En mi primer post sobre redes neuronales, hablé de un modelo de representación para redes neuronales y de cómo podemos alimentar entradas y calcular una salida. Esta salida la calculamos, capa por capa, combinando las entradas de la capa anterior con los pesos de cada conexión neurona-neurona. Mencioné que hablaríamos de cómo encontrar los pesos adecuados para conectar las neuronas entre sí en un futuro post – ¡este es ese post!
Resumen
En el post anterior sólo había asumido que teníamos un conocimiento mágico previo de los pesos adecuados para cada red neuronal. En este post, realmente vamos a averiguar cómo conseguir que nuestra red neuronal «aprenda» los pesos adecuados. Sin embargo, para tener un punto de partida, vamos a inicializar cada uno de los pesos con valores aleatorios como una conjetura inicial. Volveremos a revisar este paso de inicialización aleatoria más adelante en el post.
Dados nuestros pesos inicializados al azar que conectan cada una de las neuronas, ahora podemos alimentar nuestra matriz de observaciones y calcular las salidas de nuestra red neuronal. Esto se llama propagación hacia adelante. Dado que elegimos nuestros pesos al azar, nuestra salida probablemente no va a ser muy buena con respecto a nuestra salida esperada para el conjunto de datos.
Así que, ¿a dónde vamos desde aquí?
Bueno, para empezar, vamos a definir cómo es una «buena» salida. En concreto, desarrollaremos una función de coste que penalice las salidas que se alejen del valor esperado.
A continuación, tenemos que encontrar una manera de cambiar los pesos para que la función de coste mejore. Cualquier camino dado desde una neurona de entrada a una neurona de salida es esencialmente sólo una composición de funciones; como tal, podemos utilizar derivadas parciales y la regla de la cadena para definir la relación entre cualquier peso dado y la función de coste. Podemos utilizar este conocimiento para aprovechar el descenso de gradiente en la actualización de cada uno de los pesos.
Requisitos previos
Cuando estaba aprendiendo por primera vez la retropropagación, mucha gente trató de abstraer las matemáticas subyacentes (cadenas de derivadas) y nunca fui realmente capaz de entender qué diablos estaba pasando hasta que vi la conferencia del profesor Winston en el MIT. Espero que este post ofrezca una mejor comprensión de la retropropagación que simplemente «este es el paso en el que enviamos el error hacia atrás para actualizar los pesos».
Con el fin de comprender plenamente los conceptos discutidos en este post, usted debe estar familiarizado con lo siguiente:
Derivadas parciales
Este post va a ser un poco denso con un montón de derivadas parciales. Sin embargo, espero que incluso un lector sin conocimientos previos de cálculo multivariante pueda seguir la lógica detrás de la retropropagación.
Si no estás familiarizado con el cálculo, $\frac{{parcial f\left( x \right)}}{{{parcial x}}$ probablemente parecerá bastante extraño. Puedes interpretar esta expresión como «¿cómo cambia $f\left( x \right)$ cuando cambio $x$?» Esto será útil porque podemos hacer preguntas como «¿Cómo cambia la función de coste cuando cambio este parámetro? Aumenta o disminuye la función de coste?» en busca de los parámetros óptimos.
Si quieres repasar el cálculo multivariante, echa un vistazo a las lecciones de Khan Academy sobre el tema.
Descenso de gradiente
Para evitar que este post se alargue demasiado, he separado el tema del descenso de gradiente en otro post. Si no estás familiarizado con el método, asegúrate de leerlo aquí y entenderlo antes de continuar con este post.
Multiplicación de matrices
Aquí tienes un repaso rápido de Khan Academy.
Empezando por lo más sencillo
Para saber cómo usar el descenso de gradiente en el entrenamiento de una red neuronal, vamos a empezar con la red neuronal más sencilla: una neurona de entrada, una neurona de capa oculta y una neurona de salida.

Para mostrar una imagen más completa de lo que ocurre, he ampliado cada neurona para mostrar 1) la combinación lineal de entradas y pesos y 2) la activación de esta combinación lineal. Es fácil ver que el paso de propagación hacia adelante es simplemente una serie de funciones donde la salida de una alimenta como la entrada a la siguiente.
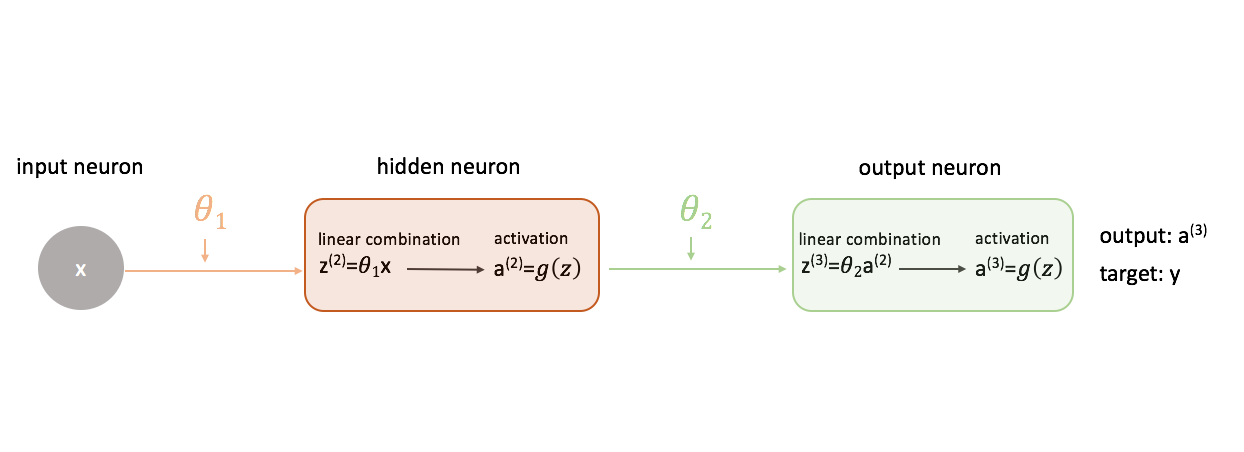
Definiendo el «buen» rendimiento en una red neuronal
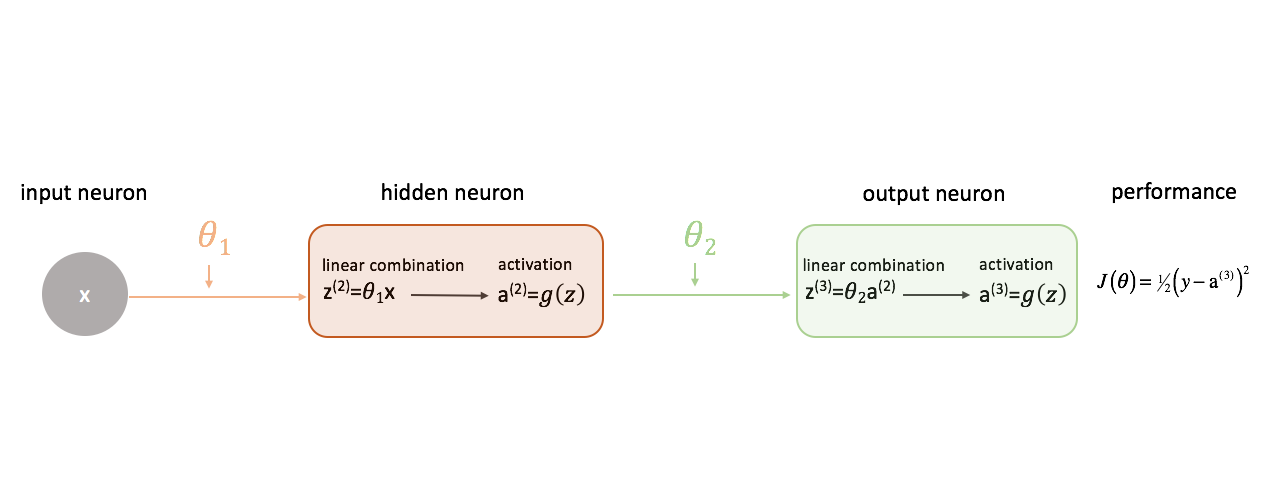
Definamos nuestra función de coste para que sea simplemente el error al cuadrado.
Hay un sinfín de funciones de coste que podríamos utilizar, pero para esta red neuronal el error al cuadrado funcionará bien.
Recuerde, queremos evaluar la salida de nuestro modelo con respecto a la salida objetivo en un intento de minimizar la diferencia entre los dos.
Relación de los pesos con la función de coste
Para minimizar la diferencia entre la salida de nuestra red neuronal y la salida objetivo, necesitamos saber cómo cambia el rendimiento del modelo con respecto a cada parámetro de nuestro modelo. En otras palabras, necesitamos definir la relación (léase: derivada parcial) entre nuestra función de coste y cada peso. A continuación, podemos actualizar estos pesos en un proceso iterativo utilizando el descenso de gradiente.
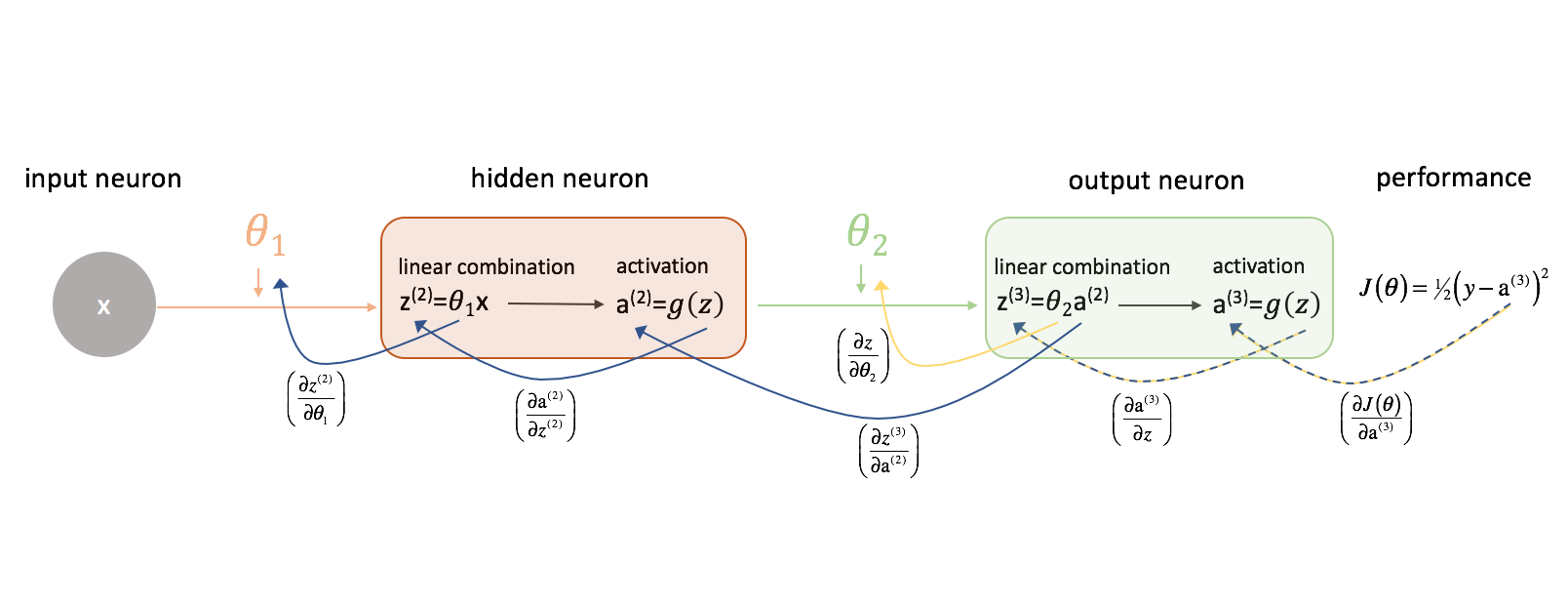
Veamos primero $\frac{{parcial J\left( \theta \right)}{{parcial {\theta _2}}$. Tenga en cuenta la siguiente figura a medida que avanzamos.
Tomemos un momento para examinar cómo podríamos expresar la relación entre $J\left( \theta \right)$ y $\theta _2$. Tenga en cuenta cómo $\theta _2$ es una entrada a ${z^(3)}}$, que es una entrada a ${\rm{a}^(3)}}$, que es una entrada a $J\left( \theta \right)$. Cuando tratamos de calcular una derivada de este tipo, podemos utilizar la regla de la cadena para resolver.
Como recordatorio, la regla de la cadena establece:
Apliquemos la regla de la cadena para resolver $\frac{{parcial J\left( \theta \right)}}{{parcial {\theta _2}}$.
Por una lógica similar, podemos encontrar $\frac{{parcial J\left( \theta \right)}}{{parcial {\theta _1}}$.
Para mayor claridad, he actualizado nuestro diagrama de red neuronal para visualizar estas cadenas. Asegúrate de que te sientes cómodo con este proceso antes de continuar.
Añadir complejidad
Ahora vamos a probar este mismo enfoque en un ejemplo un poco más complicado. Ahora, veremos una red neuronal con dos neuronas en nuestra capa de entrada, dos neuronas en una capa oculta y dos neuronas en nuestra capa de salida. Por ahora, ignoraremos las neuronas de sesgo que faltan en las capas de entrada y oculta.
Tomemos un segundo para repasar la notación que utilizaré para que puedas seguir estos diagramas. El superíndice (1) denota en qué capa está el objeto y el subíndice denota a qué neurona nos referimos en una capa determinada. Por ejemplo, $a_1^{(2)}$ es la activación de la primera neurona de la segunda capa. Para los valores de los parámetros $\theta$, me gusta leerlos como una etiqueta de correo – el primer valor denota a qué neurona se envía la entrada en la siguiente capa, y el segundo valor denota desde qué neurona se envía la información. Por ejemplo, ${\theta _{21}^(2)}} se utiliza para enviar la entrada a la 2ª neurona, desde la 1ª neurona de la capa 2. El superíndice que denota la capa corresponde con el lugar de donde proviene la entrada. Esta notación es consistente con la representación matricial que discutimos en mi post sobre representación de redes neuronales.
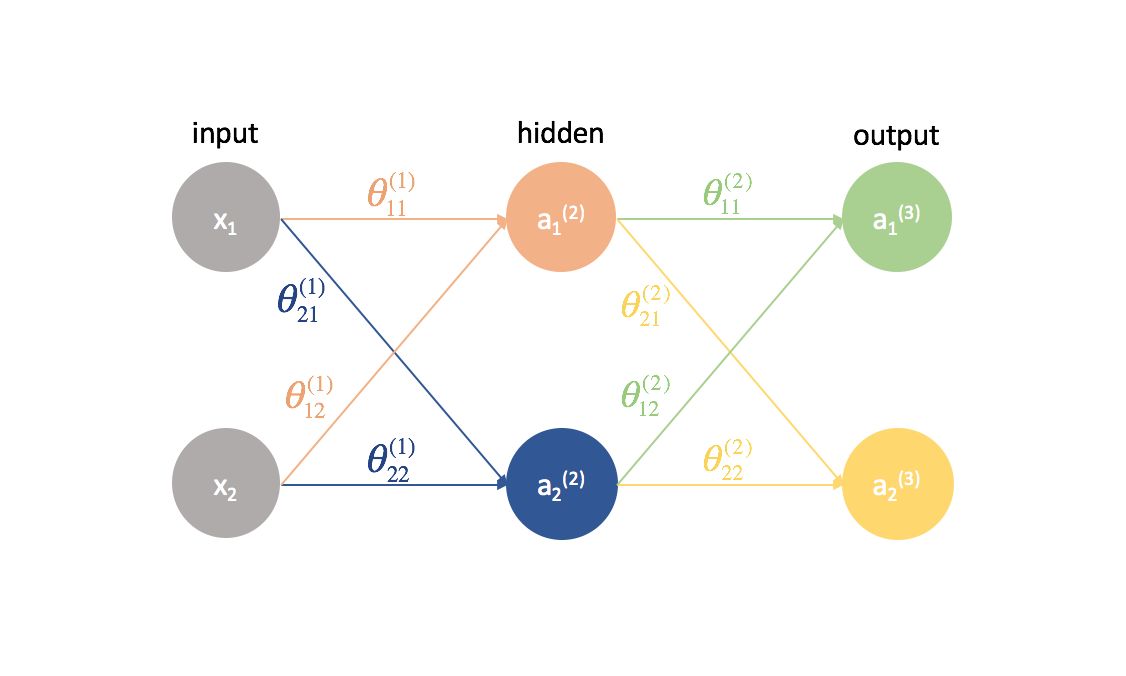
Ampliemos esta red para exponer toda la matemática que está ocurriendo.
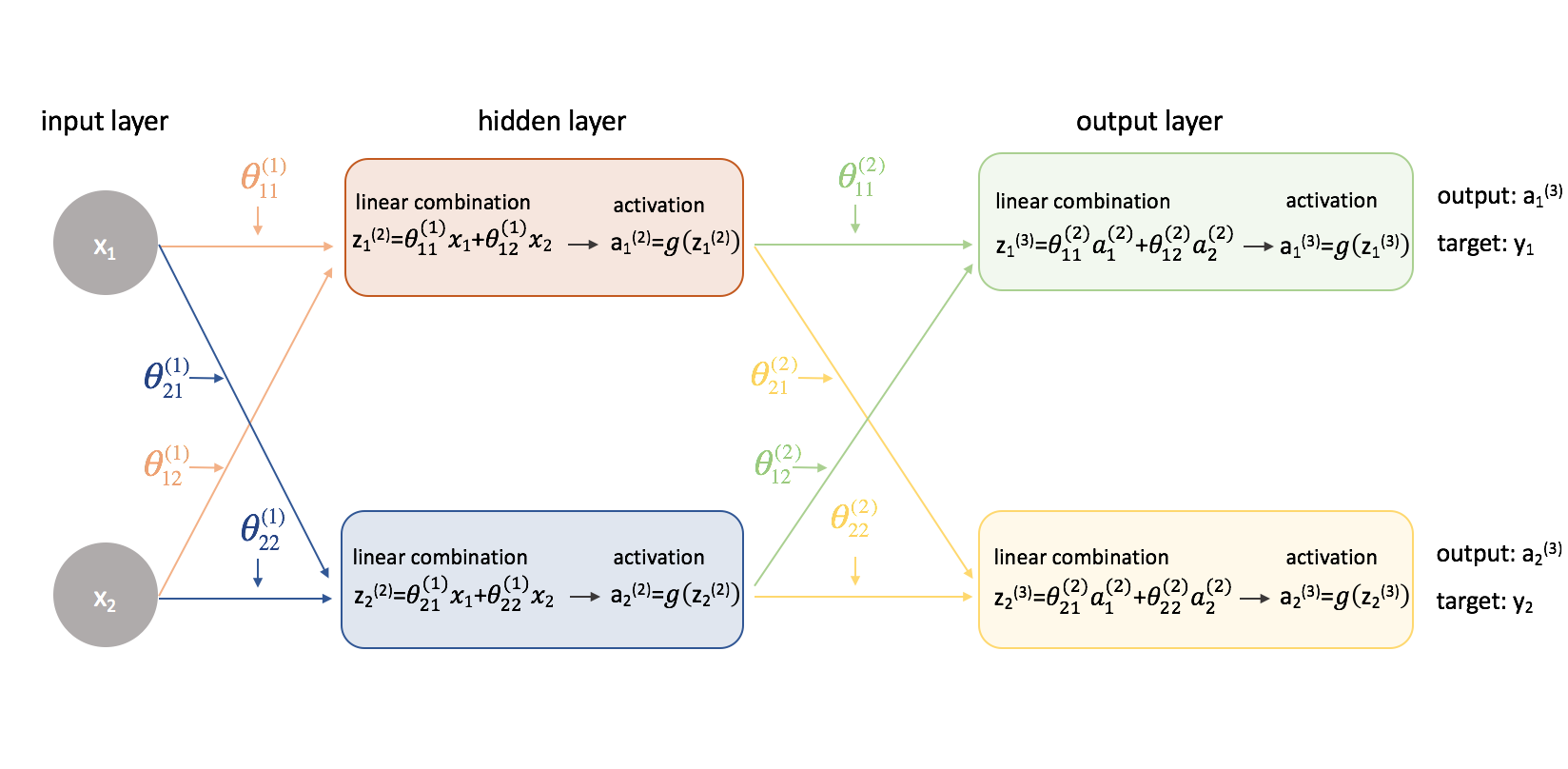
¡Caramba! La cosa se ha complicado un poco más. Voy a recorrer el proceso para encontrar una de las derivadas parciales de la función de coste con respecto a uno de los valores de los parámetros; dejaré el resto de los cálculos como un ejercicio para el lector (y publicaré los resultados finales más abajo).
Por encima, tendremos que revisar nuestra función de coste ahora que estamos tratando con una red neuronal con más de una salida. Utilicemos ahora el error medio al cuadrado como nuestra función de coste.
Nota: Si estás entrenando con múltiples observaciones (lo que siempre harás en la práctica), también necesitaremos realizar una suma de la función de coste sobre todos los ejemplos de entrenamiento. Para esta función de coste, es común normalizar por $\frac{1}{{m}}$ donde $m$ es el número de ejemplos en su conjunto de datos de entrenamiento.
Ahora que hemos corregido nuestra función de coste, podemos ver cómo el cambio de un parámetro afecta a la función de coste. En concreto, voy a calcular $\frac{{parcial J\left( \theta \right)}}{{{parcial \theta _{11}^{(1)}}$ en este ejemplo. Mirando el diagrama, $\theta _{11}^(1)}$ afecta a la salida tanto para $a _1^(3)}$ como para $a _2^(3)}$. Como nuestra función de coste es una suma de costes individuales para cada salida, podemos calcular la cadena de derivadas para cada camino y simplemente sumarlas.
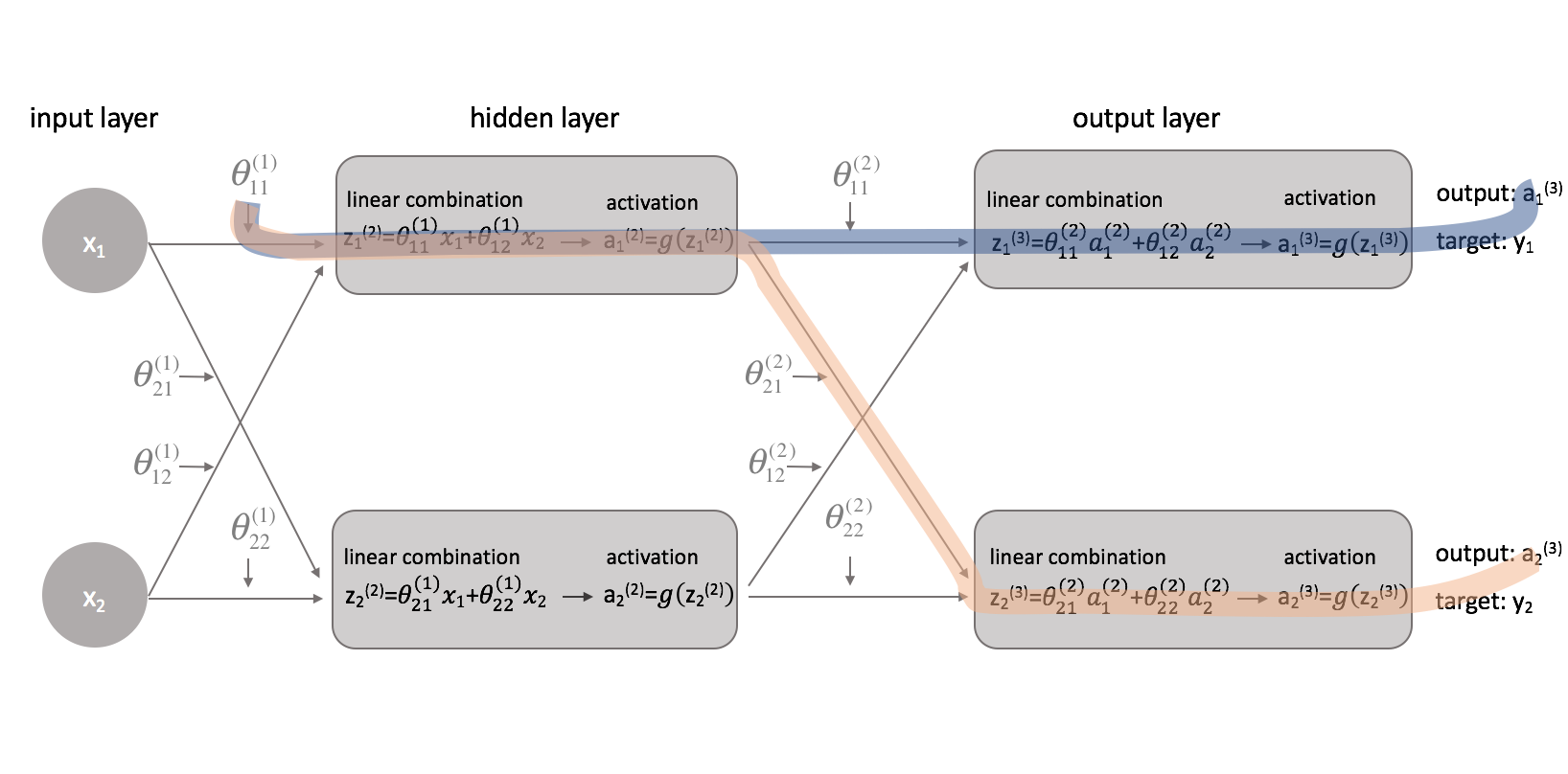
La cadena de derivadas para el camino azul es:
$ \left( {\frac{{parcial J\left( \theta \right)}{{parcial {\rm{a}} _1^{(3)}}}} \izquierda( {\frac{{parcial {\rm{a}} _1^(3)}} {{parcial z _1^(3)}}}} \derecha)\N-izquierda( {\frac{{parcial z _1^(3)}}{{parcial {\rm{a}} _1^{(2)}}}} \derecha)\N-izquierda( {\frac{{parcial {\rm{a}} _1^(2)}} {{parcial z _1^(2)}} }}}} \derecha)\NIzquierda( {\frac{parcial z _1^(2)}}{{parcial \theta _{11}^(1)} }}}} \a la derecha) $
La cadena de derivadas para la trayectoria naranja es:
$ \a la izquierda( {\frac{{parcial J\a la izquierda( \a la derecha)}{{parcial {\rm{a}} _2^{(3)}}}} \izquierda( {\frac{{parcial {\rm{a}} _2^(3)}} {{parcial z _2^(3)}}}} \derecha)\N-izquierda( {\frac{{parcial z _2^(3)}}{{parcial {\rm{a}} _1^{(2)}}}} \derecha)\N-izquierda( {\frac{{parcial {\rm{a}} _1^(2)}} {{parcial z _1^(2)}} }}}} \derecha)\NIzquierda( {\frac{parcial z _1^(2)}}{{parcial \theta _{11}^(1)} }}}} \right)$
Combinando estos, obtenemos la expresión total para $\frac{{parcial J\left( \theta \right)}}{{parcial \theta _{11}^{1)}}$.
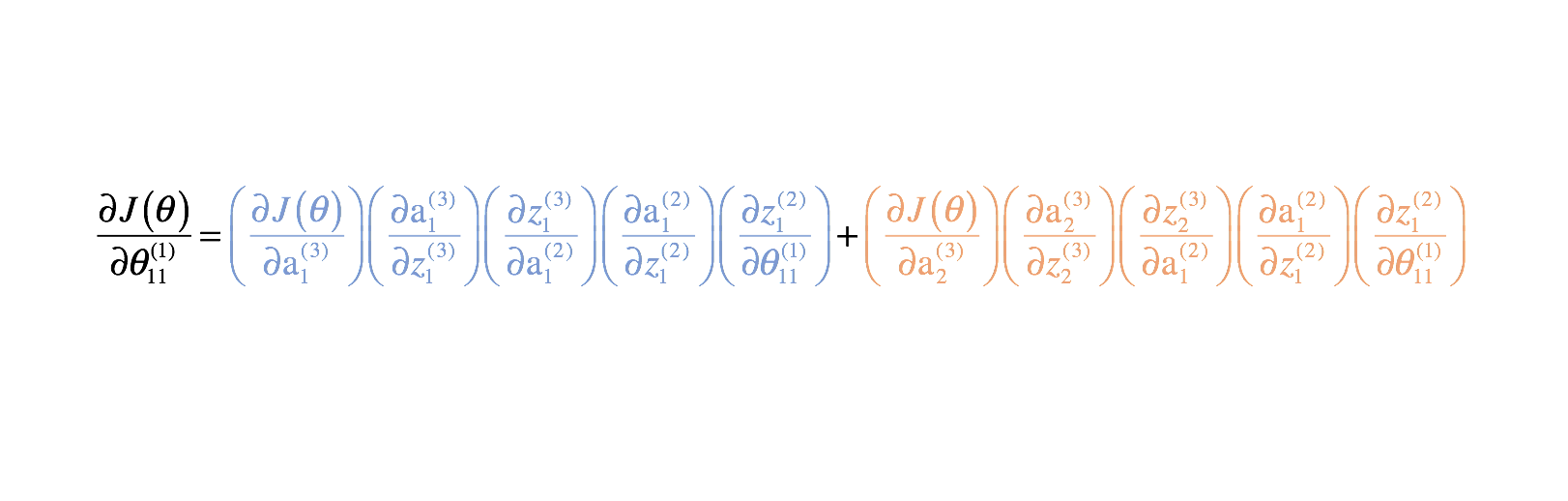
He proporcionado el resto de las derivadas parciales a continuación. Recuerda que necesitamos estas derivadas parciales porque describen cómo el cambio de cada parámetro afecta a la función de coste. Por lo tanto, podemos utilizar este conocimiento para cambiar todos los valores de los parámetros de una manera que continúe disminuyendo la función de coste hasta que converjamos en algún valor mínimo.
Parámetros de la Capa 2
Parámetros de la Capa 1
Ahí. Acabamos de pasar de una red neuronal con 2 parámetros que necesitaba 8 términos de derivadas parciales en el ejemplo anterior a una red neuronal con 8 parámetros que necesita 52 términos de derivadas parciales. Esto se nos va a ir rápidamente de las manos, sobre todo teniendo en cuenta que muchas redes neuronales que se utilizan en la práctica son mucho más grandes que estos ejemplos.
Afortunadamente, al examinar más de cerca muchas de estas derivadas parciales se repiten. Si somos inteligentes en la forma de abordar este problema, podemos reducir drásticamente el coste computacional del entrenamiento. Además, sería realmente un dolor de cabeza si tuviéramos que calcular manualmente las cadenas de derivadas para cada parámetro. Veamos lo que hemos hecho hasta ahora y veamos si podemos generalizar un método para esta locura.
Generalizando un método
Examinemos las derivadas parciales anteriores y hagamos algunas observaciones. Empezaremos por ver las derivadas parciales con respecto a los parámetros de la capa 2. Recuerda que los parámetros de la capa 2 se combinan con las activaciones de la capa 2 para alimentar la capa 3.
Parámetros de la capa 2
Analicemos las siguientes expresiones; te animo a que resuelvas las derivadas parciales a medida que avanzas para convencerte de mi lógica.
Parece que las columnas contienen valores muy similares. Por ejemplo, la primera columna contiene derivadas parciales de la función de coste con respecto a las salidas de la red neuronal. En la práctica, se trata de la diferencia entre la salida esperada y la salida real (y luego escalada por $m$) para cada una de las neuronas de salida.
La segunda columna representa la derivada de la función de activación utilizada en la capa de salida. Tenga en cuenta que para cada capa, las neuronas utilizarán la misma función de activación. Una función de activación homogénea dentro de una capa es necesaria para poder aprovechar las operaciones matriciales en el cálculo de la salida de la red neuronal. Por lo tanto, el valor de la segunda columna será el mismo para los cuatro términos.
La primera y la segunda columna se pueden combinar como $\delta _i^{(3)}$ por conveniencia más adelante. No es inmediatamente evidente por qué esto sería útil, pero usted verá como vamos hacia atrás otra capa por qué esto es útil. La gente a menudo se referirá a esta expresión como el término «error» que utilizamos para «devolver el error de la salida a través de la red». Pronto veremos por qué es así. Cada neurona de la red tendrá un término $\delta$ correspondiente que resolveremos.
La tercera columna representa cómo cambia el parámetro de interés con respecto a las entradas ponderadas para la capa actual; cuando se calcula la derivada ésta se corresponde con la activación de la capa anterior.
También me gustaría señalar que los dos primeros términos de la derivada parcial parecen referirse a la primera neurona de salida (neurona 1 de la capa 3) mientras que los dos últimos términos de la derivada parcial parecen referirse a la segunda neurona de salida (neurona 2 de la capa 3). Esto es evidente en el término $\frac{{parcial J\left( \theta \right)}}{{{parcial {\rm{a}}_i^(3)}}. Utilicemos este conocimiento para reescribir las derivadas parciales utilizando la expresión $\delta$ que definimos anteriormente.
$ \frac{{parcial J\left( \theta \right)}}{{parcial \theta _{12}^(2)}} = \delta _1^(3)}left( {\frac{{parcial z _1^(3)}}{{parcial \theta _{12}^(2)}}}} \N-derecha) $
$ \frac{{parcial J\left( \theta \right)}}{{parcial \theta _{21}^{(2)}} = \delta _2^{(3)}{{frac{{parcial z _2^{(3)}}{{parcial \theta _{21}^(2)}} \N-derecha) $
$ \frac{{parcial J\left( \theta \right)}}{{parcial \theta _{22}^(2)}} = \delta _2^{(3)} {\frac{{parcial z _2^{(3)}}{{parcial \theta _{22}^(2)}}}} \right) $
A continuación, vamos a calcular el último término de la derivada parcial. Como hemos anotado, esta derivada parcial acaba representando las activaciones de la capa anterior.
Nota: me resulta útil utilizar el gráfico de la red neuronal expandida de la sección anterior al calcular las derivadas parciales.
$ \frac{{parcial J\left( \theta \right)}}{{parcial \theta _{12}^{2}}} = \delta _1^{3}{\rm{a}} 2^(2)} $
$ \frac{{parcial J\left( \theta \right)}}{{parcial \theta _{21}^(2)}} = \delta _2^(3)}{rm{a} 1^(2)} $
$ \frac{{parcial J\left( \theta \right)}}{{parcial \theta _{22}^(2)}} = \delta _2^(3)}{rm{a} _2^{(2)} $
Parece que estamos combinando los términos de «error» con las activaciones de la capa anterior para calcular cada derivada parcial. También es interesante observar que los índices $j$ y $k$ para $\theta _{jk}$ coinciden con los índices combinados de $\delta _j^{3)}$ y ${\rm{a}} _k^{(2)}$.
Veamos si podemos averiguar una operación matricial para calcular todas las derivadas parciales en una sola expresión.
${delta ^{(3)}$ es un vector de longitud $j$ donde $j$ es igual al número de neuronas de salida.
δ (3) = f ′ ( a (3) )
${rm{a}^{2)}$ es un vector de longitud $k$ donde $k$ es el número de neuronas de la capa anterior. Los valores de este vector representan las activaciones de la capa anterior calculadas durante la propagación hacia delante; en otras palabras, es el vector de entradas a la capa de salida.
$ {a^{(2)}} = \NIzquierda $
Multiplicando estos vectores entre sí, podemos calcular todos los términos de la derivada parcial en una sola expresión.
∂J( θ ) ∂ θ ij (2) ==
Para resumir, ver el gráfico de abajo.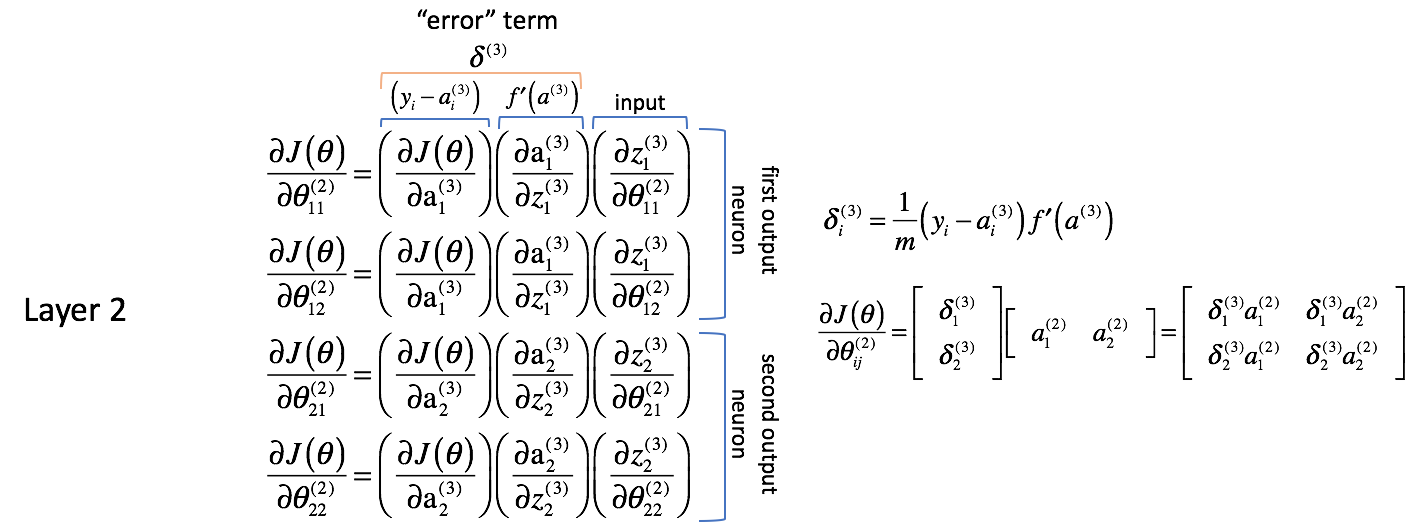
Nota: Técnicamente, la primera columna también debería ser escalada por $m$ para ser una derivada exacta. Sin embargo, mi enfoque era señalar que esta es la columna en la que estamos preocupados por la diferencia entre las salidas esperadas y reales. El término $\delta$ de la derecha tiene la expresión de la derivada completa.
Parámetros de la capa 1
Ahora echemos un vistazo y veamos lo que ocurre en la capa 1.
Mientras que los pesos de la capa 2 sólo afectaban directamente a una salida, los pesos de la capa 1 afectan a todas las salidas. Recordemos el siguiente gráfico.
Esto hace que la derivada parcial de la función de coste respecto a un parámetro se convierta ahora en una suma de diferentes cadenas. En concreto, tendremos una cadena de derivadas por cada $\delta$ que hayamos calculado en la siguiente capa hacia delante. Recuerde, empezamos en el final de la red y estamos trabajando nuestro camino hacia atrás a través de la red. Por lo tanto, la siguiente capa hacia adelante representa los valores $\delta$ que hemos calculado previamente.
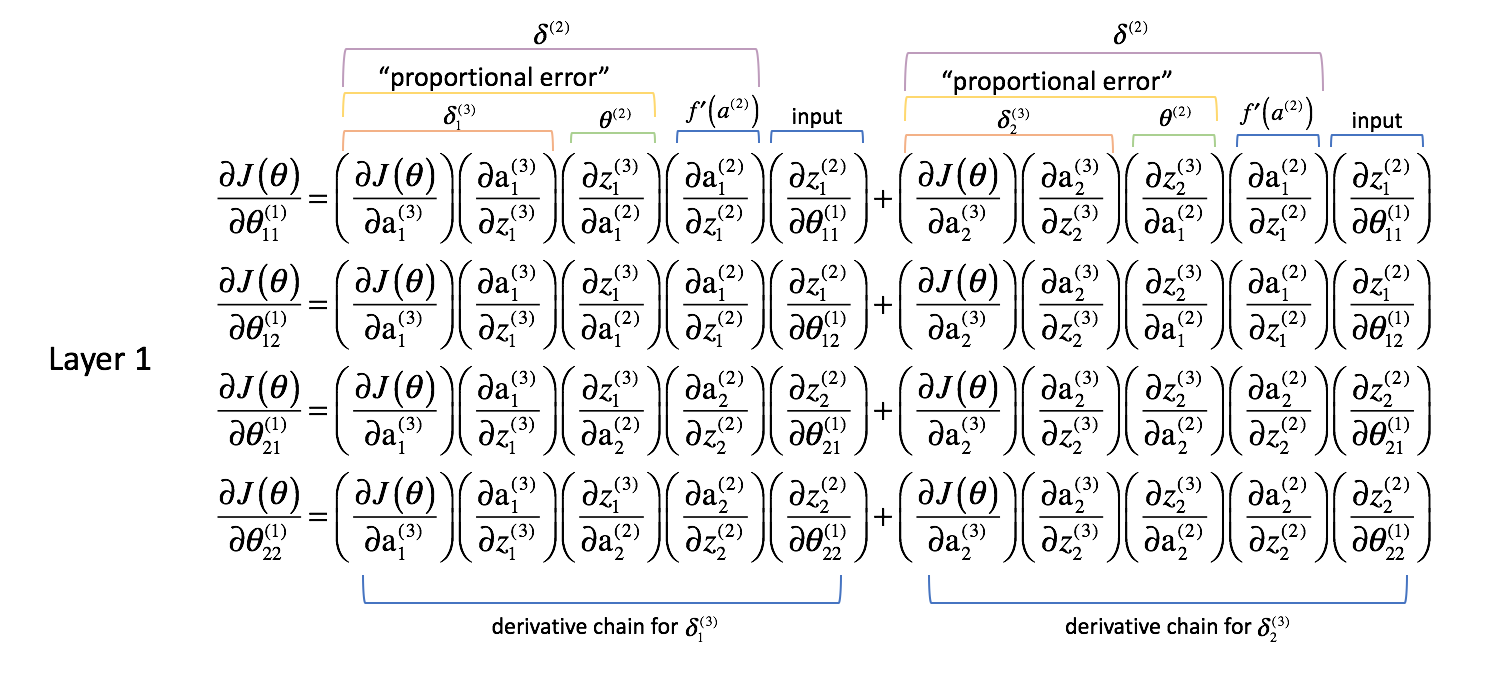
Al igual que hicimos con la capa 2, vamos a hacer algunas observaciones.
Las dos primeras columnas (de cada término sumado) se corresponden con un $\delta _j^{(3)}$ calculado en la siguiente capa hacia delante (recordemos que empezamos por el final de la red y vamos hacia atrás).
La tercera columna se corresponde con algún parámetro que conecta la capa 2 con la 3. Si consideramos $\delta _j^{(3)}$ como algún término de «error» para la capa 3, y cada cadena de derivadas es ahora una suma de estos errores, entonces esta tercera columna nos permite ponderar cada error respectivo. Así, los tres primeros términos combinados representan alguna medida del error proporcional.
También redefiniremos $\delta$ para todas las capas excluyendo la capa de salida para incluir esta combinación de errores ponderados.
$ \delta _j^{(l)} = f’\left( {{a^(l)}} \N-derecha)\N-suma de límites _{i = 1}^n {\delta _i^{(l + 1)}\theta _{ij}^(l)}} $
Podríamos escribir esto de forma más sucinta utilizando expresiones matriciales.
$ {\delta ^{(l)}} = {\delta ^{l + 1)}}{Theta ^{l)}}f’\a izquierda( {{a^(l)}} \ right) $
Nota: Es una notación estándar denotar los vectores con letras minúsculas y las matrices con letras mayúsculas. Así, $\theta$ representa un vector mientras que $\Theta$ representa una matriz.
La cuarta columna representa la derivada de la función de activación utilizada en la capa actual. Recuerde que para cada capa, las neuronas utilizarán la misma función de activación.
Por último, la quinta columna representa varias entradas de la capa anterior. En este caso, se trata de las entradas reales a la red neuronal.
Veamos con más detalle uno de los términos, $\frac{{parcial J\left( \theta \right)}{{parcial \theta _{11}^{(1)}}$.
Antes, establecimos que las dos primeras columnas de cada cadena de derivadas se calcularon previamente como $\delta _j^{(3)}$.
$ \frac{{parcial J\left( \theta \right)}}{{parcial \theta _{11}^(1)}} = \delta _1^(3)}left( {\frac{{parcial z _1^(3)}}{{parcial {\rm{a}} _1^{(2)}}}} \derecha)\N-izquierda( {\frac{{parcial {\rm{a}} _1^(2)}} {{parcial z _1^(2)}} }}}} \derecha)\NIzquierda( {\frac{parcial z _1^(2)}}{{parcial \theta _{11}^(1)} }}}} \derecha) + \delta _2^(3)}left( {\frac{{parcial z _2^(3)}}{{parcial {\rm{a}} _1^{(2)}}}} \derecha)\N-izquierda( {\frac{{parcial {\rm{a}} _1^(2)}} {{parcial z _1^(2)}} }}}} \derecha)\NIzquierda( {\frac{parcial z _1^(2)}}{{parcial \theta _{11}^(1)} }}}} \right) $
Además, establecimos que la tercera columna de cada cadena de derivadas era un parámetro que actuaba para ponderar cada uno de los respectivos términos $\delta$. También establecimos que la cuarta columna era la derivada de la función de activación.
$ \frac{{parcial J\left( \theta \right)}{{parcial \theta _{11}^(1)}} = \delta _1^(3)}theta _{11}^(2)}f’\left( {{a^(2)}} \izquierda( {\frac{{parcial z _1^(2)}}{{{parcial \theta _{11}^(1)}} \derecha) + \delta _2^(3)}\theta _{21}^(2)}f’\left( {{a^(2)}} \izquierda( {\frac{{parcial z _1^(2)}}{{parcial \theta _{11}^(1)}} \derecha) $
Factoring out $\left( {\frac{{parcial z_1^(2)}}{{parcial \theta _{11}^(1)}}}} \right)$,
$ \frac{{parcial J\left( \theta \right)}}{{parcial \theta _{11}^{1)}} = \left( {\frac{{parcial z _1^{2)}}{{parcial \theta _{11}^{1)}}}} \derecha) izquierda (delta _1^(3)}theta _{11}^(2)}f’ıa( {{a^(2)}} \derecha) + \delta _2^(3)}\theta _{21}^(2)}f’\left( {{a^(2)}} \a)} \a) $
nos queda nuestra nueva definición de $\delta_j^{(l)}$. Vamos a seguir adelante y a sustituirla.
$ \frac{{parcialmente J\left( \theta \right)}}{{parcialmente \theta _{11}^(1)}} = \left( {\frac{{parcialmente z _1^(2)}}{{parcialmente \theta _{11}^(1)} }}}} \izquierda( {\delta _1^(2)}} \right) $
Por último, establecimos que la quinta columna (${{frac{{parcial z_1^(2)}}{{parcial \theta_{11}^{1)}}}}$) se correspondía con una entrada de la capa anterior. En este caso, la derivada calcula que es $x_1$.
$ \frac{{parcial J\left( \theta \right)}}{{parcial \theta _{11}^{1)}} = \delta _1^{(2)}{x _1} $
De nuevo vamos a averiguar una operación matricial para calcular todas las derivadas parciales en una sola expresión.
$\delta ^{(2)}$ es un vector de longitud $j$ donde $j$ es el número de neuronas de la capa actual (capa 2). Podemos calcular $\delta ^{(2)}$ como la combinación ponderada de los errores de la capa 3, multiplicada por la derivada de la función de activación utilizada en la capa 2.
δ (2) = f ′ ( a (2) )=
$x$ es un vector de valores de entrada.
Multiplicando estos vectores entre sí, podemos calcular todos los términos de la derivada parcial en una sola expresión.
∂J( θ ) ∂ θ ij (1) ==
Si has llegado hasta aquí, ¡felicidades! Acabamos de calcular todas las derivadas parciales necesarias para utilizar el descenso de gradiente y optimizar los valores de nuestros parámetros. En la siguiente sección, voy a introducir una forma de visualizar el proceso que acabamos de desarrollar, además de presentar un método de extremo a extremo para la implementación de la retropropagación. Si entiendes todo hasta este punto, debería ser fácil de aquí en adelante.
Backpropagación
En la última sección, desarrollamos una forma de calcular todas las derivadas parciales necesarias para el descenso de gradiente (derivada parcial de la función de coste con respecto a todos los parámetros del modelo) utilizando expresiones matriciales. Al calcular las derivadas parciales, empezamos por el final de la red y, capa por capa, volvimos al principio. También desarrollamos un nuevo término, $\delta$, que esencialmente sirve para representar todos los términos de derivadas parciales que necesitaríamos reutilizar más tarde y progresamos, capa por capa, hacia atrás a través de la red.
Nota: La retropropagación es simplemente un método para calcular la derivada parcial de la función de coste con respecto a todos los parámetros. La optimización real de los parámetros (entrenamiento) se realiza mediante el descenso de gradiente u otra técnica de optimización más avanzada.
Generalmente, establecimos que se pueden calcular las derivadas parciales para la capa $l$ combinando los términos $\delta$ de la siguiente capa hacia adelante con las activaciones de la capa actual.
$ \frac{{parcialmente J\left( \theta \right)}}{{{parcialmente \theta _{ij}^(l)}} = {\left( {{delta ^{(l + 1)}} \\N-derecha)^T}{a^(l)}} $
Visualización de la retropropagación
Antes de definir el método formal de la retropropagación, me gustaría ofrecer una visualización del proceso.
En primer lugar, tenemos que calcular la salida de una red neuronal a través de la propagación hacia delante.
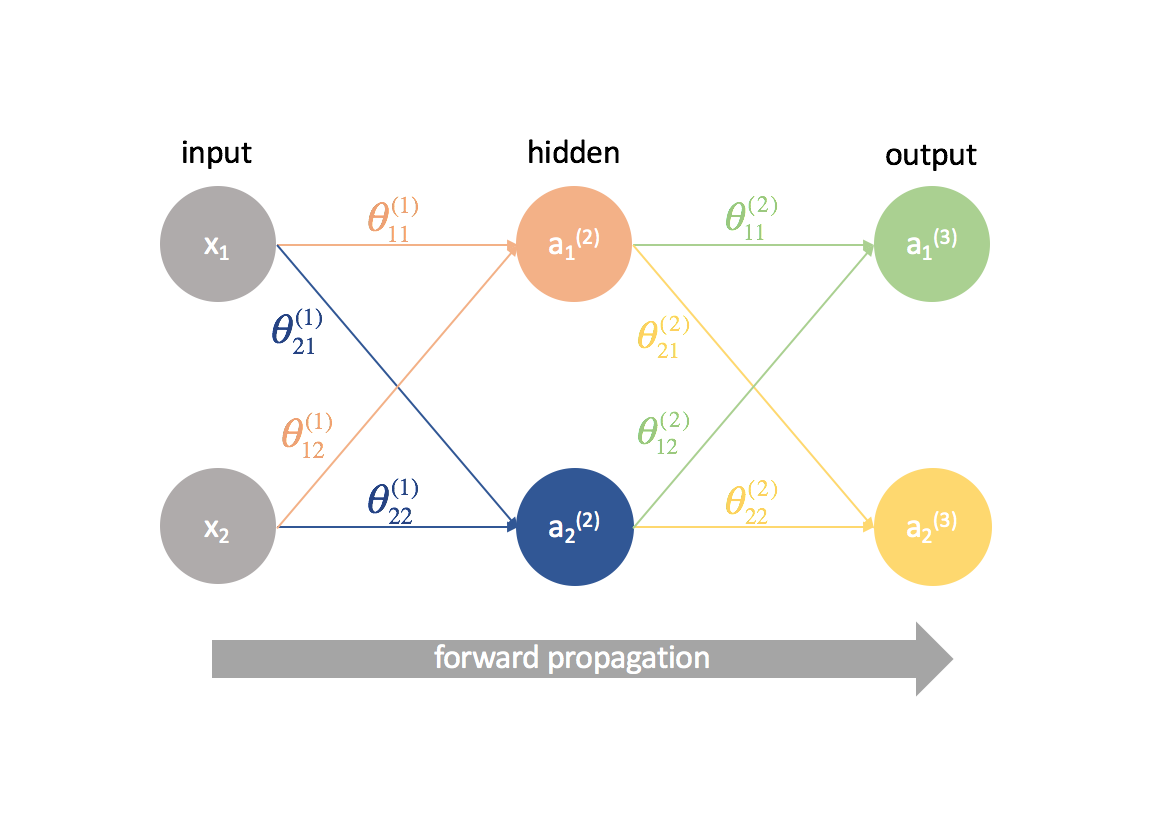
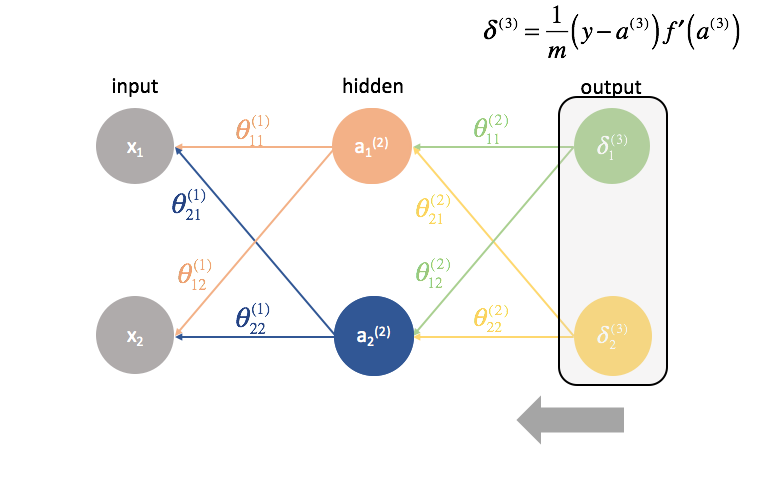
A continuación, calculamos los términos ${delta ^{(3)}}$ para la última capa de la red. Recuerde, estos términos $\delta$ consisten en todas las derivadas parciales que se utilizarán de nuevo en el cálculo de los parámetros para las capas más atrás. En la práctica, solemos referirnos a $\delta$ como el término «error».
${{Theta ^{(2)}}$ es la matriz de parámetros que conecta la capa 2 con la 3. Multiplicamos el error de la tercera capa por las entradas de la segunda capa para calcular nuestras derivadas parciales para este conjunto de parámetros.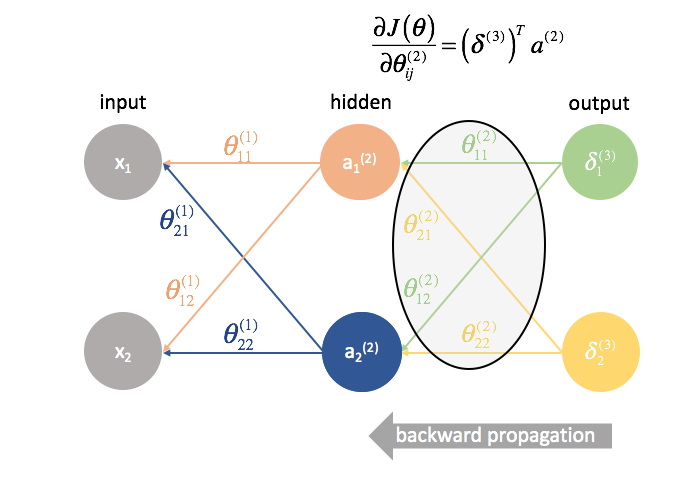
A continuación, «devolvemos» los términos de «error» exactamente de la misma manera que «enviamos» las entradas a una red neuronal. La única diferencia es que esta vez, estamos empezando desde atrás y estamos alimentando un término de error, capa por capa, hacia atrás a través de la red. De ahí el nombre: retropropagación. El acto de «devolver nuestro error» se realiza a través de la expresión ${\delta ^{(3)}}{\Theta ^{(2)}}$.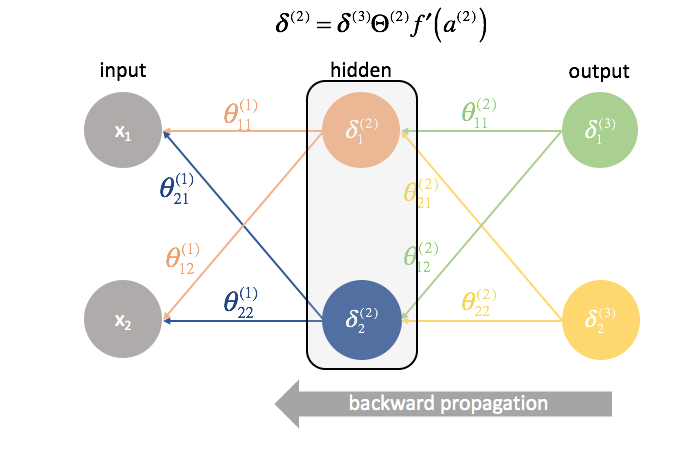
${Theta ^{(1)}} es la matriz de parámetros que conecta la capa 1 con la 2. Multiplicamos el error de la segunda capa por las entradas de la primera capa para calcular nuestras derivadas parciales para este conjunto de parámetros.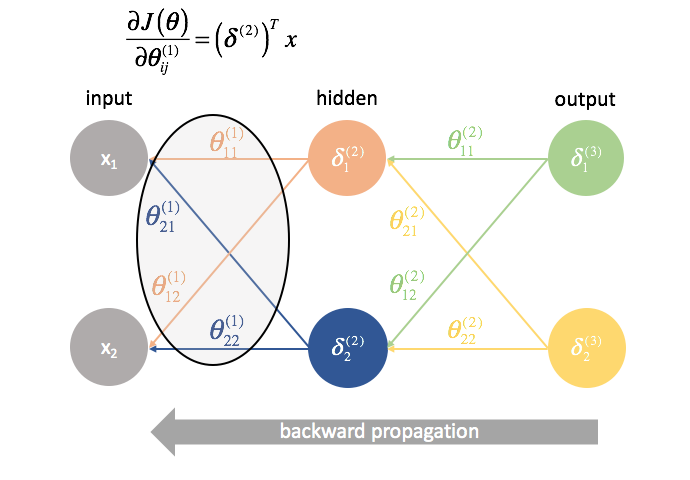
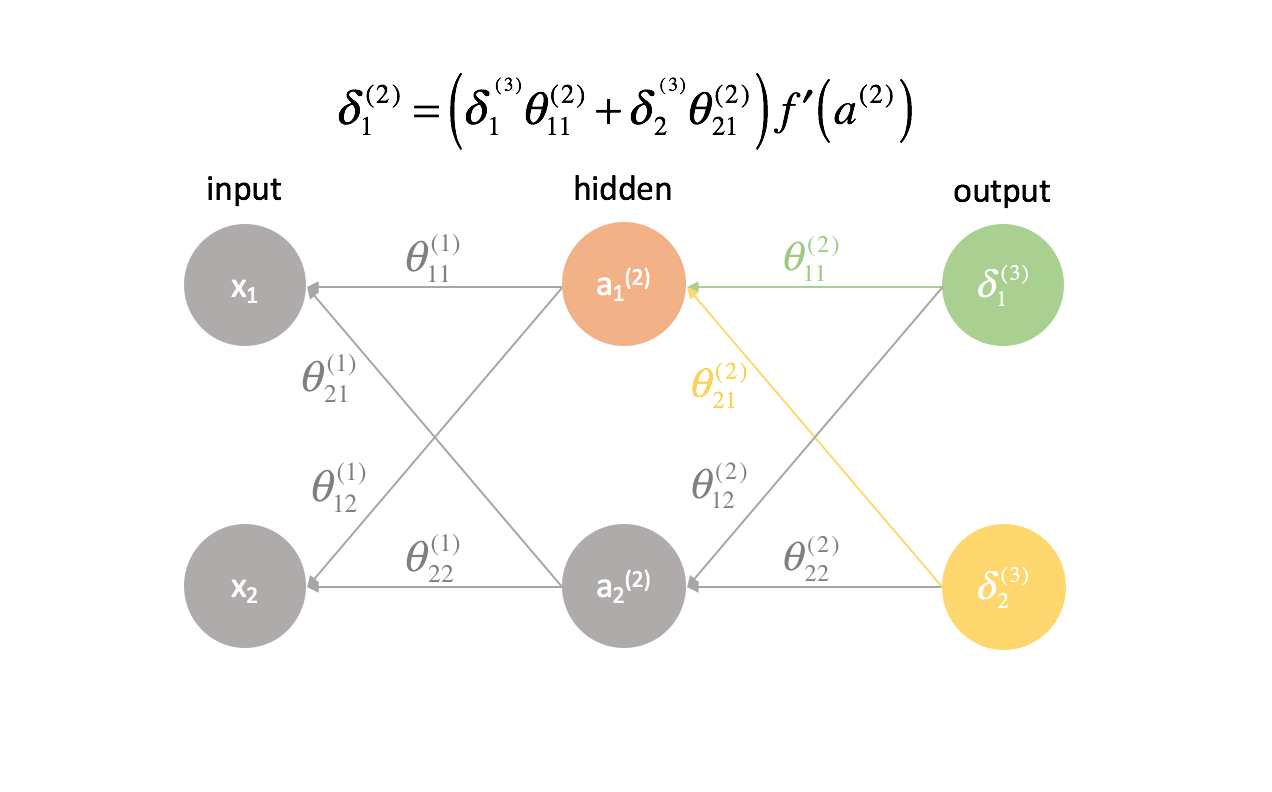
Para cada capa excepto la última, el término de «error» es una combinación lineal de los parámetros que conectan con la siguiente capa (avanzando por la red) y los términos de «error» de esa siguiente capa. Esto es cierto para todas las capas ocultas, ya que no calculamos un término de «error» para las entradas.
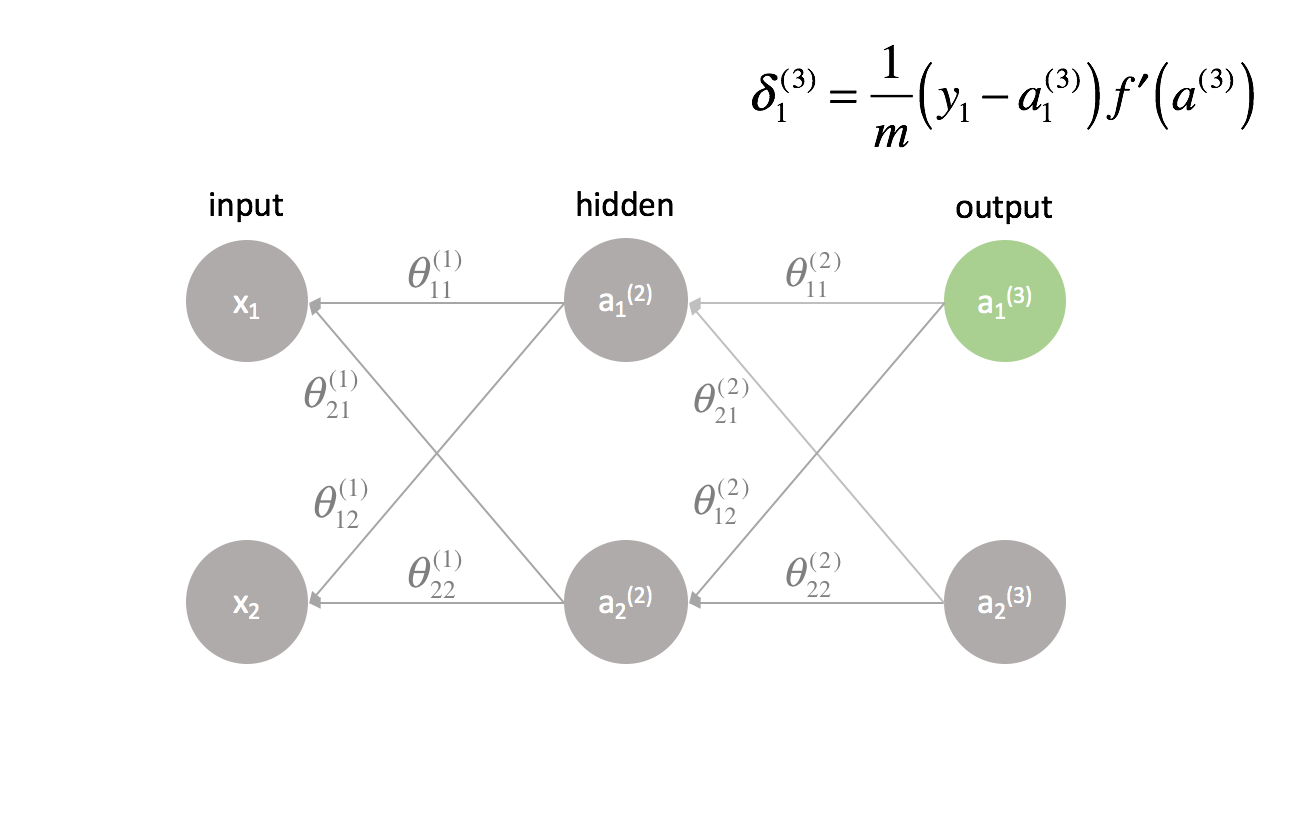
La última capa es un caso especial porque calculamos los valores $\delta$ comparando directamente cada neurona de salida con su salida esperada.
Un método formalizado para implementar la retropropagación
Aquí presentaré un método práctico para implementar la retropropagación a través de una red de capas $l=1,2,…,L$.
-
Realizar la propagación hacia delante.
-
Calcular el término $\delta$ para la capa de salida.
-
Calcular las derivadas parciales de la función de coste con respecto a todos los parámetros que alimentan la capa de salida, ${{Theta ^{(L – 1)}}$.
-
Regresar una capa.
$l = l – 1$ -
Calcular el término ${delta$} para la capa oculta actual.
-
Calcule las derivadas parciales de la función de coste con respecto a todos los parámetros que alimentan la capa actual.
-
Repita del 4 al 6 hasta llegar a la capa de entrada.
Revisando la inicialización de los pesos
Cuando empezamos, propuse que simplemente inicializáramos aleatoriamente nuestros pesos para tener un punto de partida. Esto nos permitió realizar la propagación hacia delante, comparar las salidas con los valores esperados y calcular el coste de nuestro modelo.
En realidad es muy importante que inicialicemos nuestros pesos con valores aleatorios para poder romper la simetría en nuestro modelo. Si hubiéramos inicializado todos nuestros pesos para que fueran iguales, cada neurona en la siguiente capa hacia adelante sería igual a la misma combinación lineal de valores.
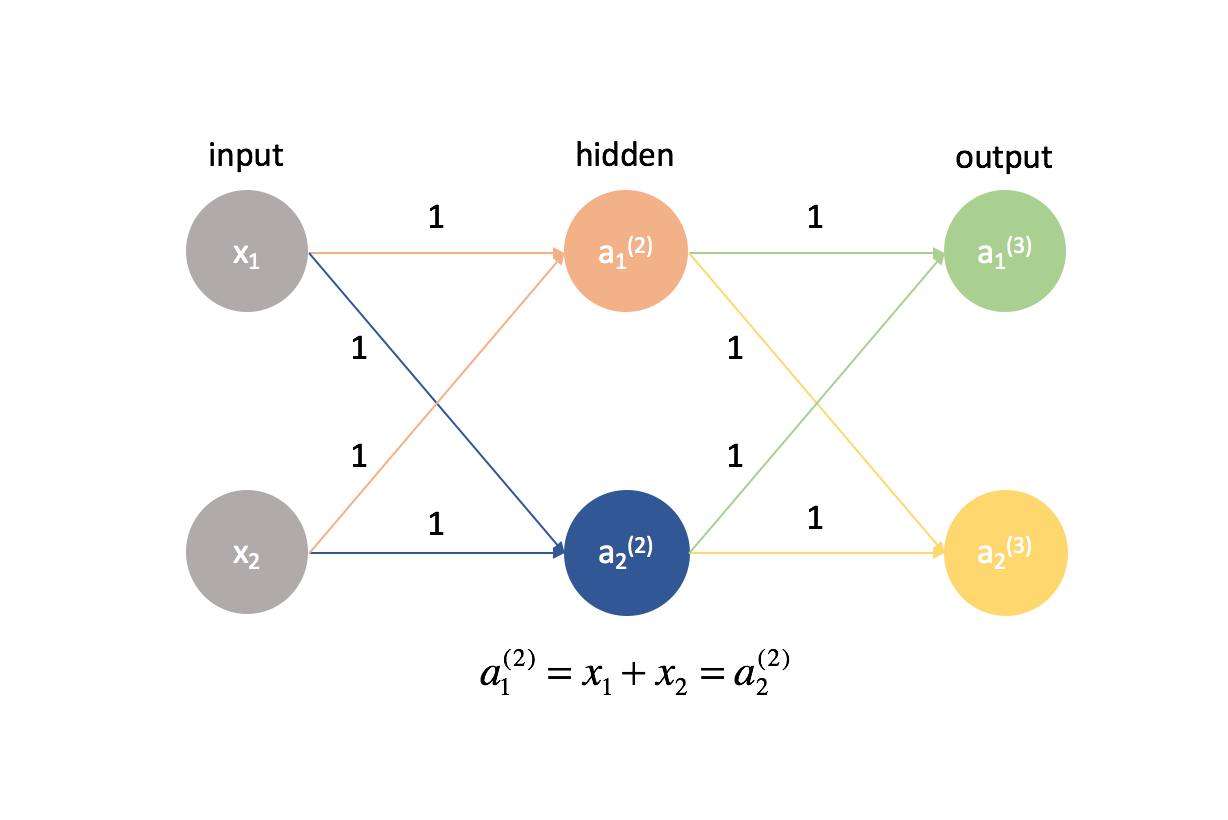
Por esta misma lógica, los valores $\delta$ también serían los mismos para cada neurona en una capa dada.
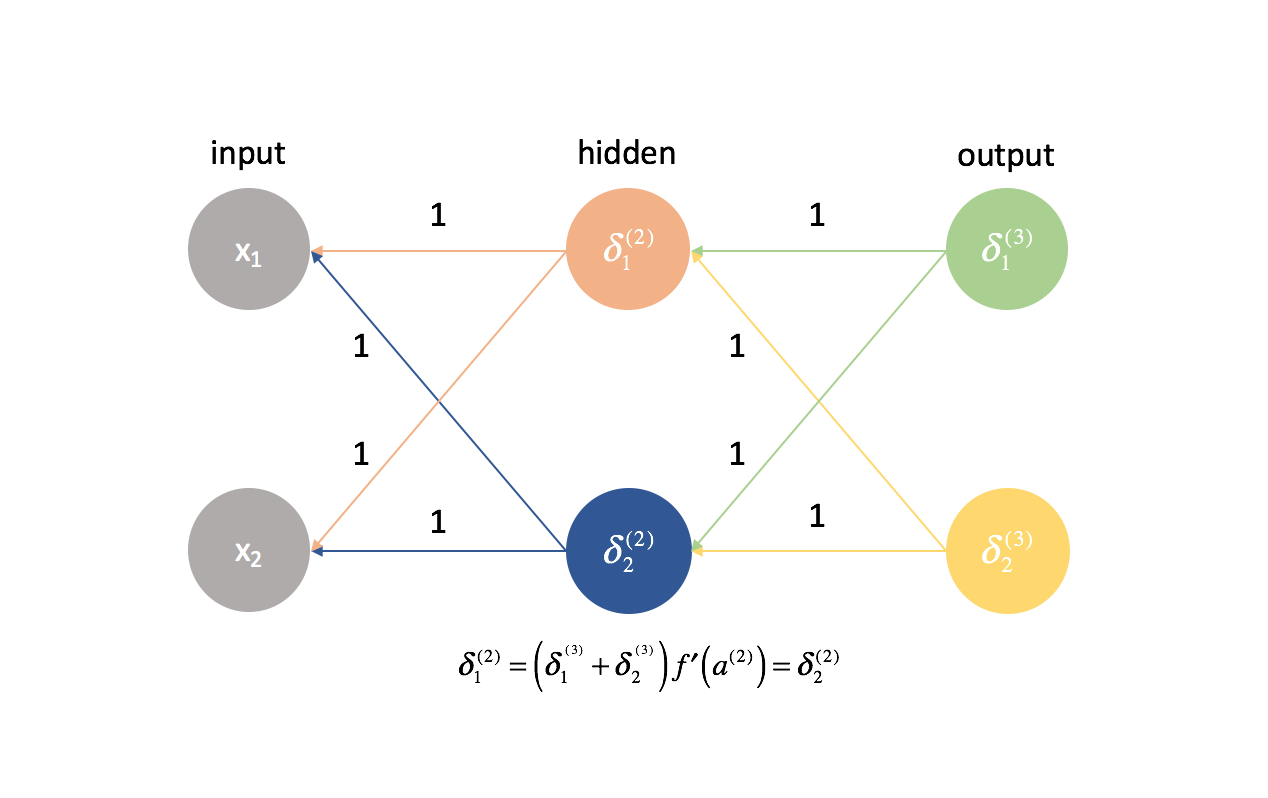
Además, debido a que calculamos las derivadas parciales en cualquier capa dada combinando los valores $\delta$ y las activaciones, todas las derivadas parciales en cualquier capa dada serían idénticas. Como tal, los pesos se actualizaría simétricamente en el descenso de gradiente y múltiples neuronas en cualquier capa sería inútil. Esto obviamente no sería una red neuronal muy útil.
Inicializar aleatoriamente los pesos de la red nos permite romper esta simetría y actualizar cada peso individualmente según su relación con la función de coste. Típicamente asignaremos a cada parámetro un valor aleatorio en $\left$ donde $\varepsilon$ es algún valor cercano a cero.
Poniéndolo todo junto
Después de haber calculado todas las derivadas parciales para los parámetros de la red neuronal, podemos utilizar el descenso de gradiente para actualizar los pesos.
En general, definimos el descenso de gradiente como
donde $\Delta {\theta _i}$ es el «paso» que damos caminando a lo largo del gradiente, escalado por una tasa de aprendizaje, $\eta$.
Usaremos esta fórmula para actualizar cada uno de los pesos, volver a calcular la propagación hacia adelante con los nuevos pesos, retropropagar el error, y calcular la siguiente actualización de pesos. Este proceso continúa hasta que hayamos convergido en un valor óptimo para nuestros parámetros.
Durante cada iteración realizamos la propagación hacia adelante para calcular las salidas y la propagación hacia atrás para calcular los errores; una iteración completa se conoce como una época. Es habitual informar de las métricas de evaluación después de cada epoch para que podamos observar la evolución de nuestra red neuronal a medida que se entrena.
Lectura adicional
-
El cálculo matricial que necesitas para el aprendizaje profundo
-
Cómo funciona el algoritmo de retropropagación
-
-
Stanford cs231n: Backpropagation, Intuiciones
-
CS231n Invierno 2016: Lecture 4: Backpropagation, Neural Networks 1
-
Lecciones sobre Deep Learning
-
Sí debes entender el backpropagation
-
Los bloques de construcción de las redes neuronales
-
Y por si acabas de abandonar el backpropagation…. Aprendizaje profundo sin retropropagación
-