El interés por el aprendizaje automático se ha disparado en los años transcurridos desde que el artículo de Harvard Business Review nombró al ‘Científico de datos’ el ‘Trabajo más sexy del siglo XXI’. Pero si te estás iniciando en el aprendizaje automático, puede ser un poco difícil entrar en él. Por eso estamos reiniciando nuestro inmensamente popular post sobre buenos algoritmos de aprendizaje automático para principiantes.
(Este post fue publicado originalmente en KDNuggets como Los 10 algoritmos que los ingenieros de aprendizaje automático deben conocer. Se ha vuelto a publicar con permiso, y se actualizó por última vez en 2019).
Este post está dirigido a principiantes. Si tienes algo de experiencia en ciencia de datos y aprendizaje automático, quizá te interese más este tutorial más profundo sobre cómo hacer aprendizaje automático en Python con scikit-learn, o nuestros cursos de aprendizaje automático, que empiezan aquí. Si aún no tienes claras las diferencias entre «ciencia de datos» y «aprendizaje automático», este artículo ofrece una buena explicación: aprendizaje automático y ciencia de datos: ¿en qué se diferencian?
Los algoritmos de aprendizaje automático son programas que pueden aprender de los datos y mejorar a partir de la experiencia, sin intervención humana. Las tareas de aprendizaje pueden incluir el aprendizaje de la función que asigna la entrada a la salida, el aprendizaje de la estructura oculta en los datos no etiquetados; o el «aprendizaje basado en instancias», en el que se produce una etiqueta de clase para una nueva instancia mediante la comparación de la nueva instancia (fila) con las instancias de los datos de entrenamiento, que se almacenaron en la memoria. El ‘aprendizaje basado en instancias’ no crea una abstracción a partir de instancias específicas.
Tipos de algoritmos de aprendizaje automático
Hay 3 tipos de algoritmos de aprendizaje automático (ML):
Algoritmos de aprendizaje supervisado:
El aprendizaje supervisado utiliza datos de entrenamiento etiquetados para aprender la función de mapeo que convierte las variables de entrada (X) en la variable de salida (Y). En otras palabras, resuelve f en la siguiente ecuación:
Esto nos permite generar salidas con precisión cuando se dan nuevas entradas.
Hablaremos de dos tipos de aprendizaje supervisado: clasificación y regresión.
La clasificación se utiliza para predecir el resultado de una muestra dada cuando la variable de salida está en forma de categorías. Un modelo de clasificación podría observar los datos de entrada y tratar de predecir etiquetas como «enfermo» o «sano».
La regresión se utiliza para predecir el resultado de una muestra dada cuando la variable de salida está en forma de valores reales. Por ejemplo, un modelo de regresión podría procesar datos de entrada para predecir la cantidad de lluvia, la altura de una persona, etc.
Los primeros 5 algoritmos que cubrimos en este blog -Regresión Lineal, Regresión Logística, CART, Naïve-Bayes y K-Nearest Neighbors (KNN)- son ejemplos de aprendizaje supervisado.
El ensamblaje es otro tipo de aprendizaje supervisado. Significa combinar las predicciones de múltiples modelos de aprendizaje automático que son individualmente débiles para producir una predicción más precisa sobre una nueva muestra. Los algoritmos 9 y 10 de este artículo – Bagging con Random Forests, Boosting con XGBoost – son ejemplos de técnicas de ensamblaje.
Algoritmos de aprendizaje no supervisado:
Los modelos de aprendizaje no supervisado se utilizan cuando sólo tenemos las variables de entrada (X) y ninguna variable de salida correspondiente. Utilizan datos de entrenamiento no etiquetados para modelar la estructura subyacente de los datos.
Hablaremos de tres tipos de aprendizaje no supervisado:
La asociación se utiliza para descubrir la probabilidad de la co-ocurrencia de elementos en una colección. Se utiliza ampliamente en el análisis de la cesta de mercado. Por ejemplo, un modelo de asociación puede usarse para descubrir que si un cliente compra pan, tiene un 80% de probabilidades de comprar también huevos.
El clustering se usa para agrupar muestras de forma que los objetos de un mismo cluster sean más similares entre sí que a los objetos de otro cluster.
La reducción de la dimensionalidad se usa para reducir el número de variables de un conjunto de datos asegurando que la información importante se siga transmitiendo. La reducción de la dimensionalidad puede realizarse mediante métodos de extracción de características y métodos de selección de características. La selección de características selecciona un subconjunto de las variables originales. La extracción de características realiza la transformación de los datos de un espacio de alta dimensión a un espacio de baja dimensión. Ejemplo: El algoritmo PCA es un enfoque de Extracción de Características.
Los algoritmos 6-8 que cubrimos aquí – Apriori, K-means, PCA – son ejemplos de aprendizaje no supervisado.
Aprendizaje por refuerzo:
El aprendizaje por refuerzo es un tipo de algoritmo de aprendizaje automático que permite a un agente decidir la mejor acción siguiente en función de su estado actual mediante el aprendizaje de comportamientos que maximicen una recompensa.
Los algoritmos de refuerzo suelen aprender las acciones óptimas a través de ensayo y error. Imagínese, por ejemplo, un videojuego en el que el jugador tiene que desplazarse a ciertos lugares en determinados momentos para ganar puntos. Un algoritmo de refuerzo que jugara a ese juego empezaría moviéndose de forma aleatoria pero, con el tiempo, a través de la prueba y el error, aprendería dónde y cuándo necesita mover al personaje del juego para maximizar su total de puntos.
Cuantificando la popularidad de los algoritmos de aprendizaje automático
¿De dónde hemos sacado estos diez algoritmos? Cualquier lista de este tipo será inherentemente subjetiva. Estudios como estos han cuantificado los 10 algoritmos de minería de datos más populares, pero todavía se basan en las respuestas subjetivas de los encuestados, generalmente profesionales académicos avanzados. Por ejemplo, en el estudio vinculado anteriormente, las personas encuestadas fueron los ganadores del Premio a la Innovación ACM KDD, el Premio a las Contribuciones de Investigación IEEE ICDM; los miembros del Comité de Programa de la KDD ’06, ICDM ’06, y SDM ’06; y los 145 asistentes a la ICDM ’06.
Los 10 algoritmos más populares enumerados en este post se eligen pensando en los principiantes del aprendizaje automático. Son principalmente algoritmos que aprendí en el curso ‘Data Warehousing and Mining’ (DWM) durante mi licenciatura en Ingeniería Informática en la Universidad de Mumbai. He incluido los 2 últimos algoritmos (métodos de conjunto) particularmente porque se utilizan con frecuencia para ganar las competiciones de Kaggle.
Sin más preámbulos, los 10 mejores algoritmos de aprendizaje automático para principiantes:
1. Regresión lineal
En el aprendizaje automático, tenemos un conjunto de variables de entrada (x) que se utilizan para determinar una variable de salida (y). Existe una relación entre las variables de entrada y la variable de salida. El objetivo del ML es cuantificar esta relación.

En la Regresión Lineal, la relación entre las variables de entrada (x) y la variable de salida (y) se expresa como una ecuación de la forma y = a + bx. Así, el objetivo de la regresión lineal es averiguar los valores de los coeficientes a y b. Aquí, a es la intercepción y b es la pendiente de la recta.
La figura 1 muestra los valores de x e y trazados para un conjunto de datos. El objetivo es ajustar una línea que se acerque a la mayoría de los puntos. Esto reduciría la distancia («error») entre el valor y de un punto de datos y la línea.
2. Regresión logística
Las predicciones de regresión lineal son valores continuos (por ejemplo, la lluvia en cm), las predicciones de regresión logística son valores discretos (por ejemplo, si un estudiante aprobó/reprobó) después de aplicar una función de transformación.
La regresión logística es más adecuada para la clasificación binaria: conjuntos de datos donde y = 0 o 1, donde 1 denota la clase por defecto. Por ejemplo, al predecir si un evento ocurrirá o no, sólo hay dos posibilidades: que ocurra (que denotamos como 1) o que no ocurra (0). Por lo tanto, si predijéramos si un paciente está enfermo, etiquetaríamos a los pacientes enfermos utilizando el valor de 1 en nuestro conjunto de datos.
La regresión logística recibe su nombre de la función de transformación que utiliza, que se llama función logística h(x)= 1/ (1 + ex). Esto forma una curva en forma de S.
En la regresión logística, la salida toma la forma de probabilidades de la clase predeterminada (a diferencia de la regresión lineal, donde la salida se produce directamente). Al ser una probabilidad, la salida se encuentra en el rango de 0-1. Así que, por ejemplo, si estamos tratando de predecir si los pacientes están enfermos, ya sabemos que los pacientes enfermos se denotan como 1, por lo que si nuestro algoritmo asigna la puntuación de 0,98 a un paciente, piensa que ese paciente es bastante probable que esté enfermo.
Esta salida (valor y) se genera mediante la transformación logarítmica del valor x, utilizando la función logística h(x)= 1/ (1 + e^ -x) . A continuación, se aplica un umbral para forzar esta probabilidad en una clasificación binaria.
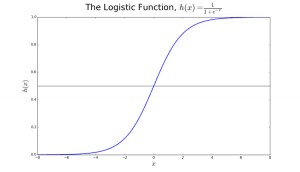
Figura 2: Regresión logística para determinar si un tumor es maligno o benigno. Se clasifica como maligno si la probabilidad h(x)>= 0,5. Fuente
En la Figura 2, para determinar si un tumor es maligno o no, la variable por defecto es y = 1 (tumor = maligno). La variable x podría ser una medida del tumor, como el tamaño del mismo. Como se muestra en la figura, la función logística transforma el valor x de las distintas instancias del conjunto de datos, en el rango de 0 a 1. Si la probabilidad cruza el umbral de 0,5 (mostrado por la línea horizontal), el tumor se clasifica como maligno.
La ecuación de regresión logística P(x) = e ^ (b0 +b1x) / (1 + e(b0 + b1x)) puede transformarse en ln(p(x) / 1-p(x)) = b0 + b1x.
El objetivo de la regresión logística es utilizar los datos de entrenamiento para encontrar los valores de los coeficientes b0 y b1 de forma que se minimice el error entre el resultado predicho y el resultado real. Estos coeficientes se estiman mediante la técnica de Estimación de Máxima Verosimilitud.
3. CART
Los Árboles de Clasificación y Regresión (CART) son una implementación de los Árboles de Decisión.
Los nodos no terminales de los Árboles de Clasificación y Regresión son el nodo raíz y el nodo interno. Los nodos terminales son los nodos hoja. Cada nodo no terminal representa una única variable de entrada (x) y un punto de división en esa variable; los nodos hoja representan la variable de salida (y). El modelo se utiliza de la siguiente manera para hacer predicciones: recorre las divisiones del árbol hasta llegar a un nodo hoja y emite el valor presente en el nodo hoja.
El árbol de decisión de la Figura 3 que aparece a continuación clasifica si una persona comprará un coche deportivo o un monovolumen en función de su edad y estado civil. Si la persona tiene más de 30 años y no está casada, recorremos el árbol de la siguiente manera : ‘¿más de 30 años?’ -> sí -> ‘¿casado?’ -> no. Por lo tanto, el modelo da como resultado un coche deportivo.
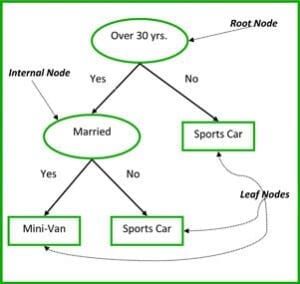
Figura 3: Partes de un árbol de decisión. Fuente
4. Naïve Bayes
Para calcular la probabilidad de que ocurra un evento, dado que ya ha ocurrido otro, utilizamos el Teorema de Bayes. Para calcular la probabilidad de que la hipótesis(h) sea cierta, dado nuestro conocimiento previo(d), utilizamos el Teorema de Bayes de la siguiente manera:
donde:
- P(h|d) = Probabilidad posterior. La probabilidad de que la hipótesis h sea verdadera, dados los datos d, donde P(h|d)= P(d1| h) P(d2| h)….P(dn| h) P(d)
- P(d|h) = Probabilidad. La probabilidad de los datos d dado que la hipótesis h era verdadera.
- P(h) = Probabilidad a priori de la clase. La probabilidad de que la hipótesis h sea verdadera (independientemente de los datos)
- P(d) = Probabilidad a priori del predictor. Probabilidad de los datos (independientemente de la hipótesis)
- 5 técnicas de aprendizaje supervisado- Regresión Lineal, Regresión Logística, CART, Naïve Bayes, KNN.
- 3 técnicas de aprendizaje no supervisado- Apriori, K-means, PCA.
- 2 técnicas de ensamblaje- Bagging con Random Forests, Boosting con XGBoost.
Este algoritmo se denomina «ingenuo» porque asume que todas las variables son independientes entre sí, lo cual es una suposición ingenua en los ejemplos del mundo real.
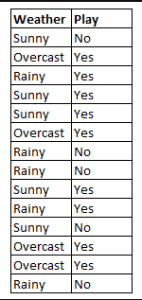
Figura 4: Uso de Naive Bayes para predecir el estado de ‘play’ utilizando la variable ‘weather’.
Usando la Figura 4 como ejemplo, ¿cuál es el resultado si weather = ‘sunny’?
Para determinar el resultado juego = ‘sí’ o ‘no’ dado el valor de la variable tiempo = ‘soleado’, calcule P(sí|sol) y P(no|sol) y elija el resultado con mayor probabilidad.
->P(sí|sol) = (P(soleado|sí) * P(sí)) / P(soleado) = (3/9 * 9/14 ) / (5/14) = 0,60
-> P(no|sol) = (P(soleado|no) * P(no)) / P(soleado) = (2/5 * 5/14 ) / (5/14) = 0,40
Así, si el tiempo = ‘soleado’, el resultado es juego = ‘sí’.
5. KNN
El algoritmo K-Nearest Neighbors utiliza todo el conjunto de datos como conjunto de entrenamiento, en lugar de dividir el conjunto de datos en un conjunto de entrenamiento y un conjunto de prueba.
Cuando se requiere un resultado para una nueva instancia de datos, el algoritmo KNN recorre todo el conjunto de datos para encontrar las instancias más cercanas a la nueva instancia, o el número k de instancias más similares al nuevo registro, y luego emite la media de los resultados (para un problema de regresión) o la moda (clase más frecuente) para un problema de clasificación. El valor de k es especificado por el usuario.
La similitud entre instancias se calcula utilizando medidas como la distancia euclidiana y la distancia de Hamming.
Algoritmos de aprendizaje no supervisado
6. Apriori
El algoritmo Apriori se utiliza en una base de datos transaccional para extraer conjuntos de elementos frecuentes y luego generar reglas de asociación. Se utiliza popularmente en el análisis de la cesta de la compra, donde se comprueban las combinaciones de productos que coocurren frecuentemente en la base de datos. En general, escribimos la regla de asociación para «si una persona compra el artículo X, entonces compra el artículo Y» como : X -> Y.
Ejemplo: si una persona compra leche y azúcar, entonces es probable que compre café en polvo. Esto podría escribirse en forma de regla de asociación como: {leche,azúcar} -> café en polvo. Las reglas de asociación se generan después de cruzar el umbral de apoyo y confianza.

Figura 5: Fórmulas de apoyo, confianza y elevación para la regla de asociación X->Y.
La medida de soporte ayuda a podar el número de conjuntos de ítems candidatos a ser considerados durante la generación de conjuntos de ítems frecuentes. Esta medida de soporte se guía por el principio de Apriori. El principio Apriori establece que si un conjunto de elementos es frecuente, entonces todos sus subconjuntos también deben ser frecuentes.
7. K-means
K-means es un algoritmo iterativo que agrupa datos similares en clusters.Calcula los centroides de k clusters y asigna un punto de datos a aquel cluster que tenga la menor distancia entre su centroide y el punto de datos.

Figura 6: Pasos del algoritmo de K-means. Fuente
Así es como funciona:
Empezamos eligiendo un valor de k. Aquí, digamos k = 3. Luego, asignamos aleatoriamente cada punto de datos a cualquiera de los 3 clusters. Calculamos el centroide del cluster para cada uno de los clusters. Las estrellas rojas, azules y verdes denotan los centroides de cada uno de los 3 clusters.
A continuación, reasigne cada punto al centroide del cluster más cercano. En la figura anterior, los 5 puntos superiores se asignaron al clúster con el centroide azul. Siga el mismo procedimiento para asignar los puntos a los clusters que contienen los centroides rojos y verdes.
A continuación, calcule los centroides para los nuevos clusters. Los antiguos centroides son las estrellas grises; los nuevos centroides son las estrellas rojas, verdes y azules.
Por último, repita los pasos 2-3 hasta que no haya cambio de puntos de un cluster a otro. Una vez que no hay cambio durante 2 pasos consecutivos, salga del algoritmo K-means.
8. PCA
El Análisis de Componentes Principales (PCA) se utiliza para hacer que los datos sean fáciles de explorar y visualizar reduciendo el número de variables. Esto se hace capturando la máxima varianza de los datos en un nuevo sistema de coordenadas con ejes llamados «componentes principales».
Cada componente es una combinación lineal de las variables originales y es ortogonal entre sí. La ortogonalidad entre componentes indica que la correlación entre estos componentes es cero.
El primer componente principal captura la dirección de la máxima variabilidad en los datos. El segundo componente principal capta el resto de la varianza de los datos pero tiene variables no correlacionadas con el primer componente. Del mismo modo, todos los componentes principales sucesivos (PC3, PC4 y así sucesivamente) capturan la varianza restante mientras no están correlacionados con el componente anterior.
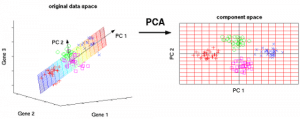
Figura 7: Las 3 variables originales (genes) se reducen a 2 nuevas variables denominadas componentes principales (PC’s). Fuente
Técnicas de aprendizaje de ensamblaje:
El ensamblaje significa combinar los resultados de múltiples aprendices (clasificadores) para mejorar los resultados, mediante la votación o el promedio. La votación se utiliza durante la clasificación y el promedio se utiliza durante la regresión. La idea es que los conjuntos de aprendices tienen un mejor rendimiento que los aprendices individuales.
Hay 3 tipos de algoritmos de ensamblaje: Bagging, Boosting y Stacking. No vamos a cubrir el ‘stacking’ aquí, pero si quieres una explicación detallada del mismo, aquí tienes una sólida introducción de Kaggle.
9. Bagging con bosques aleatorios
El primer paso en el bagging es crear múltiples modelos con conjuntos de datos creados mediante el método de muestreo Bootstrap. En el muestreo Bootstrap, cada conjunto de entrenamiento generado se compone de submuestras aleatorias del conjunto de datos original.
Cada uno de estos conjuntos de entrenamiento tiene el mismo tamaño que el conjunto de datos original, pero algunos registros se repiten varias veces y otros no aparecen en absoluto. A continuación, se utiliza todo el conjunto de datos original como conjunto de prueba. Así, si el tamaño del conjunto de datos original es N, entonces el tamaño de cada conjunto de entrenamiento generado también es N, con el número de registros únicos siendo aproximadamente (2N/3); el tamaño del conjunto de prueba también es N.
El segundo paso en el bagging es crear múltiples modelos utilizando el mismo algoritmo en los diferentes conjuntos de entrenamiento generados.
Aquí es donde entran los Bosques Aleatorios. A diferencia de un árbol de decisión, donde cada nodo se divide en la mejor característica que minimiza el error, en los Bosques Aleatorios, elegimos una selección aleatoria de características para construir la mejor división. La razón de la aleatoriedad es que, incluso con el embolsamiento, cuando los árboles de decisión eligen la mejor característica para la división, acaban con una estructura similar y predicciones correlacionadas. Pero el bagging después de dividir en un subconjunto aleatorio de características significa menos correlación entre las predicciones de los subárboles.
El número de características que se buscan en cada punto de división se especifica como un parámetro del algoritmo Random Forest.
Así, en el bagging con Random Forest, cada árbol se construye utilizando una muestra aleatoria de registros y cada división se construye utilizando una muestra aleatoria de predictores.
10. Boosting con AdaBoost
Adaboost significa Adaptive Boosting. El bagging es un ensemble paralelo porque cada modelo se construye de forma independiente. En cambio, el boosting es un ensemble secuencial donde cada modelo se construye en base a la corrección de las clasificaciones erróneas del modelo anterior.
El ensemble implica principalmente una «votación simple», en la que cada clasificador vota para obtener un resultado final -uno que está determinado por la mayoría de los modelos paralelos-; el boosting implica una «votación ponderada», en la que cada clasificador vota para obtener un resultado final que está determinado por la mayoría- pero los modelos secuenciales se construyeron asignando mayores pesos a las instancias mal clasificadas de los modelos anteriores.
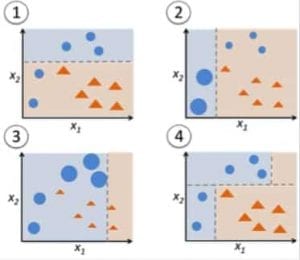
Figura 9: Adaboost para un árbol de decisión. Fuente
En la Figura 9, los pasos 1, 2, 3 implican un aprendiz débil llamado muñón de decisión (un árbol de decisión de 1 nivel que realiza una predicción basada en el valor de una sola característica de entrada; un árbol de decisión con su raíz inmediatamente conectada a sus hojas).
El proceso de construcción de aprendices débiles continúa hasta que se haya construido un número de aprendices débiles definido por el usuario o hasta que no haya más mejoras durante el entrenamiento. El paso 4 combina los 3 tocones de decisión de los modelos anteriores (y por lo tanto tiene 3 reglas de división en el árbol de decisión).
Primero, comienza con un tocón del árbol de decisión para tomar una decisión sobre una variable de entrada.
El tamaño de los puntos de datos muestra que hemos aplicado pesos iguales para clasificarlos como un círculo o un triángulo. El muñón de decisión ha generado una línea horizontal en la mitad superior para clasificar estos puntos. Podemos ver que hay dos círculos incorrectamente predichos como triángulos. Por lo tanto, asignaremos pesos más altos a estos dos círculos y aplicaremos otro tocón de decisión.
En segundo lugar, pasamos a otro tocón de decisión para tomar una decisión sobre otra variable de entrada.
Observamos que el tamaño de los dos círculos mal clasificados del paso anterior es mayor que el del resto de puntos. Ahora, el segundo muñón de decisión intentará predecir estos dos círculos correctamente.
Como resultado de la asignación de pesos más altos, estos dos círculos han sido clasificados correctamente por la línea vertical de la izquierda. Pero esto ha dado lugar a una clasificación errónea de los tres círculos de la parte superior. Por lo tanto, asignaremos pesos más altos a estos tres círculos de la parte superior y aplicaremos otro tocón de decisión.
Tercero, entrenar otro tocón de decisión para tomar una decisión sobre otra variable de entrada.
Los tres círculos mal clasificados del paso anterior son más grandes que el resto de los puntos de datos. Ahora, se ha generado una línea vertical hacia la derecha para clasificar los círculos y triángulos.
Cuarto, Combinar los muñones de decisión.
Hemos combinado los separadores de los 3 modelos anteriores y observamos que la regla compleja de este modelo clasifica correctamente los puntos de datos en comparación con cualquiera de los aprendices débiles individuales.
Conclusión:
Para recapitular, hemos cubierto algunos de los algoritmos de aprendizaje automático más importantes para la ciencia de datos:
Nota del editor: Esto fue publicado originalmente en KDNuggets, y ha sido republicado con permiso. La autora, Reena Shaw, es desarrolladora y periodista de ciencia de datos.

Reena Shaw es una amante de todo lo relacionado con los datos, la comida picante y Alfred Hitchcock. Póngase en contacto con ella a través de los enlaces que aparecen en el botón «Leer más» a su derecha: Linkedin| |@ReenaShawLegacy