Snelheid van websites is een prioriteit voor bedrijven in 2020.
Snellere websites scoren hoger bij zoekmachines en bieden ook een betere gebruikerservaring, wat resulteert in hogere conversiepercentages. Geen wonder dat website-eigenaren snellere laadsnelheden eisen en het aan de ontwikkelaars overlaten om dit te realiseren.
Database-optimalisatie is een essentiële stap om de prestaties van websites te verbeteren. Doorgaans normaliseren ontwikkelaars een relationele database, wat betekent dat ze deze herstructureren om de redundantie van gegevens te verminderen en de gegevensintegriteit te verbeteren. Soms is het normaliseren van een database echter niet genoeg, dus om de prestaties van een database nog verder te verbeteren gaan ontwikkelaars de andere kant op en nemen ze hun toevlucht tot database denormalisatie.
In dit artikel nemen we een kijkje bij denormalisatie om uit te vinden wanneer deze methode geschikt is en hoe u het kunt doen.
Wanneer een database denormaliseren
Wat is database denormalisatie? Laten we, voordat we in het onderwerp duiken, benadrukken dat normalisatie nog steeds het uitgangspunt is, wat betekent dat je allereerst de structuur van een database moet normaliseren. De essentie van normalisatie is om elk stukje gegevens op de juiste plaats te zetten; dit verzekert de integriteit van de gegevens en vergemakkelijkt het updaten. Het opvragen van gegevens uit een genormaliseerde database kan echter trager zijn, omdat query’s veel verschillende tabellen moeten aanspreken waarin verschillende gegevens zijn opgeslagen. Updaten gaat juist sneller, omdat alle gegevens op één plaats zijn opgeslagen.
De meeste moderne toepassingen moeten gegevens in zo kort mogelijke tijd kunnen ophalen. En dat is het moment waarop je kunt overwegen om een relationele database te denormaliseren. Zoals de naam al zegt, is denormalisatie het tegenovergestelde van normalisatie. Wanneer u een database normaliseert, organiseert u gegevens om de integriteit te waarborgen en redundanties te elimineren. Database denormalisatie betekent dat je opzettelijk dezelfde gegevens op verschillende plaatsen zet, waardoor de redundantie toeneemt.
“Waarom zou je een database überhaupt denormaliseren?” zul je je misschien afvragen. Het belangrijkste doel van denormalisatie is om het terugvinden van gegevens aanzienlijk te versnellen. Denormalisatie is echter geen tovermiddel. Ontwikkelaars moeten deze tool alleen voor bepaalde doeleinden gebruiken:
# 1 Om de query-prestaties te verbeteren
Typisch gezien moeten in een genormaliseerde database veel tabellen worden samengevoegd om query’s op te halen; maar hoe meer samenvoegingen, hoe langzamer de query. Als tegenmaatregel kun je redundantie toevoegen aan een database door waarden te kopiëren tussen ouder- en kind-tabellen en zo het aantal joins dat nodig is voor een query te verminderen.
#2 Een database handiger maken om te beheren
Een genormaliseerde database bevat geen berekende waarden die essentieel zijn voor applicaties. Het berekenen van deze waarden on-the-fly zou tijd kosten en de uitvoering van query’s vertragen.
U kunt een database denormaliseren om berekende waarden te bieden. Zodra deze zijn gegenereerd en aan tabellen zijn toegevoegd, kunnen downstream programmeurs eenvoudig hun eigen rapporten en query’s maken zonder diepgaande kennis van de code of API van de app.
#3 Rapportage vergemakkelijken en versnellen
Vaak moeten applicaties veel analytische en statistische informatie leveren. Het genereren van rapporten uit live gegevens is tijdrovend en kan de algehele systeemprestaties negatief beïnvloeden.
Denormalisatie van uw database kan u helpen deze uitdaging aan te gaan. Stel dat u voor een of meer gebruikers een totaal verkoopoverzicht wilt verstrekken; in een genormaliseerde database worden alle factuurgegevens samengevoegd en meerdere malen berekend. Om dit proces te versnellen, kunt u het verkoopoverzicht per jaar bijhouden in een tabel met gebruikersgegevens.
Database denormalisatie technieken
Nu u weet wanneer u moet overgaan tot database denormalisatie, vraagt u zich waarschijnlijk af hoe u dit goed kunt doen. Er zijn verschillende denormalisatie technieken, elk geschikt voor een bepaalde situatie. Laten we ze eens uitdiepen:
Het opslaan van afleidbare gegevens
Als u tijdens query’s herhaaldelijk een berekening moet uitvoeren, kunt u de resultaten daarvan het beste opslaan. Als de berekening detailrecords bevat, moet u de afgeleide berekening in de hoofdtabel opslaan. Wanneer u besluit afgeleide waarden op te slaan, zorg er dan voor dat gedenormaliseerde waarden altijd door het systeem worden herberekend.
Hieronder staan situaties waarin het opslaan van afgeleide waarden op zijn plaats is:
- Wanneer u vaak afgeleide waarden nodig hebt
- Wanneer u niet vaak bronwaarden wijzigt
| Voordelen | Voordelen |
|---|---|
| Het is niet nodig bronwaarden op te zoeken telkens wanneer een afleidbare waarde nodig is | Het uitvoeren van gegevensmanipulatietaal (DML) verklaringen tegen de brongegevens vereist herberekening van de afleidbare gegevens |
| Het is niet nodig voor elke query of elk rapport een berekening uit te voeren | Inconsistenties in gegevens zijn mogelijk als gevolg van duplicatie van gegevens |
Exemplaar

Als voorbeeld van deze denormalisatie techniek, stel dat we een e-mailberichtenservice bouwen. Nadat een gebruiker een bericht heeft ontvangen, krijgt hij alleen een pointer naar dit bericht; de pointer wordt opgeslagen in de tabel User_messages. Dit wordt gedaan om te voorkomen dat het berichtensysteem meerdere kopieën van een e-mailbericht opslaat voor het geval het naar veel verschillende ontvangers tegelijk wordt verzonden. Maar wat als een gebruiker een bericht verwijdert van zijn account? In dat geval wordt alleen het betreffende bericht in de tabel User_messages verwijderd. Dus om het bericht volledig te verwijderen, moeten alle User_messages records voor het bericht worden verwijderd.
Denormalisatie van gegevens in een van de tabellen kan dit veel eenvoudiger maken: we kunnen een users_received_count toevoegen aan de tabel Messages om een record bij te houden van User_messages die voor een specifiek bericht zijn bijgehouden. Wanneer een gebruiker dit bericht verwijdert (lees: de pointer naar het eigenlijke bericht verwijdert), wordt de kolom users_received_count met één verminderd. Natuurlijk, wanneer de users_received_count gelijk is aan nul, kan het eigenlijke bericht volledig worden verwijderd.
Het gebruik van pre-joined tabellen
Om tabellen te pre-joinen, moet je een niet-sleutel kolom toevoegen aan een tabel die geen zakelijke waarde heeft. Op die manier kunt u het joinen van tabellen vermijden en daardoor query’s versnellen. Wel moet u ervoor zorgen dat de gedenormaliseerde kolom wordt bijgewerkt telkens wanneer de waarde van de masterkolom wordt gewijzigd.
Deze denormalisatie-techniek kan worden gebruikt wanneer u veel query’s tegen veel verschillende tabellen moet uitvoeren – en zolang oudbakken gegevens acceptabel zijn.
| Voordelen | Nadelen |
|---|---|
| Het is niet nodig om meerdere joins te gebruiken | DML is nodig om de nietgedenormaliseerde kolom |
| U kunt updates uitstellen zolang stale gegevens toelaatbaar zijn | Een extra kolom vereist extra werk- en schijfruimte |
Exemplaar

Stel je voor dat gebruikers van onze e-mailberichtenservice toegang willen tot berichten per categorie. Door de naam van een categorie direct in de tabel User_messages op te slaan, kan tijd worden bespaard en het aantal noodzakelijke joins worden verminderd.
In de gedenormaliseerde tabel hierboven hebben we de kolom category_name geïntroduceerd om informatie op te slaan over welke categorie elk record in de tabel User_messages betreft. Dankzij de denormalisatie is alleen een query op de tabel User_messages nodig om een gebruiker in staat te stellen alle berichten te selecteren die tot een bepaalde categorie behoren. Natuurlijk heeft deze denormalisatie techniek een nadeel – deze extra kolom kan veel opslagruimte in beslag nemen.
Gebruik van hardcoded waarden
Als er een referentietabel is met constante records, kun je deze hardcoderen in je applicatie. Op die manier hoeft u geen tabellen samen te voegen om de referentiewaarden op te halen.
Wanneer u echter hardcoded waarden gebruikt, moet u een controleconstraint maken om de waarden te valideren ten opzichte van de referentiewaarden. Deze constraint moet telkens worden herschreven als een nieuwe waarde in de A-tabel nodig is.
Deze data denormalisatie techniek moet worden gebruikt als waarden statisch zijn gedurende de levenscyclus van je systeem en zolang het aantal van deze waarden vrij klein is. Laten we nu eens kijken naar de voor- en nadelen van deze techniek:
| Voordelen | |
|---|---|
| Het is niet nodig om een opzoektabel te implementeren | Hercodering en herformulering zijn nodig als de opzoek-waarden worden gewijzigd |
| Geen joins naar een opzoektabel |
Exemplaar

Stel dat we achtergrondinformatie moeten achterhalen over gebruikers van een e-mailberichtendienst, bijvoorbeeld het soort, of type, gebruiker. We hebben een tabel User_kinds gemaakt om gegevens op te slaan over de soorten gebruikers die we willen herkennen.
De waarden in deze tabel zullen waarschijnlijk niet vaak worden gewijzigd, dus we kunnen hardcoding toepassen. We kunnen een controlebeperking aan de kolom toevoegen of de controlebeperking inbouwen in de veldvalidatie voor de toepassing waarin gebruikers zich aanmelden bij onze e-mailberichtenservice.
Details bij de master bewaren
Er kunnen zich gevallen voordoen waarin het aantal detailrecords per master vastligt of waarin detailrecords met de master worden opgevraagd. In deze gevallen kun je een database denormaliseren door detail-kolommen aan de master-tabel toe te voegen. Deze techniek is het handigst als er weinig records in de detailtabel staan.
| Voordelen | Nadelen |
|---|---|
| Het is niet nodig joins te gebruiken | Verhoogde complexiteit van DML |
| Bespaart ruimte |
Exemplaar

Stel je voor dat we de maximale hoeveelheid opslagruimte die een gebruiker kan krijgen moeten beperken. Om dit te doen, moeten we beperkingen invoeren in onze e-mailberichtenservice – een voor berichten en een voor bestanden. Aangezien de hoeveelheid toegestane opslagruimte voor elk van deze beperkingen verschillend is, moeten wij elke beperking afzonderlijk bijhouden. In een genormaliseerde relationele database zouden we gewoon twee verschillende tabellen kunnen invoeren – Storage_types en Storage_restraints – die records voor elke gebruiker zouden opslaan.
In plaats daarvan kunnen we een andere weg inslaan en gedenormaliseerde kolommen toevoegen aan de tabel Gebruikers:
message_space_allocated
message_space_available
file_space_allocated
file_space_available
In dit geval slaat de gedenormaliseerde Users-tabel niet alleen de feitelijke informatie over een gebruiker op, maar ook de restricties, dus qua functionaliteit komt de tabel niet volledig overeen met zijn naam.
Het herhalen van een enkel detail met zijn master
Wanneer je met historische gegevens werkt, hebben veel queries een specifiek enkel record nodig en zelden andere details. Met deze database denormalisatie techniek, kun je een nieuwe foreign key kolom introduceren om dit record met zijn master op te slaan. Vergeet bij dit soort denormalisatie niet om code toe te voegen die de gedenormaliseerde kolom bijwerkt wanneer een nieuw record wordt toegevoegd.
| Voordelen | Nadelen |
|---|---|
| Het is niet nodig om joins te maken voor queries die één record nodig hebben | Inconsistenties in gegevens zijn mogelijk omdat de waarde van een record moet worden herhaald |
Exemplaar
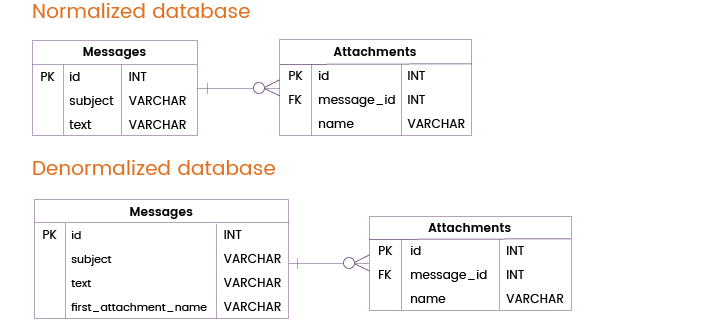
Vaak, sturen gebruikers niet alleen berichten, maar ook bijlagen. De meeste berichten worden zonder bijlage of met één bijlage verzonden, maar in sommige gevallen voegen gebruikers meerdere bestanden aan een bericht toe.
We kunnen een tabel join vermijden door de Berichten-tabel te denormaliseren door de kolom first_attachment_name toe te voegen. Als een bericht meer dan één bijlage bevat, wordt uiteraard alleen de eerste bijlage uit de Berichtentabel gehaald, terwijl de andere bijlagen in een aparte Bijlagen-tabel worden opgeslagen en dus moeten worden samengevoegd. In de meeste gevallen zal deze denormalisatietechniek echter echt nuttig zijn.
Kortsluitingstoetsen
Als een database meer dan drie niveaus van stamgegevens heeft en u alleen records van het laagste en hoogste niveau moet bevragen, kunt u uw database denormaliseren door kortsluitingstoetsen te maken die de kleinkindrecords van het laagste niveau verbinden met de grootouderrecords van het hogere niveau. Met deze techniek kunt u het aantal tabeljoins verminderen wanneer query’s worden uitgevoerd.
| Voordelen | |
|---|---|
| Er worden minder tabellen samengevoegd tijdens query’s | Er moeten meer foreign keys worden gebruikt |
| Extra code nodig om consistentie van waarden te waarborgen |
Exemplaar
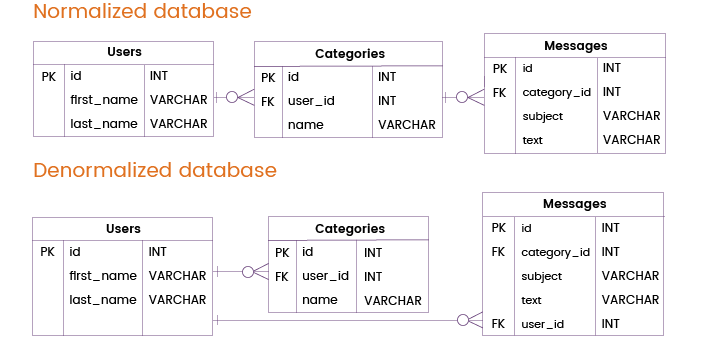
Stellen we ons nu eens voor dat een e-mailberichtendienst frequente query’s moet verwerken waarvoor alleen gegevens uit de tabellen Gebruikers en Berichten nodig zijn, zonder de tabel Categorieën aan te spreken. In een genormaliseerde database zouden dergelijke query’s de tabellen Gebruikers en Categorieën moeten samenvoegen.
Om de databaseprestaties te verbeteren en dergelijke samenvoegingen te vermijden, kunnen we een primaire of unieke sleutel uit de tabel Gebruikers rechtstreeks aan de tabel Berichten toevoegen. Op die manier kunnen we informatie over gebruikers en berichten verschaffen zonder de tabel Categorieën te hoeven raadplegen, zodat we geen overbodige join hoeven te maken.
Tegenvallers van database denormalisatie
Nu vraagt u zich waarschijnlijk af: to denormalize or not to denormalize?
Hoewel denormalisatie de beste manier lijkt om de prestaties van een database en dus van een applicatie in het algemeen te verbeteren, moet u er alleen uw toevlucht toe nemen als andere methoden inefficiënt blijken. Zo kan onvoldoende databaseprestatie vaak worden veroorzaakt door verkeerd geschreven query’s, gebrekkige applicatiecode, inconsistent indexontwerp of zelfs onjuiste hardwareconfiguratie.
Denormalisatie klinkt verleidelijk en in theorie uiterst efficiënt, maar er kleven een aantal nadelen aan, waarvan u zich bewust moet zijn voordat u met deze strategie in zee gaat:
- Extra opslagruimte
Wanneer u een database denormaliseert, moet u veel gegevens dupliceren. Vanzelfsprekend heeft uw database meer opslagruimte nodig.
- Extra documentatie
Elke stap die u tijdens het denormaliseren neemt, moet goed worden gedocumenteerd. Als u later het ontwerp van uw database wijzigt, moet u alle regels die u eerder hebt gemaakt, herzien: misschien hebt u sommige regels niet nodig of moet u bepaalde denormalisatieregels upgraden.
- Potentiële gegevensanomalieën
Bij het denormaliseren van een database moet u begrijpen dat u meer gegevens krijgt die kunnen worden gewijzigd. Daarom moet u elk geval van dubbele gegevens aanpakken. U moet triggers, stored procedures en transacties gebruiken om anomalieën in de gegevens te voorkomen.
- Meer code
Wanneer u een database denormaliseert, wijzigt u select queries, en hoewel dit veel voordelen biedt, heeft het ook zijn prijs – u moet extra code schrijven. U moet ook waarden bijwerken in nieuwe attributen die u aan bestaande records toevoegt, wat betekent dat er nog meer code nodig is.
- Langzamere bewerkingen
Database denormalisatie kan het ophalen van gegevens versnellen, maar tegelijkertijd vertraagt het updates. Als uw applicatie veel schrijfbewerkingen naar de database moet uitvoeren, kan de performance langzamer zijn dan bij een vergelijkbare genormaliseerde database. Zorg er dus voor dat u denormalisatie implementeert zonder de bruikbaarheid van uw applicatie te schaden.
Database denormalisatie tips
Zoals u ziet, is denormalisatie een serieus proces dat veel inspanning en vaardigheid vereist. Als u databases probleemloos wilt denormaliseren, volg dan deze nuttige tips:
- Probeer niet meteen de hele database te denormaliseren, maar richt u op bepaalde delen die u wilt versnellen.
- Doe uw best om het logische ontwerp van uw toepassing echt goed te leren om te begrijpen welke delen van uw systeem waarschijnlijk worden beïnvloed door denormalisatie.
- Analyseer hoe vaak gegevens worden gewijzigd in uw toepassing; als gegevens te vaak veranderen, kan het handhaven van de integriteit van uw database na denormalisatie een echt probleem worden.
- Bekijk goed welke delen van uw toepassing prestatieproblemen hebben; vaak kunt u uw toepassing versnellen door query’s te verfijnen in plaats van de database te denormaliseren.
- Leer meer over technieken voor gegevensopslag; het kiezen van de meest relevante kan u helpen zonder denormalisatie.
Eindgedachten
U moet altijd beginnen met het bouwen van een schone en goed presterende genormaliseerde database. Alleen als je database beter moet presteren bij bepaalde taken (zoals rapportage) moet je kiezen voor denormalisatie. Als u toch denormaliseert, wees dan voorzichtig en documenteer alle wijzigingen die u in de database aanbrengt.
Voordat u overgaat tot denormalisatie, moet u zich de volgende vragen stellen:
- Kan mijn systeem voldoende prestaties leveren zonder denormalisatie?
- Wordt de performance van mijn database onacceptabel als ik hem denormaliseer?
- Wordt mijn systeem minder betrouwbaar?
Als het antwoord op een van deze vragen ja is, dan kunt u beter afzien van denormalisatie, omdat het waarschijnlijk inefficiënt zal blijken voor uw toepassing. Als denormalisatie echter uw enige optie is, moet u eerst de database correct normaliseren en vervolgens overgaan tot denormalisatie, waarbij u zorgvuldig en strikt de technieken volgt die we in dit artikel hebben beschreven.
Voor meer inzichten in de laatste trends op het gebied van softwareontwikkeling, kunt u zich abonneren op onze blog.