L’interesse per l’apprendimento automatico è salito alle stelle negli anni da quando l’articolo di Harvard Business Review ha nominato il ‘Data Scientist’ il ‘Lavoro più sexy del 21° secolo’. Ma se stai appena iniziando nell’apprendimento automatico, può essere un po’ difficile da penetrare. Ecco perché stiamo riavviando il nostro popolarissimo post sui buoni algoritmi di apprendimento automatico per i principianti.
(Questo post è stato originariamente pubblicato su KDNuggets come The 10 Algorithms Machine Learning Engineers Need to Know. È stato ripubblicato con il permesso, ed è stato aggiornato l’ultima volta nel 2019).
Questo post è rivolto ai principianti. Se hai una certa esperienza nella scienza dei dati e nell’apprendimento automatico, potresti essere più interessato a questo tutorial più approfondito su come fare apprendimento automatico in Python con scikit-learn, o ai nostri corsi di apprendimento automatico, che iniziano qui. Se non vi sono ancora chiare le differenze tra “data science” e “machine learning”, questo articolo offre una buona spiegazione: machine learning e data science – cosa li rende diversi?
Gli algoritmi di machine learning sono programmi che possono imparare dai dati e migliorare dall’esperienza, senza intervento umano. I compiti di apprendimento possono includere l’apprendimento della funzione che mappa l’input all’output, l’apprendimento della struttura nascosta nei dati non etichettati; o l'”apprendimento basato sull’istanza”, dove un’etichetta di classe viene prodotta per una nuova istanza confrontando la nuova istanza (riga) con le istanze dei dati di addestramento, che sono state archiviate in memoria. L”apprendimento basato sull’istanza’ non crea un’astrazione da istanze specifiche.
Tipi di algoritmi di apprendimento automatico
Ci sono 3 tipi di algoritmi di apprendimento automatico (ML):
Algoritmi di apprendimento supervisionato:
L’apprendimento supervisionato usa dati di allenamento etichettati per imparare la funzione di mappatura che trasforma le variabili di input (X) nella variabile di output (Y). In altre parole, risolve f nella seguente equazione:
Questo ci permette di generare accuratamente gli output quando vengono dati nuovi input.
Parleremo di due tipi di apprendimento supervisionato: classificazione e regressione.
La classificazione è usata per predire il risultato di un dato campione quando la variabile di output è sotto forma di categorie. Un modello di classificazione potrebbe guardare i dati di input e cercare di predire etichette come “malato” o “sano”.
La regressione è usata per predire il risultato di un dato campione quando la variabile di output è sotto forma di valori reali. Per esempio, un modello di regressione potrebbe elaborare i dati di input per prevedere la quantità di pioggia, l’altezza di una persona, ecc.
I primi 5 algoritmi che copriamo in questo blog – Regressione lineare, Regressione logistica, CART, Naïve-Bayes, e K-Nearest Neighbors (KNN) – sono esempi di apprendimento supervisionato.
L’assemblaggio è un altro tipo di apprendimento supervisionato. Significa combinare le previsioni di più modelli di apprendimento automatico che sono individualmente deboli per produrre una previsione più accurata su un nuovo campione. Gli algoritmi 9 e 10 di questo articolo – Bagging con Random Forests, Boosting con XGBoost – sono esempi di tecniche ensemble.
Algoritmi di apprendimento non supervisionato:
I modelli di apprendimento non supervisionato sono utilizzati quando abbiamo solo le variabili di input (X) e nessuna variabile di output corrispondente. Usano dati di addestramento non etichettati per modellare la struttura sottostante dei dati.
Parleremo di tre tipi di apprendimento non supervisionato:
L’associazione è usata per scoprire la probabilità della co-occorrenza degli elementi in una collezione. È ampiamente utilizzato nell’analisi del market-basket. Per esempio, un modello di associazione potrebbe essere usato per scoprire che se un cliente acquista del pane, ha l’80% di probabilità di acquistare anche delle uova.
Clustering è usato per raggruppare i campioni in modo tale che gli oggetti all’interno dello stesso cluster siano più simili tra loro che agli oggetti di un altro cluster.
La riduzione della dimensionalità è usata per ridurre il numero di variabili di un set di dati assicurando che le informazioni importanti siano ancora trasmesse. La riduzione della dimensionalità può essere fatta usando metodi di estrazione delle caratteristiche e metodi di selezione delle caratteristiche. La selezione delle caratteristiche seleziona un sottoinsieme delle variabili originali. L’estrazione delle caratteristiche esegue la trasformazione dei dati da uno spazio ad alta dimensionalità ad uno spazio a bassa dimensionalità. Esempio: L’algoritmo PCA è un approccio di Feature Extraction.
Gli algoritmi 6-8 che copriamo qui – Apriori, K-means, PCA – sono esempi di apprendimento non supervisionato.
Apprendimento per rinforzo:
L’apprendimento per rinforzo è un tipo di algoritmo di apprendimento automatico che permette ad un agente di decidere la migliore azione successiva in base al suo stato attuale, imparando comportamenti che massimizzeranno una ricompensa.
Gli algoritmi di rinforzo di solito imparano azioni ottimali attraverso tentativi ed errori. Immaginate, per esempio, un videogioco in cui il giocatore ha bisogno di muoversi in certi posti in certi momenti per guadagnare punti. Un algoritmo di rinforzo che gioca a quel gioco inizierebbe muovendosi in modo casuale ma, col tempo, attraverso prove ed errori, imparerebbe dove e quando deve muovere il personaggio del gioco per massimizzare il suo totale di punti.
Quantificare la popolarità degli algoritmi di apprendimento automatico
Dove abbiamo trovato questi dieci algoritmi? Qualsiasi lista di questo tipo sarà intrinsecamente soggettiva. Studi come questi hanno quantificato i 10 algoritmi di data mining più popolari, ma si basano ancora sulle risposte soggettive dei partecipanti al sondaggio, di solito professionisti accademici avanzati. Per esempio, nello studio linkato sopra, le persone intervistate erano i vincitori dell’ACM KDD Innovation Award, dell’IEEE ICDM Research Contributions Award; i membri del Program Committee del KDD ’06, ICDM ’06, e SDM ’06; e i 145 partecipanti all’ICDM ’06.
I 10 algoritmi top elencati in questo post sono scelti pensando ai principianti dell’apprendimento automatico. Sono principalmente algoritmi che ho imparato dal corso ‘Data Warehousing and Mining’ (DWM) durante la mia laurea in Ingegneria Informatica all’Università di Mumbai. Ho incluso gli ultimi 2 algoritmi (metodi ensemble) in particolare perché sono spesso usati per vincere le competizioni Kaggle.
Senza ulteriori indugi, i 10 migliori algoritmi di apprendimento automatico per principianti:
1. Regressione lineare
Nel machine learning, abbiamo un insieme di variabili di input (x) che sono usate per determinare una variabile di output (y). Esiste una relazione tra le variabili di input e la variabile di output. L’obiettivo del ML è quello di quantificare questa relazione.
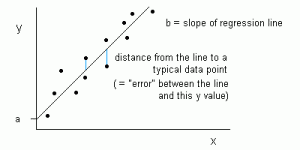
Nella regressione lineare, la relazione tra le variabili di input (x) e la variabile di output (y) è espressa come un’equazione della forma y = a + bx. Quindi, l’obiettivo della regressione lineare è quello di trovare i valori dei coefficienti a e b. Qui, a è l’intercetta e b è la pendenza della linea.
La figura 1 mostra i valori x e y tracciati per una serie di dati. L’obiettivo è di adattare una linea che sia più vicina alla maggior parte dei punti. Questo ridurrebbe la distanza (‘errore’) tra il valore y di un punto di dati e la linea.
2. Regressione logistica
Le previsioni della regressione lineare sono valori continui (es. piogge in cm), le previsioni della regressione logistica sono valori discreti (es, se uno studente è stato promosso o meno) dopo aver applicato una funzione di trasformazione.
La regressione logistica è più adatta per la classificazione binaria: set di dati in cui y = 0 o 1, dove 1 denota la classe predefinita. Per esempio, nel prevedere se un evento si verificherà o meno, ci sono solo due possibilità: che si verifichi (che denotiamo come 1) o che non si verifichi (0). Quindi, se stessimo prevedendo se un paziente è malato, etichetteremmo i pazienti malati usando il valore di 1 nel nostro set di dati.
La regressione logistica prende il nome dalla funzione di trasformazione che utilizza, chiamata funzione logistica h(x)= 1/ (1 + ex). Questa forma una curva a forma di S.
Nella regressione logistica, l’output prende la forma di probabilità della classe predefinita (a differenza della regressione lineare, dove l’output è prodotto direttamente). Essendo una probabilità, l’output si trova nell’intervallo 0-1. Così, per esempio, se stiamo cercando di prevedere se i pazienti sono malati, sappiamo già che i pazienti malati sono indicati come 1, quindi se il nostro algoritmo assegna il punteggio di 0,98 a un paziente, pensa che quel paziente è abbastanza probabile che sia malato.
Questo output (valore y) è generato trasformando logicamente il valore x, utilizzando la funzione logistica h(x)= 1/ (1 + e^ -x) . Una soglia viene poi applicata per forzare questa probabilità in una classificazione binaria.
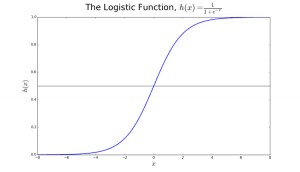
Figura 2: Regressione logistica per determinare se un tumore è maligno o benigno. Classificato come maligno se la probabilità h(x)>= 0,5. Fonte
Nella figura 2, per determinare se un tumore è maligno o meno, la variabile predefinita è y = 1 (tumore = maligno). La variabile x potrebbe essere una misura del tumore, come la dimensione del tumore. Come mostrato nella figura, la funzione logistica trasforma il valore x delle varie istanze del set di dati, in un intervallo da 0 a 1. Se la probabilità attraversa la soglia di 0,5 (mostrata dalla linea orizzontale), il tumore è classificato come maligno.
L’equazione di regressione logistica P(x) = e ^ (b0 +b1x) / (1 + e(b0 + b1x)) può essere trasformata in ln(p(x) / 1-p(x)) = b0 + b1x.
L’obiettivo della regressione logistica è quello di utilizzare i dati di allenamento per trovare i valori dei coefficienti b0 e b1 tali da minimizzare l’errore tra il risultato previsto e quello effettivo. Questi coefficienti sono stimati usando la tecnica della stima di massima verosimiglianza.
3. CART
Gli alberi di classificazione e regressione (CART) sono un’implementazione degli alberi di decisione.
I nodi non terminali degli alberi di classificazione e regressione sono il nodo radice e il nodo interno. I nodi terminali sono i nodi foglia. Ogni nodo non terminale rappresenta una singola variabile di input (x) e un punto di divisione su quella variabile; i nodi foglia rappresentano la variabile di output (y). Il modello è usato come segue per fare previsioni: percorrere le spaccature dell’albero per arrivare a un nodo foglia e produrre il valore presente al nodo foglia.
L’albero decisionale nella Figura 3 qui sotto classifica se una persona comprerà un’auto sportiva o un minivan a seconda della sua età e del suo stato civile. Se la persona ha più di 30 anni e non è sposata, percorriamo l’albero come segue: ‘più di 30 anni?’ -> sì -> ‘sposato?’ -> no. Quindi, il modello produce un’auto sportiva.
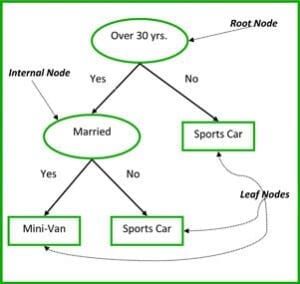
Figura 3: Parti di un albero decisionale. Fonte
4. Naïve Bayes
Per calcolare la probabilità che un evento si verifichi, dato che un altro evento si è già verificato, si usa il Teorema di Bayes. Per calcolare la probabilità che l’ipotesi(h) sia vera, data la nostra conoscenza preliminare(d), usiamo il Teorema di Bayes come segue:
dove:
- P(h|d) = Probabilità posteriore. La probabilità che l’ipotesi h sia vera, dati i dati d, dove P(h|d)= P(d1| h) P(d2| h)….P(dn| h) P(d)
- P(d|h) = Probabilità. La probabilità del dato d dato che l’ipotesi h fosse vera.
- P(h) = Probabilità a priori della classe. La probabilità che l’ipotesi h sia vera (indipendentemente dai dati)
- P(d) = Probabilità a priori del predittore. Probabilità dei dati (indipendentemente dall’ipotesi)
Questo algoritmo è chiamato ‘ingenuo’ perché assume che tutte le variabili siano indipendenti l’una dall’altra, che è un’assunzione ingenua da fare negli esempi del mondo reale.
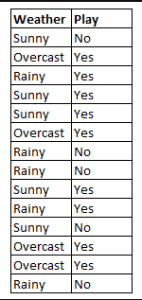
Figura 4: Utilizzo di Naive Bayes per prevedere lo stato di ‘play’ utilizzando la variabile ‘weather’.
Utilizzando la figura 4 come esempio, qual è il risultato se meteo = ‘sole’?
Per determinare il risultato giocare = ‘sì’ o ‘no’ dato il valore della variabile meteo = ‘sole’, calcolare P(sì|sole) e P(no|sole) e scegliere il risultato con maggiore probabilità.
->P(sì|sole)= (P(sole|si) * P(sì)) / P(sunny) = (3/9 * 9/14 ) / (5/14) = 0,60
-> P(no|sunny)= (P(sunny|no) * P(no)) / P(sunny) = (2/5 * 5/14 ) / (5/14) = 0.40
Quindi, se il tempo = ‘sunny’, il risultato è play = ‘yes’.
5. KNN
L’algoritmo K-Nearest Neighbors usa l’intero set di dati come set di allenamento, piuttosto che dividere il set di dati in un set di allenamento e un set di test.
Quando è richiesto un risultato per una nuova istanza di dati, l’algoritmo KNN passa attraverso l’intero set di dati per trovare le istanze k più vicine alla nuova istanza, o il numero k di istanze più simili al nuovo record, e poi produce la media dei risultati (per un problema di regressione) o la modalità (classe più frequente) per un problema di classificazione. Il valore di k è specificato dall’utente.
La somiglianza tra le istanze è calcolata usando misure come la distanza euclidea e la distanza di Hamming.
Algoritmi di apprendimento non supervisionato
6. Apriori
L’algoritmo Apriori è usato in un database transazionale per estrarre insiemi di elementi frequenti e poi generare regole di associazione. È popolarmente usato nell’analisi del paniere di mercato, dove si controllano le combinazioni di prodotti che si presentano frequentemente nel database. In generale, scriviamo la regola di associazione per ‘se una persona acquista l’articolo X, allora acquista l’articolo Y’ come : X -> Y.
Esempio: se una persona acquista latte e zucchero, allora è probabile che acquisti caffè in polvere. Questo potrebbe essere scritto sotto forma di regola di associazione come: {latte,zucchero} -> caffè in polvere. Le regole di associazione sono generate dopo aver superato la soglia di supporto e di confidenza.

Figura 5: Formule per supporto, confidenza e ascensore per la regola di associazione X->Y.
La misura di supporto aiuta a potare il numero di insiemi di elementi candidati da considerare durante la generazione di insiemi di elementi frequenti. Questa misura di supporto è guidata dal principio Apriori. Il principio Apriori afferma che se un insieme di elementi è frequente, allora anche tutti i suoi sottoinsiemi devono essere frequenti.
7. K-means
K-means è un algoritmo iterativo che raggruppa dati simili in cluster.Calcola i centroidi di k cluster e assegna un punto dati a quel cluster che ha meno distanza tra il suo centroide e il punto dati.
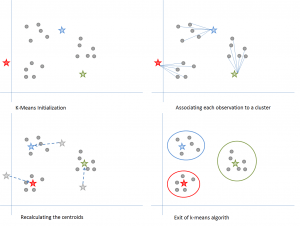
Figura 6: Passi dell’algoritmo K-means. Fonte
Ecco come funziona:
Partiamo scegliendo un valore di k. Qui, diciamo k = 3. Poi, assegniamo casualmente ogni punto dati a uno qualsiasi dei 3 cluster. Calcoliamo il centroide del cluster per ogni cluster. Le stelle rosse, blu e verdi indicano i centroidi per ciascuno dei 3 cluster.
In seguito, riassegniamo ogni punto al centroide del cluster più vicino. Nella figura sopra, i 5 punti superiori sono stati assegnati al cluster con il centroide blu. Segui la stessa procedura per assegnare i punti ai cluster contenenti i centroidi rossi e verdi.
Poi, calcola i centroidi per i nuovi cluster. I vecchi centroidi sono le stelle grigie; i nuovi centroidi sono le stelle rosse, verdi e blu.
Infine, ripetete i passi 2-3 fino a quando non c’è passaggio di punti da un cluster all’altro. Una volta che non c’è passaggio per 2 passi consecutivi, esci dall’algoritmo K-means.
8. PCA
L’analisi delle componenti principali (PCA) è usata per rendere i dati facili da esplorare e visualizzare riducendo il numero di variabili. Questo viene fatto catturando la massima varianza nei dati in un nuovo sistema di coordinate con assi chiamati ‘componenti principali’.
Ogni componente è una combinazione lineare delle variabili originali ed è ortogonale all’altra. L’ortogonalità tra le componenti indica che la correlazione tra queste componenti è zero.
La prima componente principale cattura la direzione della massima variabilità nei dati. La seconda componente principale cattura la varianza rimanente nei dati, ma ha variabili non correlate con la prima componente. Allo stesso modo, tutte le componenti principali successive (PC3, PC4 e così via) catturano la varianza rimanente pur non essendo correlate con la componente precedente.
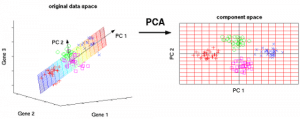
Figura 7: Le 3 variabili originali (geni) sono ridotte a 2 nuove variabili chiamate componenti principali (PC). Fonte
Tecniche di apprendimento ensemble:
Ensemblare significa combinare i risultati di più allievi (classificatori) per migliorare i risultati, attraverso il voto o la media. Il voto è usato durante la classificazione e la media è usata durante la regressione. L’idea è che gli insiemi di apprendisti hanno prestazioni migliori rispetto agli apprendisti singoli.
Ci sono 3 tipi di algoritmi di ensembling: Bagging, Boosting e Stacking. Non tratteremo lo ‘stacking’ qui, ma se vuoi una spiegazione dettagliata, ecco una solida introduzione da Kaggle.
9. Bagging con Foreste casuali
Il primo passo nel bagging è quello di creare modelli multipli con set di dati creati utilizzando il metodo del Bootstrap Sampling. Nel Bootstrap Sampling, ogni set di allenamento generato è composto da sottocampioni casuali dal set di dati originale.
Ognuno di questi set di allenamento è della stessa dimensione del set di dati originale, ma alcuni record si ripetono più volte e alcuni record non appaiono affatto. Poi, l’intero set di dati originale viene usato come set di test. Così, se la dimensione del set di dati originale è N, allora la dimensione di ogni set di allenamento generato è anche N, con il numero di record unici che è circa (2N/3); la dimensione del set di test è anche N.
Il secondo passo nel bagging è quello di creare modelli multipli usando lo stesso algoritmo sui diversi set di allenamento generati.
Questo è dove entrano in gioco le Foreste casuali. A differenza di un albero decisionale, dove ogni nodo è diviso sulla migliore caratteristica che minimizza l’errore, in Random Forests, si sceglie una selezione casuale di caratteristiche per costruire la migliore divisione. La ragione della casualità è: anche con il bagging, quando gli alberi decisionali scelgono la migliore caratteristica su cui dividersi, finiscono per avere una struttura simile e previsioni correlate. Ma il bagging dopo la divisione su un sottoinsieme casuale di caratteristiche significa meno correlazione tra le previsioni dei sottoalberi.
Il numero di caratteristiche da cercare in ogni punto di divisione è specificato come un parametro dell’algoritmo Random Forest.
Quindi, nel bagging con Random Forest, ogni albero è costruito usando un campione casuale di record e ogni divisione è costruita usando un campione casuale di predittori.
10. Boosting con AdaBoost
Adaboost sta per Adaptive Boosting. Il bagging è un insieme parallelo perché ogni modello è costruito indipendentemente. D’altra parte, il boosting è un insieme sequenziale dove ogni modello è costruito sulla base della correzione degli errori di classificazione del modello precedente.
Bagging implica per lo più il “voto semplice”, in cui ogni classificatore vota per ottenere un risultato finale, che è determinato dalla maggioranza dei modelli paralleli; il boosting implica il “voto ponderato”, in cui ogni classificatore vota per ottenere un risultato finale che è determinato dalla maggioranza, ma i modelli sequenziali sono stati costruiti assegnando pesi maggiori alle istanze mal classificate dei modelli precedenti.
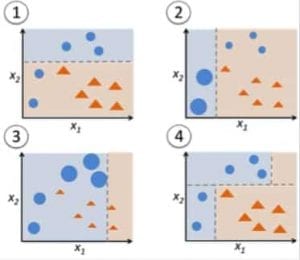
Figura 9: Adaboost per un albero decisionale. Fonte
Nella Figura 9, i passi 1, 2, 3 coinvolgono un discente debole chiamato “decision stump” (un albero decisionale a 1 livello che fa una previsione basata sul valore di una sola caratteristica di input; un albero decisionale con la sua radice immediatamente connessa alle sue foglie).
Il processo di costruzione di discenti deboli continua fino a quando un numero definito dall’utente di discenti deboli è stato costruito o fino a quando non c’è un ulteriore miglioramento durante la formazione. Il passo 4 combina i 3 ceppi di decisione dei modelli precedenti (e quindi ha 3 regole di divisione nell’albero di decisione).
Prima di tutto, iniziamo con un ceppo dell’albero di decisione per prendere una decisione su una variabile di input.
Le dimensioni dei punti dei dati mostrano che abbiamo applicato pesi uguali per classificarli come un cerchio o un triangolo. Il ceppo di decisione ha generato una linea orizzontale nella metà superiore per classificare questi punti. Possiamo vedere che ci sono due cerchi erroneamente predetti come triangoli. Quindi, assegneremo pesi più alti a questi due cerchi e applicheremo un altro ceppo decisionale.
In secondo luogo, passiamo a un altro ceppo dell’albero decisionale per prendere una decisione su un’altra variabile di input.
Osserviamo che la dimensione dei due cerchi mal classificati dal passo precedente è maggiore dei punti rimanenti. Ora, il secondo ceppo di decisione cercherà di predire correttamente questi due cerchi.
Come risultato dell’assegnazione di pesi più alti, questi due cerchi sono stati correttamente classificati dalla linea verticale sulla sinistra. Ma questo ha portato a classificare male i tre cerchi in alto. Quindi, assegneremo pesi più alti a questi tre cerchi in alto e applicheremo un altro ceppo di decisione.
In terzo luogo, addestriamo un altro ceppo di albero di decisione per prendere una decisione su un’altra variabile di input.
I tre cerchi mal classificati dal passo precedente sono più grandi del resto dei punti di dati. Ora, una linea verticale verso destra è stata generata per classificare i cerchi e i triangoli.
Quarto, combinare i ceppi di decisione.
Abbiamo combinato i separatori dei 3 modelli precedenti e osserviamo che la regola complessa di questo modello classifica correttamente i punti dei dati rispetto a qualsiasi dei singoli apprendisti deboli.
Conclusione:
Per ricapitolare, abbiamo coperto alcuni dei più importanti algoritmi di apprendimento automatico per la scienza dei dati:
- 5 tecniche di apprendimento supervisionato – Regressione lineare, Regressione logistica, CART, Naïve Bayes, KNN.
- 3 tecniche di apprendimento non supervisionato- Apriori, K-means, PCA.
- 2 tecniche di ensembling- Bagging con Random Forests, Boosting con XGBoost.
Nota dell’editore: Questo è stato originariamente pubblicato su KDNuggets, ed è stato ripubblicato con permesso. L’autore Reena Shaw è uno sviluppatore e un giornalista di scienza dei dati.

Reena Shaw è un’amante di tutte le cose che riguardano i dati, il cibo piccante e Alfred Hitchcock. Contattatela usando i link nel pulsante ‘Read More’ alla vostra destra: Linkedin| |@ReenaShawLegacy