Een veel voorkomende vraag die ik zie van veel mensen die nieuw zijn met T-SQL is hoe je gegevens in een string kunt vinden en deze kunt extraheren. Dit is een veel voorkomende vraag, omdat onze databases veel strings bevatten. We merken vaak dat mensen die applicaties gebruiken informatie in een string insluiten, met de verwachting dat het programma die informatie later gemakkelijk zal kunnen verwijderen. In dit artikel zal ik bekijken hoe je deze gegevens kunt extraheren met SUBSTRING, CHARINDEX, en PATINDEX.
Dit is een terug naar de basis artikel waarvan ik hoop dat het nuttig is voor die ontwikkelaars en DBA’s die nieuw zijn in SQL Server en die hun vaardigheden willen verbeteren. Voel je vrij om dit door te geven.
Vind de Consistente PO
Een voorbeeld is een factuurnummer of PO nummer. Ik heb vaak gezien dat deze gegevens zijn opgenomen in tekstvelden, met een eis om later dit nummer uit het veld te halen. Dit is een veel voorkomend type gegevens dat wordt toegevoegd aan een veld in een tabel ergens, zoals in een klantentabel. Gebruikers, of een applicatie, kunnen besluiten deze gegevens toe te voegen om onze gegevens te denormaliseren.
Voorstel dat we een tabel hebben die informatie bevat zoals deze:
CREATE TABLE Customers( CustomerID INT, CustomerName VARCHAR(500), CustomerNotes VARCHAR(MAX), Active TINYINT);GOINSERT dbo.Customers ( CustomerID , CustomerName , CustomerNotes , Active ) VALUES ( 1, 'Acme Inc', 'Last PO:20154402', 1) , ( 2, 'Roadrunner Enterprises', 'Last PO:20140322', 1 ) , ( 3, 'Wile E. Coyote and Sons', 'Unreliable payments', 0)
Als ik naar de gegevens kijk, zien we dat iemand heeft besloten belangrijke informatie in het notitieveld op te nemen. Ik weet zeker dat veel ervaren mensen ineenkrimpen bij dit gebruik van velden in een tabel, maar dit gebeurt vaker dan velen van ons zouden willen.
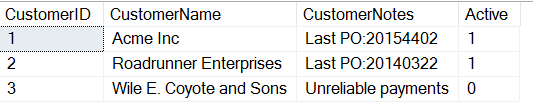
Als ik nu de PO uit dit veld wil halen, misschien voor een rapport dat nodig is, of misschien omdat ik deze gegevens ga ETL-en naar een geschiktere plaats, kan ik de SUBSTRING-functie in T-SQL gebruiken. Ik gebruik deze functie wanneer ik weet waar in een string ik gegevens wil ophalen.
In dit geval kan ik zien dat de eerste 8 tekens van het veld CustomerNotes vaak “Last PO:” zijn. Hiermee kan ik bij het 9e teken beginnen en dan de volgende 8 tekens (lengte van de PO) krijgen. Ik gebruik dan deze query.
SELECT CustomerID , 'PO' = SUBSTRING(CustomerNotes, 9, 8)FROM dbo.Customers
Dit levert de PO’s op, maar ik krijg nog wat andere gegevens.
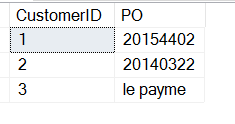
Geen zorgen, dit kan ik er makkelijk uitfilteren (een discussie voor een ander artikel).
SELECT CustomerID , 'PO' = SUBSTRING(CustomerNotes, 9, 8)FROM dbo.Customers WHERE customerNotes LIKE '%PO%'
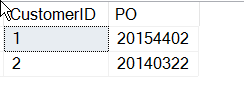
Nu ben ik klaar, toch? Nou, misschien ook niet.
Een inconsistente PO
In de gegevens die ik tot nu toe heb bekeken, staat het PO-nummer altijd op de juiste plaats. Maar laten we eens aannemen dat niet al onze data entry mensen op dezelfde manier met klanten werken. Hier nog wat meer gegevens om te laten zien wat ik bedoel:
INSERT dbo.Customers ( CustomerID , CustomerName , CustomerNotes , Active ) VALUES ( 4, 'Beep Beep Enterprises', 'Remember their slogan: We go fast. Last PO:20154402', 1) , ( 5, 'Goldberg Supplies', 'Preferred. Last PO:20140322', 1 ) , ( 6, 'Bugs Deliveries', 'Fast Last PO:20145554', 0)
Nu laten we ons script van hierboven uitvoeren. We krijgen deze gegevens:
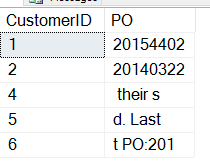
Niet helemaal wat we willen. Het probleem hier is dat het begin van de SUBSTRING niet is wat we willen. We moeten beginnen met de locatie van het PO-nummer, misschien met de locatie van “PO:”. Hoe krijgen we dat voor elkaar?
We hebben een paar keuzes, maar voeren CHARINDEX en PATINDEX in. Met beide kunnen we een tekenreeks doorzoeken en daarbinnen een andere tekenreeks vinden. Beide kunnen hier werken, maar ik zal je laten zien hoe ze werken op onze testgegevens. Ik voer deze query uit:
SELECT CustomerID , CustomerNotes , 'Charindex_StartPO' = CHARINDEX('PO:', CustomerNotes) , 'Patindex_StartPO' = PATINDEX('%PO:%', CustomerNotes) , 'PO' = SUBSTRING(CustomerNotes, 9, 8) FROM dbo.Customers
En krijg deze resultaten:
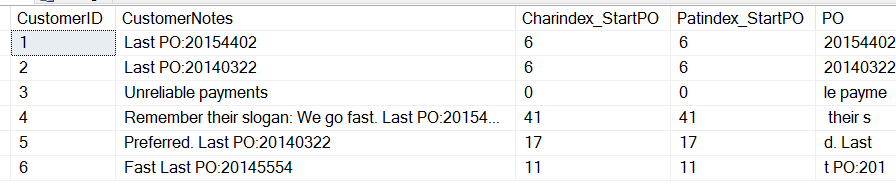
Merk op dat we hier kunnen zien dat beide functies dezelfde waarde teruggeven, de beginpositie van de “P” in “PO”. Er zijn een paar verschillen. CHARINDEX kan op een bepaalde positie in de tekenreeks beginnen, terwijl PATINDEX jokertekens kan gebruiken. In dit simplistische geval kunnen we beide gebruiken.
Ik gebruik hier CHARINDEX, en verander mijn query in dit:
SELECT CustomerID , 'PO' = SUBSTRING(CustomerNotes, CHARINDEX('PO:', CustomerNotes), 8) FROM dbo.Customers WHERE customerNotes LIKE '%PO%';
Dat geeft me dit, en dat is niet wat ik wil.
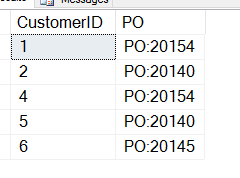
Ik ben vergeten dat CHARINDEX me de beginpositie van de PO geeft, dus ik moet bij deze waarde optellen. Hier is een query die werkt:
SELECT CustomerID , 'PO' = SUBSTRING(CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3, 8) FROM dbo.Customers WHERE customerNotes LIKE '%PO%';
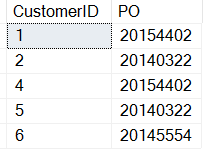
Merk op dat ik 3 heb toegevoegd aan het resultaat van de CHARINDEX-functie. Dit zijn de resultaten:
De inkooporder groeit
Het lijkt erop dat dit een goede query is, maar laten we ons eens voorstellen dat we wat meer gegevens toevoegen.
Merk op dat we in dit geval inkooporders hebben die in omvang zijn gegroeid. Sommige zijn 8 karakters, en sommige zijn 9. Natuurlijk kunnen we gewoon 9 karakters nemen, maar we zouden kunnen groeien tot 10 of meer. Bovendien hebben we andere notities na de PO op plaatsen.
Laten we onze query eens aanpassen om te zien wat we kunnen doen. Ik heb een draai aan mijn CHARINDEX gegeven.
SELECT CustomerID , CustomerNotes , 'Start of PO' = CHARINDEX('PO:', CustomerNotes)+3 , 'End of PO' = CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) , 'PO' = SUBSTRING(CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3, 8) FROM dbo.Customers WHERE customerNotes LIKE '%PO%';
Hier zijn de resultaten:
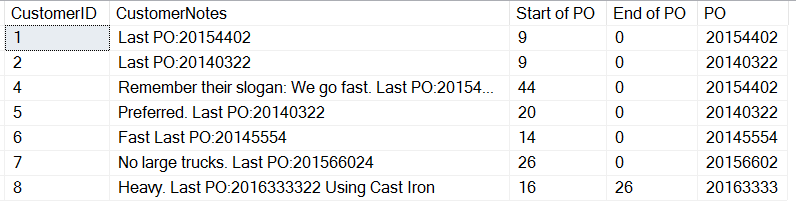
Als we goed kijken, zien we dat onze laatste invoer, met tekst na de PO ons een CHARINDEX-resultaat geeft. Dit komt omdat we naar een tekenreeks zoeken, we krijgen een 0 als er geen invoer wordt gevonden. Alleen klant 8 heeft een spatie na de PO. Dit betekent dat we de lengte van de PO voor de laatste vermelding kunnen berekenen, maar hoe zit het met alle andere vermeldingen die een ander formaat hebben?
We kunnen hier een CASE statement gebruiken, omdat we hier twee mogelijkheden hebben. De ene CASE controleert op spaties en geeft de index van de spatie in de string. De andere geeft de lengte van de string zelf terug, als er geen spatie is. Dit geeft me code zoals deze:
Update: Mijn wiskunde was onjuist. Veranderd van -3, in -2 in de code hieronder.
SELECT CustomerID , CustomerNotes , 'Start of PO' = CHARINDEX('PO:', CustomerNotes)+3 , 'End of PO' = CASE WHEN CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) = 0 THEN LEN(CustomerNotes) ELSE CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) END , 'Real End of PO' = CASE WHEN CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) = 0 THEN LEN(customernotes) ELSE CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) END - CHARINDEX('PO:', CustomerNotes) , 'PO' = SUBSTRING(CustomerNotes , CHARINDEX('PO:', CustomerNotes)+3 , CASE WHEN CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) = 0 THEN LEN(customernotes) ELSE CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) END - CHARINDEX('PO:', CustomerNotes) - 2 ) FROM dbo.Customers WHERE customerNotes LIKE '%PO%';
Als we naar deze code kijken, lijkt het erg op de SUBSTRING code die we eerder gebruikten, maar nu in plaats van een vaste lengte, 8, voor het aantal tekens dat teruggegeven moet worden, geven we waarden terug met een formule. De formule is in wezen het echte einde van de PO (de 5e kolom in de resultatenset) en het begin van de PO. Er is een CASE statement voor wanneer we een nul krijgen.
Nu, als we gaan rekenen, kunnen we zien hoe lang elke PO is. Voor de meeste PO’s is dit 8 karakters (11 karakters na het begin van de “P” in “PO:”), maar 9 karakters voor klant 7 en 11 voor klant 8.
Sommigen van u vragen zich misschien af over de -3 in de code, maar als u zich de rekenregels herinnert, heb ik in feite de min doorgetrokken naar het aantal dat het begin van het PO-nummer vertegenwoordigt.
Conclusie
Dit is niet het einde van de mogelijkheden voor PO’s die zijn ingebed in het a-notities veld. Ik zou iets kunnen hebben als “test PO: 201530444. Nieuwe test” en dat zou problemen opleveren met onze code. In feite zijn er genoeg andere gevallen die ik in de echte wereld zou moeten afhandelen.
Dit artikel kwam voort uit een paar string extractie problemen die ik in de echte wereld heb moeten oplossen, en dit soort problemen komen voor. Hopelijk heb ik je wat vaardigheden gegeven om te oefenen die je zullen helpen bij je SQL Server string manipulatie.
Zoals met alle technieken die je hier leert, moet je de gevolgen voor de prestaties goed inschatten. Voer uw code uit met een grote set testgegevens en bepaal hoe goed deze techniek werkt in vergelijking met andere technieken. Ik raad u aan een tabel te gebruiken om gegevens te genereren op een schaal die groter is dan uw productietabellen.
Het manipuleren van strings kan in SQL Server rekenintensief zijn, dus zorg ervoor dat u de gevolgen van uw keuzes begrijpt voordat u de code inzet in een productiesysteem.