De interesse in het leren van machine learning is omhoog geschoten in de jaren sinds Harvard Business Review artikel ‘Data Scientist’ de ‘Sexiest job of the 21st century’ noemde. Maar als je net begint met machine learning, kan het een beetje moeilijk zijn om in te breken. Daarom herstarten we onze immens populaire post over goede machine learning-algoritmen voor beginners.
(Deze post is oorspronkelijk gepubliceerd op KDNuggets als The 10 Algorithms Machine Learning Engineers Need to Know. Het is opnieuw geplaatst met toestemming, en is voor het laatst bijgewerkt in 2019).
Deze post is gericht op beginners. Als je al wat ervaring hebt met data science en machine learning, ben je misschien meer geïnteresseerd in deze meer diepgaande tutorial over machine learning in Python met scikit-learn, of in onze machine learning cursussen, die hier beginnen. Als de verschillen tussen “data science” en “machine learning” je nog niet duidelijk zijn, biedt dit artikel een goede uitleg: machine learning en data science – wat maakt ze verschillend?
Machine learning-algoritmen zijn programma’s die kunnen leren van data en verbeteren door ervaring, zonder menselijke tussenkomst. Leertaken kunnen bestaan uit het leren van de functie die de input in de output omzet, het leren van de verborgen structuur in ongelabelde data; of ‘instance-based learning’, waarbij een klassenlabel voor een nieuwe instantie wordt geproduceerd door de nieuwe instantie (rij) te vergelijken met instanties uit de trainingsdata, die in het geheugen waren opgeslagen. Bij ‘instance-based learning’ wordt geen abstractie gemaakt van specifieke instanties.
Typen Machine Learning Algoritmen
Er zijn 3 typen machine learning (ML) algoritmen:
Supervised Learning Algoritmen:
Supervised learning maakt gebruik van gelabelde trainingsgegevens om de mapping-functie te leren die invoervariabelen (X) omzet in de uitgangsvariabele (Y). Met andere woorden, het lost f op in de volgende vergelijking:
Dit stelt ons in staat om nauwkeurig outputs te genereren als we nieuwe inputs krijgen.
We zullen het hebben over twee soorten leren onder toezicht: classificatie en regressie.
Classificatie wordt gebruikt om de uitkomst van een gegeven steekproef te voorspellen wanneer de uitvoervariabele de vorm van categorieën heeft. Een classificatiemodel kijkt bijvoorbeeld naar de invoergegevens en probeert labels als “ziek” of “gezond” te voorspellen.
Regressie wordt gebruikt om de uitkomst van een gegeven steekproef te voorspellen wanneer de uitvoervariabele de vorm heeft van reële waarden. Een regressiemodel kan bijvoorbeeld invoergegevens verwerken om de hoeveelheid regen te voorspellen, de lengte van een persoon, enzovoort.
De eerste 5 algoritmen die we in deze blog behandelen – lineaire regressie, logistische regressie, CART, Naïve-Bayes en K-Nearest Neighbors (KNN) – zijn voorbeelden van supervised learning.
Ensembling is een andere vorm van supervised learning. Het is het combineren van de voorspellingen van meerdere machine-leermodellen die afzonderlijk zwak zijn om een nauwkeuriger voorspelling te doen over een nieuw monster. Algoritmen 9 en 10 van dit artikel – Bagging met Random Forests, Boosting met XGBoost – zijn voorbeelden van ensembletechnieken.
Unsupervised Learning Algorithms:
Unsupervised learning-modellen worden gebruikt wanneer we alleen de inputvariabelen (X) hebben en geen overeenkomstige outputvariabelen. Ze gebruiken ongelabelde trainingsgegevens om de onderliggende structuur van de gegevens te modelleren.
We zullen het hebben over drie soorten leren zonder toezicht:
Associatie wordt gebruikt om de waarschijnlijkheid te ontdekken van de co-aanwezigheid van items in een verzameling. Het wordt op grote schaal gebruikt bij de analyse van het marktsegment. Een associatiemodel kan bijvoorbeeld worden gebruikt om te ontdekken dat als een klant brood koopt, de kans 80% is dat hij/zij ook eieren koopt.
Clustering wordt gebruikt om monsters zodanig te groeperen dat objecten binnen dezelfde cluster meer op elkaar lijken dan op de objecten van een andere cluster.
Dimensionaliteitsreductie wordt gebruikt om het aantal variabelen van een gegevensverzameling te verminderen en er tegelijkertijd voor te zorgen dat belangrijke informatie nog steeds wordt overgebracht. Vermindering van de dimensie kan worden gedaan met behulp van Feature Extractie methoden en Feature Selectie methoden. Feature Selection selecteert een subset van de oorspronkelijke variabelen. Feature Extractie voert een gegevenstransformatie uit van een hoog-dimensionale ruimte naar een laag-dimensionale ruimte. Voorbeeld: PCA algoritme is een Feature Extraction aanpak.
Algoritmen 6-8 die we hier behandelen – Apriori, K-means, PCA – zijn voorbeelden van unsupervised learning.
Handhavingsleren:
Handhavingsleren is een type algoritme voor machinaal leren dat een agent in staat stelt de beste volgende actie te bepalen op basis van zijn huidige toestand door gedrag te leren dat een beloning maximaliseert.
Handhavingsalgoritmen leren gewoonlijk optimale acties door trial and error. Stel je bijvoorbeeld een videospel voor waarin de speler op bepaalde tijden naar bepaalde plaatsen moet gaan om punten te verdienen. Een versterkingsalgoritme dat dat spel speelt, zou beginnen met willekeurige bewegingen, maar na verloop van tijd zou het door vallen en opstaan leren waar en wanneer het spelpersonage moest bewegen om zijn puntentotaal te maximaliseren.
Quantifying the Popularity of Machine Learning Algorithms
Waar hebben we deze tien algoritmen vandaan? Een dergelijke lijst is van nature subjectief. Studies zoals deze hebben de 10 populairste datamining-algoritmen gekwantificeerd, maar ze zijn nog steeds gebaseerd op de subjectieve antwoorden van enquêterespondenten, meestal gevorderde academische beoefenaars. Bijvoorbeeld, in het hierboven gelinkte onderzoek waren de ondervraagden de winnaars van de ACM KDD Innovation Award, de IEEE ICDM Research Contributions Award; de Programma Comité leden van de KDD ’06, ICDM ’06, en SDM ’06; en de 145 aanwezigen van de ICDM ’06.
De top 10 algoritmen in deze post zijn gekozen met machine learning beginners in het achterhoofd. Het zijn vooral algoritmen die ik heb geleerd van de cursus ‘Data Warehousing and Mining’ (DWM) tijdens mijn Bachelor in Computer Engineering aan de Universiteit van Mumbai. Ik heb de laatste 2 algoritmen (ensemble methoden) vooral opgenomen omdat ze vaak worden gebruikt om Kaggle wedstrijden te winnen.
Met verdere omhaal, De Top 10 Machine Leren Algoritmen voor Beginners:
1. Lineaire regressie
In machine learning hebben we een reeks inputvariabelen (x) die worden gebruikt om een outputvariabele (y) te bepalen. Er bestaat een relatie tussen de inputvariabelen en de outputvariabele. Het doel van ML is om deze relatie te kwantificeren.

In lineaire regressie wordt het verband tussen de ingangsvariabelen (x) en de uitgangsvariabele (y) uitgedrukt als een vergelijking van de vorm y = a + bx. Het doel van lineaire regressie is dus de waarden van de coëfficiënten a en b te bepalen. Hierbij is a het intercept en b de helling van de lijn.
Figuur 1 toont de uitgezette x- en y-waarden voor een gegevensreeks. Het doel is een lijn te fitten die het dichtst bij de meeste punten ligt. Dit zou de afstand (‘fout’) tussen de y-waarde van een gegevenspunt en de lijn verkleinen.
2. Logistische regressie
Lineaire regressievoorspellingen zijn continue waarden (d.w.z. regenval in cm), logistische regressievoorspellingen zijn discrete waarden (d.w.z,
Logistische regressie is het meest geschikt voor binaire classificatie: gegevensverzamelingen waarbij y = 0 of 1, waarbij 1 staat voor de standaardklasse. Bijvoorbeeld, bij het voorspellen of een gebeurtenis al dan niet zal plaatsvinden, zijn er slechts twee mogelijkheden: dat de gebeurtenis plaatsvindt (wat wij aanduiden met 1) of dat deze niet plaatsvindt (0). Dus als we voorspellen of een patiënt ziek is, labelen we zieke patiënten met de waarde 1 in onze dataset.
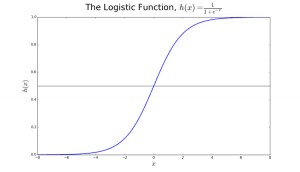
Logistische regressie is vernoemd naar de transformatiefunctie die wordt gebruikt, die de logistische functie h(x)= 1/ (1 + ex) wordt genoemd. Deze vormt een S-vormige curve.
In logistische regressie heeft de output de vorm van waarschijnlijkheden van de standaardklasse (in tegenstelling tot lineaire regressie, waarbij de output direct wordt geproduceerd). Omdat het een waarschijnlijkheid is, ligt de output in het bereik van 0-1. Als we bijvoorbeeld proberen te voorspellen of patiënten ziek zijn, weten we al dat zieke patiënten worden aangeduid met 1, dus als ons algoritme een score van 0,98 aan een patiënt toekent, is de kans groot dat die patiënt ziek is.
Deze output (y-waarde) wordt gegenereerd door logische transformatie van de x-waarde, met behulp van de logistische functie h(x)= 1/ (1 + e^ -x) . Vervolgens wordt een drempelwaarde toegepast om deze waarschijnlijkheid in een binaire classificatie te dwingen.
Figuur 2: Logistische regressie om te bepalen of een tumor kwaadaardig of goedaardig is. Geclassificeerd als kwaadaardig als de waarschijnlijkheid h(x)>= 0,5. Bron
In figuur 2, om te bepalen of een tumor kwaadaardig is of niet, is de standaardvariabele y = 1 (tumor = kwaadaardig). De x variabele kan een meting van de tumor zijn, zoals de grootte van de tumor. Zoals in de figuur te zien is, transformeert de logistische functie de x-waarde van de verschillende instanties van de dataset, in het bereik van 0 tot 1. Als de waarschijnlijkheid de drempel van 0,5 overschrijdt (aangegeven door de horizontale lijn), wordt de tumor als kwaadaardig geclassificeerd.
De logistische regressievergelijking P(x) = e ^ (b0 + b1x) / (1 + e(b0 + b1x)) kan worden omgezet in ln(p(x) / 1-p(x)) = b0 + b1x.
Het doel van logistische regressie is om met behulp van de trainingsgegevens de waarden van de coëfficiënten b0 en b1 zo te vinden dat de fout tussen de voorspelde uitkomst en de werkelijke uitkomst zo klein mogelijk is. Deze coëfficiënten worden geschat met behulp van de techniek van Maximum Likelihood Estimation.
3. CART
Classificatie- en Regressiebomen (CART) zijn een implementatie van Beslisbomen.
De niet-terminale knooppunten van Classificatie- en Regressiebomen zijn de wortelknooppunt en de interne knooppunt. De eindknopen zijn de bladknopen. Elke niet-terminale knoop vertegenwoordigt een enkele invoervariabele (x) en een splitsingspunt op die variabele; de bladknopen vertegenwoordigen de uitgangsvariabele (y). Het model wordt als volgt gebruikt om voorspellingen te doen: loop de splitsingen van de boom om bij een bladknooppunt uit te komen en voer de waarde uit die bij het bladknooppunt aanwezig is.
De beslisboom in figuur 3 hieronder classificeert of een persoon een sportauto of een minibusje zal kopen, afhankelijk van zijn leeftijd en burgerlijke staat. Als de persoon ouder is dan 30 jaar en niet getrouwd is, doorlopen we de boom als volgt: “ouder dan 30 jaar?” -> ja -> “getrouwd?” -> nee. Het model levert dus een sportauto.
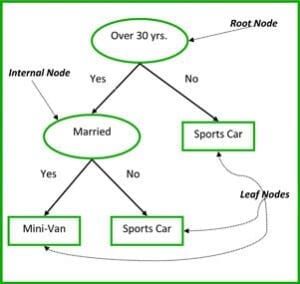
Figuur 3: Onderdelen van een beslisboom. Bron
4. Naïeve Bayes
Om de kans te berekenen dat een gebeurtenis zich voordoet, gegeven dat een andere gebeurtenis zich al heeft voorgedaan, gebruiken we de Stelling van Bayes. Om de kans te berekenen dat hypothese(h) waar is, gegeven onze voorkennis(d), gebruiken we de Stelling van Bayes als volgt:
waar:
- P(h|d) = Posterieure waarschijnlijkheid. De waarschijnlijkheid dat hypothese h waar is, gegeven de gegevens d, waarbij P(h|d)= P(d1| h) P(d2| h)….P(dn| h) P(d)
- P(d|h) = Waarschijnlijkheid. De waarschijnlijkheid van gegevens d gegeven dat de hypothese h waar was.
- P(h) = Klassieke voorafgaande waarschijnlijkheid. De waarschijnlijkheid dat hypothese h waar is (ongeacht de gegevens)
- P(d) = Predictor prior probability. De kans dat de gegevens waar zijn (ongeacht de hypothese)
Dit algoritme wordt ‘naïef’ genoemd omdat het aanneemt dat alle variabelen onafhankelijk van elkaar zijn, wat een naïeve aanname is om te doen in voorbeelden uit de echte wereld.
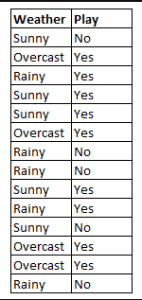
Figuur 4: Naive Bayes gebruiken om de status van ‘spelen’ te voorspellen met behulp van de variabele ‘weer’.
Met figuur 4 als voorbeeld, wat is de uitkomst als het weer = ‘zonnig’?
Om de uitkomst spel = ‘ja’ of ‘nee’ te bepalen gegeven de waarde van variabele weer = ‘zonnig’, berekent u P(ja|zonnig) en P(nee|zonnig) en kiest u de uitkomst met een hogere waarschijnlijkheid.
->P(ja|zonnig)= (P(zonnig|ja) * P(ja)) / P(zonnig) = (3/9 * 9/14 ) / (5/14) = 0.60
-> P(nee|zonnig)= (P(zonnig|geen) * P(nee)) / P(zonnig) = (2/5 * 5/14 ) / (5/14) = 0.40
Dus, als het weer = ‘zonnig’, dan is de uitkomst spel = ‘ja’.
5. KNN
Het K-Nearest Neighbors-algoritme gebruikt de hele dataset als trainingsset, in plaats van de dataset op te splitsen in een trainingsset en testset.
Wanneer een uitkomst nodig is voor een nieuwe data-instantie, gaat het KNN-algoritme door de hele dataset om de k-nabijste instanties te vinden voor de nieuwe instantie, of het k-aantal instanties dat het meest op de nieuwe record lijkt, en geeft dan het gemiddelde van de uitkomsten (voor een regressieprobleem) of de modus (meest frequente klasse) voor een classificatieprobleem. De waarde van k wordt door de gebruiker gespecificeerd.
De overeenkomst tussen instanties wordt berekend met behulp van maten als Euclidische afstand en Hamming-afstand.
Onbeheerd leren algoritmen
6. Apriori
Het Apriori algoritme wordt gebruikt in een transactionele database om frequente itemverzamelingen te ontginnen en vervolgens associatieregels te genereren. Het wordt populair gebruikt in de marktmand analyse, waar men controleert op combinaties van producten die vaak samen voorkomen in de database. In het algemeen schrijven we de associatieregel voor “als een persoon item X koopt, dan koopt hij item Y” als : X -> Y.
Voorbeeld: als een persoon melk en suiker koopt, dan is de kans groot dat zij ook koffiepoeder koopt. Dit kan in de vorm van een associatieregel worden geschreven als: {melk,suiker} -> koffiepoeder. Associatieregels worden gegenereerd na het overschrijden van de drempel voor steun en vertrouwen.

Figuur 5: Formules voor steun, vertrouwen en lift voor de associatieregel X->Y.
De ondersteuningsmaatstaf helpt bij het snoeien van het aantal kandidaat-itemsets dat in aanmerking moet worden genomen tijdens het genereren van frequente itemsets. Deze ondersteuningsmaatstaf wordt geleid door het Apriori principe. Het Apriori principe stelt dat als een itemset frequent is, alle subsets ervan ook frequent moeten zijn.
7. K-means
K-means is een iteratief algoritme dat gelijksoortige gegevens in clusters groepeert.Het berekent de centroïden van k clusters en wijst een gegevenspunt toe aan de cluster met de kleinste afstand tussen zijn centroïde en het gegevenspunt.

Figuur 6: Stappen van het K-means algoritme. Bron
Hier ziet u hoe het werkt:
We beginnen met het kiezen van een waarde van k. Laten we hier zeggen dat k = 3. Vervolgens wijzen we elk gegevenspunt willekeurig toe aan een van de 3 clusters. Bereken het clustercentrum voor elk van de clusters. De rode, blauwe en groene sterren geven de centroïden voor elk van de 3 clusters aan.
Daarna wordt elk punt opnieuw toegewezen aan het dichtstbijzijnde cluster-centroïde. In de figuur hierboven zijn de bovenste 5 punten toegewezen aan het cluster met het blauwe zwaartepunt. Volg dezelfde procedure om punten toe te wijzen aan de clusters met de rode en groene centroïden.
Bereken vervolgens de centroïden voor de nieuwe clusters. De oude centroïden zijn grijze sterren; de nieuwe centroïden zijn de rode, groene en blauwe sterren.
Daarna herhaalt u stap 2-3 tot er geen punten meer van het ene naar het andere cluster overgaan.
8. PCA
Principal Component Analysis (PCA) wordt gebruikt om gegevens gemakkelijk te onderzoeken en te visualiseren door het aantal variabelen te verminderen. Dit wordt gedaan door de maximale variantie in de gegevens vast te leggen in een nieuw coördinatenstelsel met assen die ‘hoofdcomponenten’ worden genoemd.
Elke component is een lineaire combinatie van de oorspronkelijke variabelen en is orthogonaal ten opzichte van elkaar. Orthogonaliteit tussen componenten geeft aan dat de correlatie tussen deze componenten nul is.
De eerste hoofdcomponent vangt de richting van de maximale variabiliteit in de gegevens. De tweede hoofdcomponent vangt de resterende variantie in de gegevens, maar heeft variabelen die niet met de eerste component gecorreleerd zijn. Op dezelfde manier vangen alle opeenvolgende hoofdcomponenten (PC3, PC4 enzovoort) de resterende variantie, terwijl ze niet gecorreleerd zijn met de vorige component.
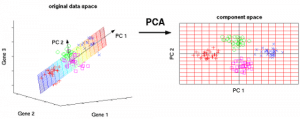
Figuur 7: De 3 oorspronkelijke variabelen (genen) worden gereduceerd tot 2 nieuwe variabelen die hoofdcomponenten (PC’s) worden genoemd. Bron
Ensemble leertechnieken:
Ensembling betekent het combineren van de resultaten van meerdere leerders (classifiers) voor betere resultaten, door te stemmen of te middelen. Stemmen wordt gebruikt bij classificatie en gemiddelden worden gebruikt bij regressie. Het idee is dat ensembles van learners beter presteren dan individuele learners.
Er zijn 3 soorten ensembling algoritmen: Bagging, Boosting en Stacking. We gaan hier niet in op ‘stacking’, maar als je er een uitgebreide uitleg over wilt, is hier een goede introductie van Kaggle.
9. Bagging met Random Forests
De eerste stap bij bagging is het maken van meerdere modellen met datasets die zijn gemaakt met de Bootstrap Sampling-methode. Bij Bootstrap Sampling wordt elke gegenereerde trainingsset samengesteld uit willekeurige deelmonsters van de oorspronkelijke dataset.
Elke van deze trainingssets is even groot als de oorspronkelijke dataset, maar sommige records komen meerdere keren voor en sommige records helemaal niet. Vervolgens wordt de volledige oorspronkelijke gegevensverzameling gebruikt als de testverzameling. Als de omvang van de oorspronkelijke gegevensverzameling dus N is, dan is de omvang van elke gegenereerde trainingsverzameling ook N, waarbij het aantal unieke records ongeveer (2N/3) is; de omvang van de testverzameling is ook N.
De tweede stap in bagging is het maken van meerdere modellen door hetzelfde algoritme te gebruiken op de verschillende gegenereerde trainingsverzamelingen.
Dit is waar Random Forests in het spel komen. In tegenstelling tot een beslisboom, waar elk knooppunt wordt gesplitst op het beste kenmerk dat de fout minimaliseert, kiezen we in Random Forests een willekeurige selectie van kenmerken voor het construeren van de beste splitsing. De reden voor de willekeurigheid is: zelfs met bagging, wanneer beslisbomen de beste eigenschap kiezen om op te splitsen, eindigen ze met een gelijkaardige structuur en gecorreleerde voorspellingen. Maar bagging na splitsing op een willekeurige subset van kenmerken betekent minder correlatie tussen voorspellingen van subtrees.
Het aantal kenmerken dat op elk splitsingspunt moet worden doorzocht, wordt gespecificeerd als een parameter voor het Random Forest algoritme.
Dus, in bagging met Random Forest, wordt elke boom geconstrueerd met behulp van een willekeurige steekproef van records en wordt elke splitsing geconstrueerd met behulp van een willekeurige steekproef van voorspellers.
10. Boosting met AdaBoost
Adaboost staat voor Adaptive Boosting. Bagging is een parallel ensemble omdat elk model onafhankelijk wordt gebouwd. Aan de andere kant is boosting een sequentieel ensemble waarbij elk model wordt gebouwd op basis van het corrigeren van de misclassificaties van het vorige model.
Bagging impliceert meestal ‘simple voting’, waarbij elke classificeerder stemt om een eindresultaat te verkrijgen – een resultaat dat wordt bepaald door de meerderheid van de parallelle modellen; boosting impliceert ‘weighted voting’, waarbij elke classificeerder stemt om een eindresultaat te verkrijgen dat wordt bepaald door de meerderheid – maar de sequentiële modellen zijn gebouwd door grotere gewichten toe te kennen aan verkeerd geclassificeerde instanties van de vorige modellen.
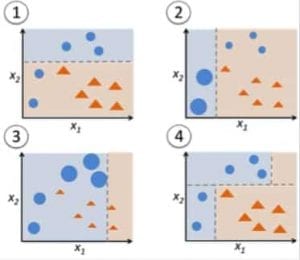
Figuur 9: Adaboost voor een beslisboom. Bron
In figuur 9, stappen 1, 2, 3 betrekken een zwakke lerende genaamd een beslissingsstomp (een beslissingsboom van 1 niveau die een voorspelling doet op basis van de waarde van slechts 1 inputkenmerk; een beslissingsboom met zijn wortel onmiddellijk verbonden met zijn bladeren).
Het proces van het construeren van zwakke lerende bomen gaat door totdat een door de gebruiker gedefinieerd aantal zwakke lerende bomen is geconstrueerd of totdat er geen verbetering meer optreedt tijdens de training. Stap 4 combineert de 3 beslissingsstumps van de vorige modellen (en heeft dus 3 splitsingsregels in de beslissingsboom).
Eerst beginnen we met één beslissingsboomstump om een beslissing te nemen over één invoervariabele.
De grootte van de datapunten laten zien dat we gelijke gewichten hebben toegepast om ze te classificeren als een cirkel of driehoek. De beslissingsstomp heeft in de bovenste helft een horizontale lijn gegenereerd om deze punten te classificeren. We kunnen zien dat er twee cirkels ten onrechte als driehoeken zijn voorspeld. Daarom kennen we aan deze twee cirkels hogere gewichten toe en passen we een andere beslissingsstomp toe.
Ten tweede gaan we naar een andere beslissingsstomp om een beslissing te nemen over een andere ingangsvariabele.
We zien dat de grootte van de twee verkeerd geclassificeerde cirkels uit de vorige stap groter is dan de overige punten. De tweede beslisboom zal nu proberen deze twee cirkels correct te voorspellen.
Als gevolg van het toekennen van hogere gewichten zijn deze twee cirkels correct geclassificeerd door de verticale lijn aan de linkerkant. Maar dit heeft nu geleid tot een verkeerde classificatie van de drie cirkels aan de bovenkant. Daarom kennen we hogere gewichten toe aan deze drie cirkels bovenaan en passen we een andere beslissingsboomstomp toe.
Ter derde trainen we een andere beslissingsboomstomp om een beslissing te nemen over een andere ingangsvariabele.
De drie verkeerd geclassificeerde cirkels uit de vorige stap zijn groter dan de rest van de datapunten. Nu is een verticale lijn naar rechts gegenereerd om de cirkels en driehoeken te classificeren.
Vierde, combineer de beslissingsboomstomps.
We hebben de scheiders van de 3 vorige modellen gecombineerd en constateren dat de complexe regel van dit model de gegevenspunten correct classificeert in vergelijking met elk van de afzonderlijke zwakke lerenden.
Conclusie:
Om samen te vatten, hebben we enkele van de belangrijkste machine-learning-algoritmen voor data science behandeld:
- 5 technieken voor leren onder toezicht- Lineaire regressie, Logistische regressie, CART, Naïve Bayes, KNN.
- 3 technieken voor leren zonder toezicht- Apriori, K-means, PCA.
- 2 ensembling-technieken- Bagging met Random Forests, Boosting met XGBoost.
Opmerking van de redacteur: Dit is oorspronkelijk geplaatst op KDNuggets, en is met toestemming opnieuw geplaatst. Auteur Reena Shaw is ontwikkelaar en journalist op het gebied van data science.

Reena Shaw is een liefhebber van alles wat met data, pittig eten en Alfred Hitchcock te maken heeft. Neem contact met haar op via de links in de ‘Lees meer’-knop aan de rechterkant: Linkedin| |@ReenaShawLegacy