades aquí. Un CASE comprobará si hay un espacio y devolverá el índice del espacio dentro de la cadena. La otra devolverá la longitud de la propia cadena, cuando no exista ningún espacio. Esto me da un código como este:
Actualización: Mis cálculos eran incorrectos. Cambié de -3, a -2 en el código de abajo.
SELECT CustomerID , CustomerNotes , 'Start of PO' = CHARINDEX('PO:', CustomerNotes)+3 , 'End of PO' = CASE WHEN CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) = 0 THEN LEN(CustomerNotes) ELSE CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) END , 'Real End of PO' = CASE WHEN CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) = 0 THEN LEN(customernotes) ELSE CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) END - CHARINDEX('PO:', CustomerNotes) , 'PO' = SUBSTRING(CustomerNotes , CHARINDEX('PO:', CustomerNotes)+3 , CASE WHEN CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) = 0 THEN LEN(customernotes) ELSE CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) END - CHARINDEX('PO:', CustomerNotes) - 2 ) FROM dbo.Customers WHERE customerNotes LIKE '%PO%';
Si miramos este código, es muy similar al código SUBSTRING que usamos antes, pero ahora en lugar de una longitud fija, 8, para el número de caracteres a devolver, estamos devolviendo valores con una fórmula. La fórmula es esencialmente el final real de la OP (la 5ª columna en el conjunto de resultados) y el inicio de la OP. Hay una sentencia CASE para cuando obtenemos un cero.
Ahora si hacemos las cuentas, podemos ver la longitud de cada OP. Para la mayoría de los POs son 8 caracteres (11 caracteres después del inicio de la «P» en «PO:»), pero 9 caracteres para el cliente 7 y 11 para el cliente 8.
Algunos os preguntaréis por el -3 en el código, pero si recordáis las reglas de la aritmética, en realidad he llevado el menos a la cantidad que representa el inicio del número del PO.
Conclusión
Este no es el final de las posibilidades para los POs incrustados en el campo de notas a. Podría tener algo como «PO de prueba: 201530444. Nueva prueba» y eso causaría problemas con nuestro código. De hecho, hay un montón de otros casos que tendría que manejar en el mundo real.
Este artículo surgió de unos cuantos problemas de extracción de cadenas que he tenido que resolver en el mundo real, y este tipo de problemas ocurren. Espero haberte dado algunas habilidades para practicar que te ayudarán en tu manipulación de cadenas de SQL Server.
Como con cualquier técnica que puedas aprender aquí, asegúrate de evaluar el impacto en el rendimiento. Ejecuta tu código contra un gran conjunto de datos de prueba y determina qué tan bien puede funcionar esta técnica frente a otras. Le recomiendo que utilice una tabla de recuento para generar datos a una escala mayor que sus tablas de producción.
Las manipulaciones de cadenas pueden ser computacionalmente costosas en SQL Server, así que asegúrese de comprender el impacto de sus elecciones antes de desplegar el código en un sistema de producción.