Este post cubre los fundamentos de Apache Parquet, que es un importante bloque de construcción en la arquitectura de big data. Para obtener más información sobre la gestión de archivos en el almacenamiento de objetos, consulte nuestra guía sobre el particionamiento de datos en Amazon S3.
En la conferencia Amazon re:Invent del año pasado (cuando las conferencias de la vida real todavía eran una cosa), AWS anunció la exportación de los lagos de datos: la capacidad de descargar el resultado de una consulta de Redshift a Amazon S3 en formato Apache Parquet. En el anuncio, AWS describió Parquet como «2 veces más rápido de descargar y consume hasta 6 veces menos de almacenamiento en Amazon S3, en comparación con los formatos de texto». La conversión de datos a formatos columnares como Parquet u ORC también se recomienda como medio para mejorar el rendimiento de Amazon Athena.
Está claro que Apache Parquet juega un papel importante en el rendimiento del sistema cuando se trabaja con lagos de datos. Echemos un vistazo más de cerca a lo que es realmente Parquet, y por qué es importante para el almacenamiento y el análisis de big data.
Los fundamentos: ¿Qué es Apache Parquet?
Apache Parquet es un formato de archivo diseñado para soportar el procesamiento rápido de datos complejos, con varias características notables:
1. Columnar: A diferencia de los formatos basados en filas, como CSV o Avro, Apache Parquet está orientado a columnas, lo que significa que los valores de cada columna de la tabla se almacenan uno al lado del otro, en lugar de los de cada registro:
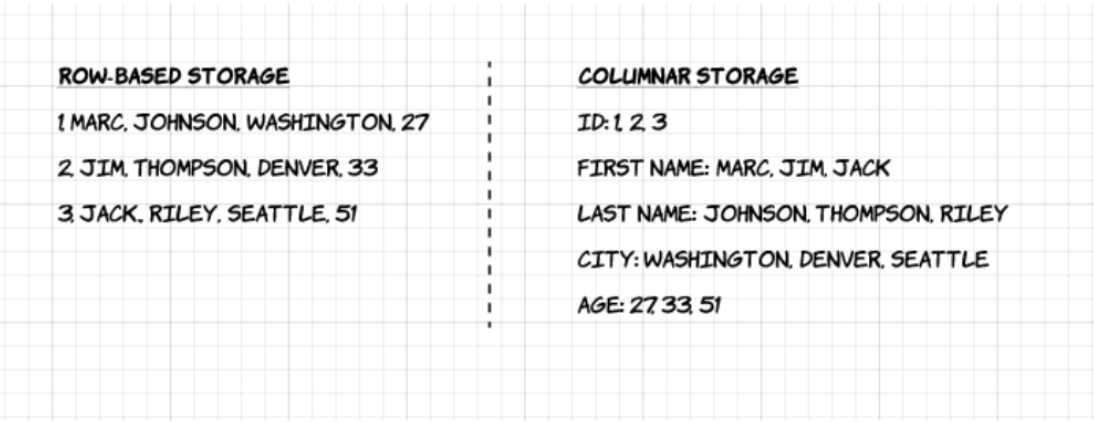
2. De código abierto: Parquet es de uso gratuito y de código abierto bajo la licencia Apache Hadoop, y es compatible con la mayoría de los marcos de procesamiento de datos Hadoop.
3. Autodescripción: En Parquet, los metadatos, incluyendo el esquema y la estructura, están incrustados dentro de cada archivo, lo que lo convierte en un formato de archivo autodescriptivo.
Ventajas del almacenamiento columnar de Parquet
Las características anteriores del formato de archivo Apache Parquet crean varios beneficios distintos cuando se trata de almacenar y analizar grandes volúmenes de datos. Veamos algunas de ellas en mayor profundidad.
Compresión
La compresión de archivos es el acto de tomar un archivo y hacerlo más pequeño. En Parquet, la compresión se realiza columna por columna y está construido para soportar opciones de compresión flexibles y esquemas de codificación ampliables por tipo de datos – por ejemplo, se pueden utilizar diferentes codificaciones para comprimir datos de enteros y cadenas.
Los datos de Parquet pueden comprimirse utilizando estos métodos de codificación:
- Codificación de diccionario: se habilita de forma automática y dinámica para los datos con un pequeño número de valores únicos.
- Envasado de bits: El almacenamiento de enteros suele hacerse con 32 o 64 bits dedicados por entero. Esto permite un almacenamiento más eficiente de los enteros pequeños.
- Codificación de longitud de carrera (RLE): cuando el mismo valor aparece varias veces, se almacena un único valor una vez junto con el número de ocurrencias. Parquet implementa una versión combinada de empaquetamiento de bits y RLE, en la que la codificación cambia en función de lo que produce los mejores resultados de compresión.

Rendimiento
A diferencia de los formatos de archivo basados en filas como CSV, Parquet está optimizado para el rendimiento. Al ejecutar consultas en su sistema de archivos basado en Parquet, puede centrarse sólo en los datos relevantes muy rápidamente. Además, la cantidad de datos escaneados será mucho menor y dará lugar a un menor uso de E/S. Para entender esto, veamos un poco más en profundidad cómo se estructuran los archivos de Parquet.
Como hemos mencionado anteriormente, Parquet es un formato autodescriptivo, por lo que cada archivo contiene tanto datos como metadatos. Los archivos de Parquet se componen de grupos de filas, cabecera y pie de página. Cada grupo de filas contiene datos de las mismas columnas. Las mismas columnas se almacenan juntas en cada grupo de filas:
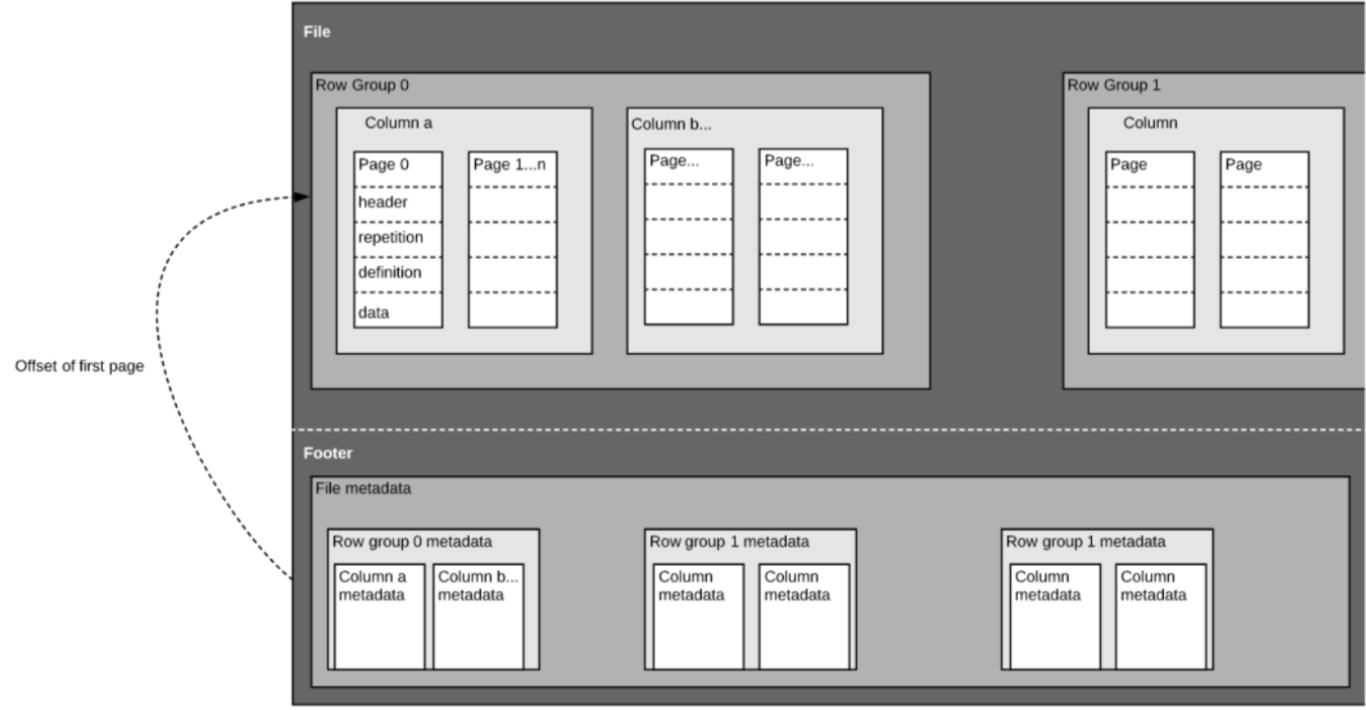
Esta estructura está bien optimizada tanto para un rápido rendimiento de las consultas, como para una baja E/S (minimizando la cantidad de datos escaneados). Por ejemplo, si tiene una tabla con 1000 columnas, que normalmente sólo consultará utilizando un pequeño subconjunto de columnas. El uso de archivos Parquet le permitirá obtener sólo las columnas necesarias y sus valores, cargarlas en memoria y responder a la consulta. Si se utilizara un formato de archivo basado en filas como el CSV, habría que cargar toda la tabla en memoria, lo que supondría un aumento de la E/S y un peor rendimiento.
Evolución del esquema
Al utilizar formatos de archivo en columnas como Parquet, los usuarios pueden empezar con un esquema sencillo, e ir añadiendo gradualmente más columnas al esquema según sea necesario. De esta manera, los usuarios pueden terminar con múltiples archivos Parquet con esquemas diferentes pero compatibles entre sí. En estos casos, Parquet soporta la fusión automática de esquemas entre estos archivos.
Soporte de código abierto
Apache Parquet, como se ha mencionado anteriormente, forma parte del ecosistema de Apache Hadoop, que es de código abierto y está siendo constantemente mejorado y respaldado por una fuerte comunidad de usuarios y desarrolladores. Almacenar los datos en formatos abiertos significa evitar la dependencia de un proveedor y aumentar la flexibilidad, en comparación con los formatos de archivo patentados que utilizan muchas bases de datos modernas de alto rendimiento. Esto significa que puede utilizar varios motores de consulta, como Amazon Athena, Qubole y Amazon Redshift Spectrum, dentro de la misma arquitectura de lago de datos.
Almacenamiento orientado a columnas frente a almacenamiento basado en filas para consultas analíticas
Los datos suelen generarse y conceptualizarse más fácilmente en filas. Estamos acostumbrados a pensar en términos de hojas de cálculo de Excel, donde podemos ver todos los datos relevantes para un registro específico en una fila ordenada y organizada. Sin embargo, para las consultas analíticas a gran escala, el almacenamiento en columnas presenta importantes ventajas en cuanto a coste y rendimiento.
Los datos complejos, como los registros y los flujos de eventos, tendrían que representarse como una tabla con cientos o miles de columnas, y muchos millones de filas. Almacenar esta tabla en un formato basado en filas como CSV significaría:
- Las consultas tardarán más tiempo en ejecutarse, ya que hay que escanear más datos, en lugar de consultar sólo el subconjunto de columnas que necesitamos para responder a una consulta (lo que suele requerir la agregación basada en la dimensión o la categoría)
- El almacenamiento será más costoso, ya que los CSV no se comprimen tan eficientemente como el Parquet
Los formatos de columnas proporcionan una mejor compresión y un mejor rendimiento out-of-the-box, y permiten consultar los datos verticalmente: columna por columna.
Ejemplo: Parquet, CSV y Amazon Athena
Estamos explorando este ejemplo en mucha más profundidad en nuestro próximo webinar con Looker. Reserve su plaza aquí.
Para demostrar el impacto del almacenamiento de Parquet en columnas en comparación con las alternativas basadas en filas, veamos lo que ocurre cuando se utiliza Amazon Athena para consultar los datos almacenados en Amazon S3 en ambos casos.
Usando Upsolver, ingestamos un conjunto de datos CSV de registros de servidor en S3. En una arquitectura de lago de datos de AWS común, Athena se utilizaría para consultar los datos directamente desde S3. Estas consultas se pueden visualizar con herramientas de visualización de datos interactivos como Tableau o Looker.
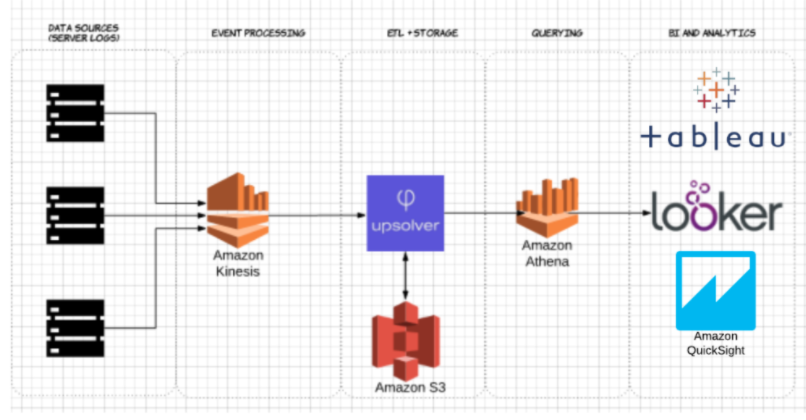
Probamos Athena contra el mismo conjunto de datos almacenado como CSV comprimido, y como Apache Parquet.
Esta es la consulta que ejecutamos en Athena:
SELECT tags_host AS host_id, AVG(fields_usage_active) as avg_usage
FROM server_usage
GROUP BY tags_host
HAVING AVG(fields_usage_active) > 0
LIMIT 10
Y los resultados:
| CSV | Parquet | Columnas | |
| 735 | 211 | 18 | |
| Datos escaneados (GB) | 372.2 | 10,29 | 18 |
- CSVs comprimidos: El CSV comprimido tiene 18 columnas y pesa 27 GB en S3. Athena tiene que escanear todo el archivo CSV para responder a la consulta, por lo que estaríamos pagando por 27 GB de datos escaneados. A mayor escala, esto también afectaría negativamente al rendimiento.
- Parquet: Convirtiendo nuestros archivos CSV comprimidos a Apache Parquet, se termina con una cantidad similar de datos en S3. Sin embargo, debido a que Parquet es columnar, Athena necesita leer sólo las columnas que son relevantes para la consulta que se está ejecutando – un pequeño subconjunto de los datos. En este caso, Athena tuvo que escanear 0,22 GB de datos, por lo que en lugar de pagar por 27 GB de datos escaneados, pagamos solo por 0,22 GB.
¿Es suficiente con usar Parquet?
Usar Parquet es un buen comienzo; sin embargo, la optimización de las consultas de los lagos de datos no termina ahí. A menudo es necesario limpiar, enriquecer y transformar los datos, realizar uniones de alta cardinalidad e implementar una serie de mejores prácticas para garantizar que las consultas se respondan de forma rápida y rentable.
Puede utilizar Upsolver para simplificar su canal de ETL de data lake, ingerir automáticamente los datos como Parquet optimizado y transformar los datos de streaming con funciones SQL o similares a Excel. Para obtener más información, programe una demostración aquí.
¿Quiere saber más sobre la optimización de su lago de datos? Consulte algunas de estas mejores prácticas de lago de datos. Para ver otros puntos de referencia y aprender las mejores prácticas a la hora de preparar los datos para Athena, únase al próximo seminario web de Upsolver + Looker aquí.