Una domanda comune che vedo da molte persone nuove al T-SQL è come trovare dati in una stringa ed estrarli. Questa è una richiesta molto comune, poiché i nostri database contengono molte stringhe. Spesso troviamo che le persone che usano applicazioni incorporano informazioni in una stringa, con l’aspettativa che il programma sarà in grado di rimuovere facilmente queste informazioni in seguito. In questo articolo, vedrò come estrarre questi dati usando SUBSTRING, CHARINDEX, e PATINDEX.
Questo è un articolo di ritorno alle basi che spero sia utile per quegli sviluppatori e DBA che sono nuovi di SQL Server e cercano di migliorare le loro abilità. Sentitevi liberi di passarlo.
Trovare il PO coerente
Un esempio è un numero di fattura o un numero PO. Ho visto spesso questi dati incorporati in campi di testo, con un requisito successivo per estrarre questo numero dal campo. Questo è un tipo comune di dati che viene aggiunto ad un campo in una tabella da qualche parte, come ad esempio in una tabella clienti. Potremmo avere utenti, o un’applicazione, che decidono di aggiungere questi dati per denormalizzare i nostri dati.
Supponiamo di avere una tabella che contiene informazioni come questa:
CREATE TABLE Customers( CustomerID INT, CustomerName VARCHAR(500), CustomerNotes VARCHAR(MAX), Active TINYINT);GOINSERT dbo.Customers ( CustomerID , CustomerName , CustomerNotes , Active ) VALUES ( 1, 'Acme Inc', 'Last PO:20154402', 1) , ( 2, 'Roadrunner Enterprises', 'Last PO:20140322', 1 ) , ( 3, 'Wile E. Coyote and Sons', 'Unreliable payments', 0)
Se guardo i dati, vediamo che qualcuno ha deciso di includere informazioni importanti nel campo note. Sono sicuro che molte persone esperte rabbrividiranno di fronte a questo uso dei campi in una tabella, ma questo succede più spesso di quanto molti di noi vorrebbero.
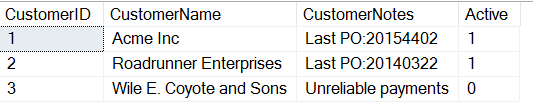
Se ora voglio tirare fuori l’OP da questo campo, forse per un rapporto che è necessario, o forse perché ho intenzione di ETL questi dati in un posto più appropriato, posso usare la funzione SUBSTRING in T-SQL. Uso questa funzione quando so dove all’interno di una stringa sto cercando di ottenere dei dati.
In questo caso, posso vedere che i primi 8 caratteri del campo CustomerNotes sono spesso “Last PO:”. Con questo, posso iniziare dal 9° carattere e poi ottenere i prossimi 8 caratteri (lunghezza dell’OP). Userò questa query.
SELECT CustomerID , 'PO' = SUBSTRING(CustomerNotes, 9, 8)FROM dbo.Customers
Questo restituirà gli OP, ma ottengo altri dati.
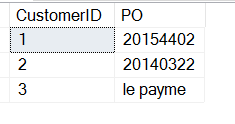
Nessuna preoccupazione, posso facilmente filtrare questo (una discussione per un altro articolo).
SELECT CustomerID , 'PO' = SUBSTRING(CustomerNotes, 9, 8)FROM dbo.Customers WHERE customerNotes LIKE '%PO%'
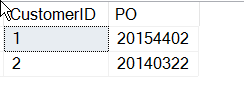
Ora, ho finito, giusto? Beh, forse no.
Un PO incoerente
Nei dati che ho guardato finora, il numero di PO è sempre al posto giusto. Tuttavia supponiamo che non tutti i nostri addetti all’inserimento dati lavorino con i clienti allo stesso modo. Ecco un po’ di dati in più per mostrare cosa intendo:
INSERT dbo.Customers ( CustomerID , CustomerName , CustomerNotes , Active ) VALUES ( 4, 'Beep Beep Enterprises', 'Remember their slogan: We go fast. Last PO:20154402', 1) , ( 5, 'Goldberg Supplies', 'Preferred. Last PO:20140322', 1 ) , ( 6, 'Bugs Deliveries', 'Fast Last PO:20145554', 0)
Ora eseguiamo il nostro script di sopra. Otteniamo questi dati:
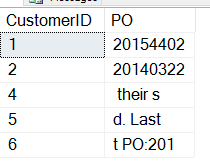
Non proprio quello che vogliamo. Il problema qui è che l’inizio del SUBSTRING non è quello che vogliamo. Abbiamo bisogno di iniziare con la posizione del numero dell’OP, forse con la posizione di “PO:”. Come possiamo ottenerlo?
Abbiamo un paio di scelte, ma inseriamo CHARINDEX e PATINDEX. Entrambi ci permettono di cercare una stringa e trovare un’altra stringa al suo interno. Entrambi possono funzionare qui, ma lasciate che vi mostri come funzionano sui nostri dati di test. Eseguo questa query:
SELECT CustomerID , CustomerNotes , 'Charindex_StartPO' = CHARINDEX('PO:', CustomerNotes) , 'Patindex_StartPO' = PATINDEX('%PO:%', CustomerNotes) , 'PO' = SUBSTRING(CustomerNotes, 9, 8) FROM dbo.Customers
E otteniamo questi risultati:
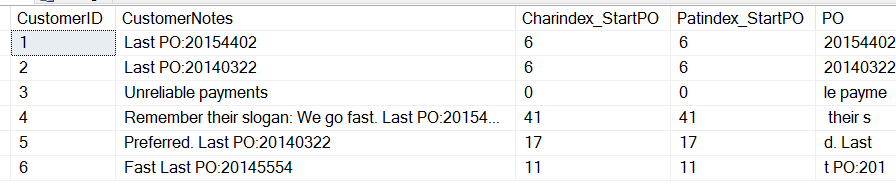
Nota che possiamo vedere che entrambe le funzioni restituiscono lo stesso valore, la posizione iniziale della “P” in “PO”. Ci sono alcune differenze. CHARINDEX può iniziare da una certa posizione nella stringa, mentre PATINDEX può prendere dei caratteri jolly. In questo caso semplicistico, possiamo usare entrambi.
Utilizzerò CHARINDEX qui, e altererò la mia query in questo modo:
SELECT CustomerID , 'PO' = SUBSTRING(CustomerNotes, CHARINDEX('PO:', CustomerNotes), 8) FROM dbo.Customers WHERE customerNotes LIKE '%PO%';
Che mi dà questo, che non è quello che voglio.
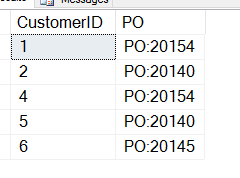
Ho dimenticato che CHARINDEX mi dà la posizione iniziale dell’OP, quindi devo aggiungere a questo valore. Ecco una query che funziona:
SELECT CustomerID , 'PO' = SUBSTRING(CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3, 8) FROM dbo.Customers WHERE customerNotes LIKE '%PO%';
Nota che ho aggiunto 3 al risultato della funzione CHARINDEX. Ecco i risultati:
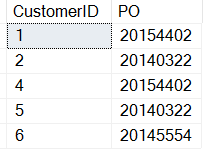
L’OP cresce
Sembra che questa sia una buona query, ma immaginiamo di aggiungere altri dati.
Nota che in questo caso, abbiamo ordini di acquisto che sono cresciuti in dimensione. Alcuni sono di 8 caratteri e altri di 9. Certamente possiamo prendere solo 9 caratteri, ma potremmo crescere fino a 10 o più. Inoltre, abbiamo altre note dopo l’OP in alcuni punti.
Modifichiamo la nostra query per vedere cosa possiamo fare. Ho aggiunto un twist al mio CHARINDEX.
SELECT CustomerID , CustomerNotes , 'Start of PO' = CHARINDEX('PO:', CustomerNotes)+3 , 'End of PO' = CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) , 'PO' = SUBSTRING(CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3, 8) FROM dbo.Customers WHERE customerNotes LIKE '%PO%';
Ecco i risultati:
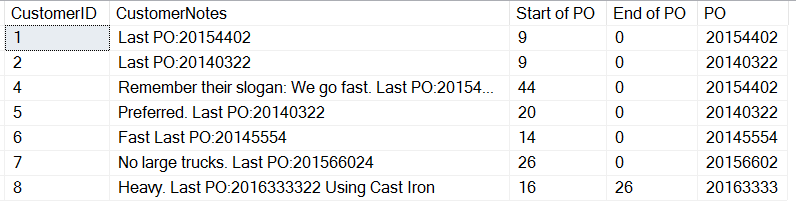
Se guardiamo bene, vediamo che la nostra ultima voce, con il testo dopo l’OP ci dà un risultato CHARINDEX. Questo perché stiamo cercando una stringa, otteniamo uno 0 se non viene trovata nessuna voce. Solo il cliente 8 ha uno spazio dopo l’OP. Questo significa che possiamo calcolare la lunghezza dell’OP per l’ultima voce, ma che dire di tutte le altre voci che hanno un formato diverso?
Possiamo usare una dichiarazione CASE qui, poiché abbiamo due possibilità. Un CASE controllerà la presenza di uno spazio e restituirà l’indice dello spazio all’interno della stringa. L’altro restituirà la lunghezza della stringa stessa, quando non esiste uno spazio. Questo mi dà un codice come questo:
Aggiornamento: I miei calcoli erano sbagliati. Ho cambiato da -3 a -2 nel codice qui sotto.
SELECT CustomerID , CustomerNotes , 'Start of PO' = CHARINDEX('PO:', CustomerNotes)+3 , 'End of PO' = CASE WHEN CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) = 0 THEN LEN(CustomerNotes) ELSE CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) END , 'Real End of PO' = CASE WHEN CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) = 0 THEN LEN(customernotes) ELSE CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) END - CHARINDEX('PO:', CustomerNotes) , 'PO' = SUBSTRING(CustomerNotes , CHARINDEX('PO:', CustomerNotes)+3 , CASE WHEN CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) = 0 THEN LEN(customernotes) ELSE CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) END - CHARINDEX('PO:', CustomerNotes) - 2 ) FROM dbo.Customers WHERE customerNotes LIKE '%PO%';
Se guardiamo questo codice, è molto simile al codice SUBSTRING che abbiamo usato prima, ma ora invece di una lunghezza fissa, 8, per il numero di caratteri da restituire, stiamo restituendo valori con una formula. La formula è essenzialmente la fine reale dell’OP (la quinta colonna nel set di risultati) e l’inizio dell’OP. C’è una dichiarazione CASE per quando otteniamo uno zero.
Ora se facciamo i conti, possiamo vedere quanto è lungo ogni OP. Per la maggior parte degli OP sono 8 caratteri (11 caratteri dopo l’inizio della “P” in “PO:”), ma 9 caratteri per il cliente 7 e 11 per il cliente 8.
Alcuni di voi potrebbero chiedersi del -3 nel codice, ma se ricordate le regole dell’aritmetica, ho effettivamente portato il meno alla quantità che rappresenta l’inizio del numero dell’OP.
Conclusione
Questa non è la fine delle possibilità per gli OP incorporati in un campo note. Potrei avere qualcosa come “test PO: 201530444. Nuovo test” e questo causerebbe problemi con il nostro codice. In effetti, ci sono molti altri casi che dovrei gestire nel mondo reale.
Questo articolo è nato da alcuni problemi di estrazione di stringhe che ho dovuto risolvere nel mondo reale, e questi tipi di problemi si verificano. Spero di avervi dato alcune abilità da mettere in pratica che vi aiuteranno nella vostra manipolazione delle stringhe in SQL Server.
Come per ogni tecnica che potreste imparare qui, assicuratevi di valutare l’impatto sulle prestazioni. Eseguite il vostro codice su un grande insieme di dati di test e determinate quanto bene questa tecnica possa funzionare rispetto ad altre tecniche. Vi raccomanderei di usare una tabella di conteggio per generare dati su una scala più grande delle vostre tabelle di produzione.
Le manipolazioni delle stringhe possono essere computazionalmente costose in SQL Server, quindi assicuratevi di capire l’impatto delle vostre scelte prima di implementare il codice in un sistema di produzione.