La velocità del sito web è una priorità per le aziende nel 2020.
I siti web più veloci si classificano meglio sui motori di ricerca e forniscono anche una migliore esperienza utente, con conseguente aumento dei tassi di conversione. Non c’è da stupirsi che i proprietari dei siti web richiedano una maggiore velocità di caricamento delle pagine – lasciando agli sviluppatori il compito di realizzarla.
L’ottimizzazione del database è un passo essenziale per migliorare le prestazioni del sito web. Di solito, gli sviluppatori normalizzano un database relazionale, cioè lo ristrutturano per ridurre la ridondanza dei dati e migliorarne l’integrità. Tuttavia, a volte normalizzare un database non è sufficiente, quindi per migliorare ulteriormente le prestazioni del database gli sviluppatori fanno il contrario e ricorrono alla denormalizzazione del database.
In questo articolo, diamo uno sguardo più da vicino alla denormalizzazione per scoprire quando questo metodo è appropriato e come si può fare.
Quando denormalizzare un database
Cos’è la denormalizzazione del database? Prima di immergerci nell’argomento, sottolineiamo che la normalizzazione rimane ancora il punto di partenza, il che significa che si dovrebbe prima di tutto normalizzare la struttura di un database. L’essenza della normalizzazione è mettere ogni dato al posto giusto; questo assicura l’integrità dei dati e facilita l’aggiornamento. Tuttavia, recuperare i dati da un database normalizzato può essere più lento, poiché le query devono rivolgersi a molte tabelle diverse dove sono memorizzati diversi pezzi di dati. L’aggiornamento, al contrario, diventa più veloce perché tutti i dati sono memorizzati in un unico posto.
La maggior parte delle applicazioni moderne deve essere in grado di recuperare i dati nel più breve tempo possibile. Ed è allora che si può considerare la denormalizzazione di un database relazionale. Come suggerisce il nome, la denormalizzazione è l’opposto della normalizzazione. Quando si normalizza un database, si organizzano i dati per assicurare l’integrità ed eliminare le ridondanze. Denormalizzare un database significa mettere deliberatamente gli stessi dati in più posti, aumentando così la ridondanza.
“Perché denormalizzare un database? Lo scopo principale della denormalizzazione è quello di accelerare significativamente il recupero dei dati. Tuttavia, la denormalizzazione non è una pillola magica. Gli sviluppatori dovrebbero usare questo strumento solo per scopi particolari:
# 1 Per migliorare le prestazioni delle query
In genere, un database normalizzato richiede l’unione di molte tabelle per recuperare le query; ma più sono le unioni, più lenta è la query. Come contromisura, si può aggiungere ridondanza a un database copiando i valori tra le tabelle padre e figlio e, quindi, riducendo il numero di join richiesti per una query.
#2 Per rendere un database più comodo da gestire
Un database normalizzato non ha valori calcolati che sono essenziali per le applicazioni. Calcolare questi valori al volo richiederebbe tempo, rallentando l’esecuzione delle query.
Si può denormalizzare un database per fornire valori calcolati. Una volta generati e aggiunti alle tabelle, i programmatori a valle possono facilmente creare i loro report e le loro query senza avere una conoscenza approfondita del codice dell’applicazione o delle API.
#3 Per facilitare e accelerare il reporting
Spesso le applicazioni devono fornire molte informazioni analitiche e statistiche. La generazione di report dai dati in tempo reale richiede molto tempo e può avere un impatto negativo sulle prestazioni complessive del sistema.
La denormalizzazione del vostro database può aiutarvi ad affrontare questa sfida. Supponiamo che abbiate bisogno di fornire un riepilogo totale delle vendite per uno o molti utenti; un database normalizzato aggregherebbe e calcolerebbe tutti i dettagli delle fatture più volte. Inutile dire che questo richiederebbe molto tempo, quindi per accelerare questo processo, si potrebbe mantenere il riepilogo delle vendite dell’anno in corso in una tabella che memorizza i dettagli dell’utente.
Tecniche di denormalizzazione del database
Ora che sai quando dovresti procedere alla denormalizzazione del database, probabilmente ti stai chiedendo come farlo bene. Ci sono diverse tecniche di denormalizzazione, ognuna appropriata per una particolare situazione. Esploriamole in profondità:
Memorizzare i dati derivabili
Se è necessario eseguire un calcolo ripetutamente durante le query, è meglio memorizzarne i risultati. Se il calcolo contiene record di dettaglio, si dovrebbe memorizzare il calcolo derivato nella tabella principale. Ogni volta che si decide di memorizzare valori derivabili, assicurarsi che i valori denormalizzati siano sempre ricalcolati dal sistema.
Queste sono le situazioni in cui la memorizzazione di valori derivabili è appropriata:
- Quando si ha spesso bisogno di valori derivabili
- Quando non si alterano frequentemente i valori sorgente
| Vantaggi | Svantaggi |
|---|---|
| Nessuna bisogno di cercare i valori sorgente ogni volta che è necessario un valore derivabile | Eseguire le istruzioni del linguaggio di manipolazione dei dati (DML) contro i dati sorgente richiede il ricalcolo dei dati derivabili |
| Non è necessario eseguire un calcolo per ogni query o report | Sono possibili incoerenze di dati a causa della duplicazione dei dati |
Esempio

Come esempio di questa tecnica di denormalizzazione, supponiamo di costruire un servizio di messaggistica e-mail. Dopo aver ricevuto un messaggio, un utente ottiene solo un puntatore a questo messaggio; il puntatore è memorizzato nella tabella User_messages. Questo viene fatto per evitare che il sistema di messaggistica memorizzi più copie di un messaggio di posta elettronica nel caso in cui venga inviato a molti destinatari diversi alla volta. Ma cosa succede se un utente cancella un messaggio dal suo account? In questo caso, solo la rispettiva voce nella tabella User_messages viene effettivamente rimossa. Quindi, per eliminare completamente il messaggio, tutti i record User_messages per esso devono essere rimossi.
La denormalizzazione dei dati in una delle tabelle può rendere questo molto più semplice: possiamo aggiungere un users_received_count alla tabella Messages per mantenere un record di User_messages tenuto per un messaggio specifico. Quando un utente cancella questo messaggio (leggi: rimuove il puntatore al messaggio effettivo), la colonna users_received_count viene decrementata di uno. Naturalmente, quando users_received_count è uguale a zero, il messaggio effettivo può essere cancellato completamente.
Utilizzare le tabelle pre-unite
Per pre-unire le tabelle, è necessario aggiungere una colonna non-chiave ad una tabella che non ha valore commerciale. In questo modo, è possibile evitare di unire le tabelle e quindi velocizzare le query. Tuttavia bisogna assicurarsi che la colonna denormalizzata venga aggiornata ogni volta che il valore della colonna master viene alterato.
Questa tecnica di denormalizzazione può essere usata quando si devono fare molte query contro molte tabelle diverse – e finché i dati stantii sono accettabili.
| Vantaggi | Svantaggi |
|---|---|
| Non c’è bisogno di usare join multipli | DML è richiesto per aggiornare la colonna noncolonna denormalizzata |
| È possibile rimandare gli aggiornamenti finché i dati stantii sono tollerabili | Una colonna extra richiede ulteriore lavoro e spazio su disco |
Esempio

Immagina che gli utenti del nostro servizio di messaggistica e-mail vogliano accedere ai messaggi per categoria. Mantenere il nome di una categoria proprio nella tabella User_messages può far risparmiare tempo e ridurre il numero di join necessari.
Nella tabella denormalizzata qui sopra, abbiamo introdotto la colonna category_name per memorizzare le informazioni su quale categoria ogni record della tabella User_messages è collegato. Grazie alla denormalizzazione, è necessaria solo una query sulla tabella User_messages per permettere a un utente di selezionare tutti i messaggi appartenenti a una specifica categoria. Naturalmente, questa tecnica di denormalizzazione ha un rovescio della medaglia: questa colonna extra può richiedere molto spazio di memorizzazione.
Utilizzando valori hardcoded
Se c’è una tabella di riferimento con record costanti, è possibile hardcoded nella propria applicazione. In questo modo, non c’è bisogno di unire le tabelle per recuperare i valori di riferimento.
Tuttavia, quando si usano valori hardcoded, si dovrebbe creare un vincolo di controllo per validare i valori rispetto ai valori di riferimento. Questo vincolo deve essere riscritto ogni volta che è richiesto un nuovo valore nella tabella A.
Questa tecnica di denormalizzazione dei dati dovrebbe essere usata se i valori sono statici durante tutto il ciclo di vita del vostro sistema e finché il numero di questi valori è abbastanza piccolo. Ora diamo un’occhiata ai pro e ai contro di questa tecnica:
| Vantaggi | Svantaggi |
|---|---|
| Non c’è bisogno di implementare una tabella di ricerca | Sono necessarie la ricodifica e la rideterminazione se i valori di look-sono alterati |
| Nessuna connessione ad una tabella di ricerca |
Esempio

Supponiamo di dover trovare informazioni di base sugli utenti di un servizio di messaggistica e-mail, per esempio il tipo di utente. Abbiamo creato una tabella User_kinds per memorizzare i dati sui tipi di utenti che dobbiamo riconoscere.
I valori memorizzati in questa tabella non saranno probabilmente cambiati frequentemente, quindi possiamo applicare l’hardcoding. Possiamo aggiungere un vincolo di controllo alla colonna o costruire il vincolo di controllo nella validazione del campo per l’applicazione in cui gli utenti accedono al nostro servizio di email messaging.
Mantenere i dettagli con il master
Ci possono essere casi in cui il numero di record di dettaglio per master è fisso o quando i record di dettaglio sono interrogati con il master. In questi casi, è possibile denormalizzare un database aggiungendo colonne di dettaglio alla tabella master. Questa tecnica si rivela più utile quando ci sono pochi record nella tabella di dettaglio.
| Vantaggi | Svantaggi |
|---|---|
| Non c’è bisogno di usare i join | Aumenta la complessità del DML |
| Risparmia spazio |
Esempio

Immaginate di dover limitare la quantità massima di spazio di archiviazione che un utente può ottenere. Per farlo, abbiamo bisogno di implementare dei vincoli nel nostro servizio di messaggistica e-mail – uno per i messaggi e un altro per i file. Poiché la quantità di spazio di archiviazione consentito per ciascuna di queste limitazioni è diversa, abbiamo bisogno di tracciare ogni limitazione individualmente. In un database relazionale normalizzato, potremmo semplicemente introdurre due tabelle diverse – Storage_types e Storage_restraints – che memorizzerebbero i record per ogni utente.
Invece, possiamo prendere una strada diversa e aggiungere colonne denormalizzate alla tabella Utenti:
message_space_allocated
message_space_available
file_space_allocated
file_space_available
In questo caso, la tabella Utenti denormalizzata memorizza non solo le informazioni reali su un utente ma anche i vincoli, quindi in termini di funzionalità la tabella non corrisponde pienamente al suo nome.
Ripetizione di un singolo dettaglio con il suo master
Quando si ha a che fare con dati storici, molte query hanno bisogno di un singolo record specifico e raramente richiedono altri dettagli. Con questa tecnica di denormalizzazione del database, è possibile introdurre una nuova colonna chiave esterna per memorizzare questo record con il suo master. Quando si usa questo tipo di denormalizzazione, non dimenticare di aggiungere del codice che aggiornerà la colonna denormalizzata quando viene aggiunto un nuovo record.
| Vantaggi | Svantaggi |
|---|---|
| Non c’è bisogno di creare join per le query che hanno bisogno di un singolo record | Sono possibili incoerenze nei dati poiché il valore di un record deve essere ripetuto |
Esempio
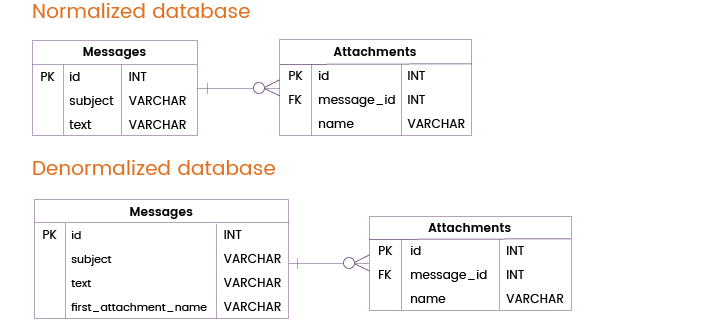
Spesso, gli utenti inviano non solo messaggi ma anche allegati. La maggior parte dei messaggi sono inviati senza allegato o con un solo allegato, ma in alcuni casi gli utenti allegano diversi file a un messaggio.
Possiamo evitare un join di tabella denormalizzando la tabella Messages con l’aggiunta della colonna first_attachment_name. Naturalmente, se un messaggio contiene più di un allegato, solo il primo allegato sarà preso dalla tabella Messages mentre gli altri allegati saranno memorizzati in una tabella Attachments separata e, quindi, richiederanno un join di tabella. Nella maggior parte dei casi, comunque, questa tecnica di denormalizzazione sarà davvero utile.
Aggiungimento di chiavi di cortocircuito
Se un database ha più di tre livelli di dettaglio principale e hai bisogno di interrogare solo i record dei livelli più bassi e più alti, puoi denormalizzare il tuo database creando chiavi di cortocircuito che collegano i record dei nipoti di livello più basso ai record dei nonni di livello più alto. Questa tecnica aiuta a ridurre il numero di join della tabella quando si eseguono le query.
| Vantaggi | Svantaggi |
|---|---|
| Meno tabelle vengono unite durante le query | Necessità di usare più chiavi esterne |
| Necessita di codice extra per garantire la coerenza dei valori |
Esempio
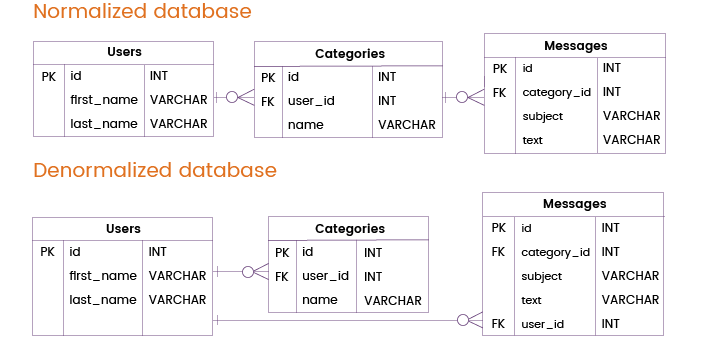
Ora immaginiamo che un servizio di messaggistica email debba gestire frequenti query che richiedono dati solo dalle tabelle Utenti e Messaggi, senza rivolgersi alla tabella Categories. In un database normalizzato, tali query avrebbero bisogno di unire le tabelle Utenti e Categorie.
Per migliorare le prestazioni del database ed evitare tali unioni, possiamo aggiungere una chiave primaria o unica dalla tabella Utenti direttamente alla tabella Messaggi. In questo modo possiamo fornire informazioni sugli utenti e sui messaggi senza interrogare la tabella Categories, il che significa che possiamo fare a meno di un join ridondante.
Svantaggi della denormalizzazione del database
Ora ti starai chiedendo: denormalizzare o non denormalizzare?
Anche se la denormalizzazione sembra il modo migliore per aumentare le prestazioni di un database e, di conseguenza, di un’applicazione in generale, si dovrebbe ricorrere ad essa solo quando altri metodi si dimostrano inefficienti. Per esempio, spesso le prestazioni insufficienti di un database possono essere causate da query scritte in modo errato, codice applicativo difettoso, design inconsistente degli indici o anche configurazione hardware impropria.
La denormalizzazione sembra allettante ed estremamente efficiente in teoria, ma presenta una serie di svantaggi di cui bisogna essere consapevoli prima di procedere con questa strategia:
- Spazio di archiviazione extra
Quando si denormalizza un database, si devono duplicare molti dati. Naturalmente, il vostro database richiederà più spazio di memorizzazione.
- Documentazione aggiuntiva
Ogni singolo passo che fate durante la denormalizzazione deve essere adeguatamente documentato. Se in seguito cambiate il progetto del vostro database, dovrete rivedere tutte le regole che avete creato in precedenza: potreste non averne bisogno o potreste dover aggiornare particolari regole di denormalizzazione.
- Potenziali anomalie nei dati
Quando si denormalizza un database, bisogna capire che si ottengono più dati che possono essere modificati. Di conseguenza, è necessario prendersi cura di ogni singolo caso di dati duplicati. Si dovrebbero usare trigger, stored procedure e transazioni per evitare anomalie nei dati.
- Più codice
Quando si denormalizza un database si modificano le query di selezione, e anche se questo porta un sacco di benefici ha il suo prezzo – è necessario scrivere codice extra. È anche necessario aggiornare i valori nei nuovi attributi che si aggiungono ai record esistenti, il che significa che è richiesto ancora più codice.
- Operazioni più lente
La denormalizzazione del database può velocizzare il recupero dei dati ma allo stesso tempo rallenta gli aggiornamenti. Se la vostra applicazione ha bisogno di eseguire molte operazioni di scrittura sul database, potrebbe mostrare prestazioni più lente rispetto a un database normalizzato simile. Quindi assicuratevi di implementare la denormalizzazione senza danneggiare l’usabilità della vostra applicazione.
Consigli per la denormalizzazione del database
Come potete vedere, la denormalizzazione è un processo serio che richiede molto impegno e abilità. Se volete denormalizzare i database senza problemi, seguite questi utili consigli:
- Invece di cercare di denormalizzare subito l’intero database, concentratevi su parti particolari che volete velocizzare.
- Fate del vostro meglio per imparare bene il design logico della vostra applicazione per capire quali parti del vostro sistema possono essere interessate dalla denormalizzazione.
- Analizzate quanto spesso i dati vengono cambiati nella vostra applicazione; se i dati cambiano troppo spesso, mantenere l’integrità del vostro database dopo la denormalizzazione potrebbe diventare un vero problema.
- Guarda bene quali parti della tua applicazione hanno problemi di performance; spesso, puoi velocizzare la tua applicazione mettendo a punto le query piuttosto che denormalizzare il database.
- Impara di più sulle tecniche di memorizzazione dei dati; scegliere le più rilevanti può aiutarti a fare a meno della denormalizzazione.
Pensieri finali
Dovresti sempre iniziare a costruire un database normalizzato pulito e ad alte prestazioni. Solo se avete bisogno che il vostro database sia più performante in particolari compiti (come il reporting) dovreste optare per la denormalizzazione. Se si esegue la denormalizzazione, fare attenzione e assicurarsi di documentare tutte le modifiche apportate al database.
Prima di procedere alla denormalizzazione, porsi le seguenti domande:
- Il mio sistema può raggiungere prestazioni sufficienti senza denormalizzazione?
- Le prestazioni del mio database potrebbero diventare inaccettabili dopo la denormalizzazione?
- Il mio sistema diventerà meno affidabile?
Se la risposta a una di queste domande è sì, allora è meglio evitare la denormalizzazione perché probabilmente si rivelerà inefficiente per la vostra applicazione. Se, invece, la denormalizzazione è la vostra unica opzione, dovreste prima normalizzare correttamente il database, poi passare alla denormalizzazione, seguendo attentamente e rigorosamente le tecniche che abbiamo descritto in questo articolo.
Per ulteriori approfondimenti sulle ultime tendenze nello sviluppo del software, iscrivetevi al nostro blog.