Dit bericht behandelt de basis van Apache Parquet, dat een belangrijke bouwsteen is in big data architectuur. Om meer te leren over het beheren van bestanden op object storage, bekijk onze gids over Partitioning Data on Amazon S3.
In de Amazon re:Invent conferentie van vorig jaar (toen echte conferenties nog een ding waren), kondigde AWS data lake export aan – de mogelijkheid om het resultaat van een Redshift query te lossen naar Amazon S3 in Apache Parquet formaat. In de aankondiging beschreef AWS Parquet als “2x sneller te ontladen en verbruikt tot 6x minder opslag in Amazon S3, vergeleken met tekstformaten”. Het converteren van data naar kolom-formaten zoals Parquet of ORC wordt ook aanbevolen als middel om de prestaties van Amazon Athena te verbeteren.
Het is duidelijk dat Apache Parquet een belangrijke rol speelt in de systeemprestaties bij het werken met data lakes. Laten we eens nader bekijken wat Parquet eigenlijk is, en waarom het belangrijk is voor big data-opslag en -analyse.
De grondbeginselen: Wat is Apache Parquet?
Apache Parquet is een bestandsindeling die is ontworpen om snelle gegevensverwerking voor complexe gegevens te ondersteunen, met een aantal opmerkelijke kenmerken:
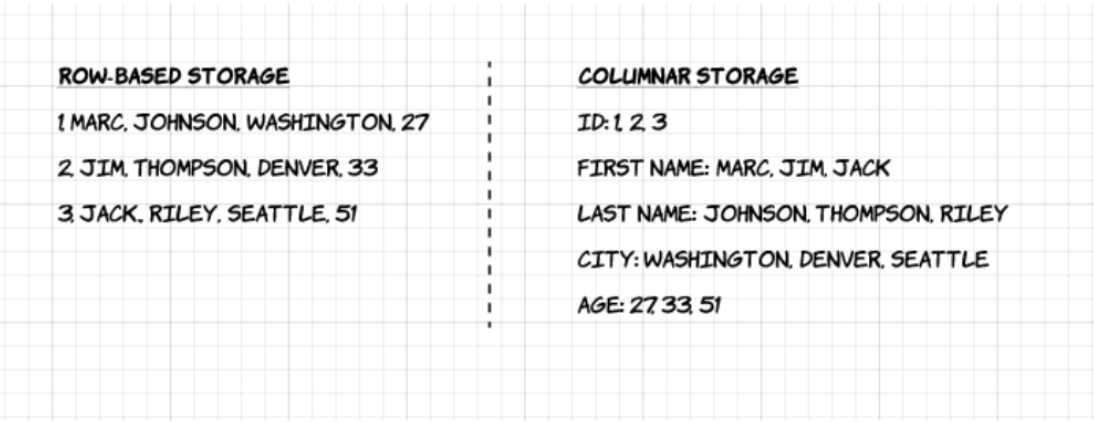
1. Kolomvormig: In tegenstelling tot rijgebaseerde indelingen zoals CSV of Avro, is Apache Parquet kolomgeoriënteerd – wat betekent dat de waarden van elke tabelkolom naast elkaar worden opgeslagen, in plaats van die van elk record:
2. Open-source: Parquet is vrij te gebruiken en open source onder de Apache Hadoop-licentie, en is compatibel met de meeste Hadoop-raamwerken voor gegevensverwerking.
3. Zelfbeschrijvend: In Parquet is metadata inclusief schema en structuur ingebed in elk bestand, waardoor het een zelfbeschrijvend bestandsformaat is.
Voordelen van Parquet Columnar Storage
De bovenstaande kenmerken van het Apache Parquet-bestandsformaat creëren verschillende duidelijke voordelen als het gaat om het opslaan en analyseren van grote hoeveelheden data. Laten we er eens een paar nader bekijken.
Compressie
Bestandcompressie is het verkleinen van een bestand. In Parquet wordt compressie kolom voor kolom uitgevoerd en het is zo gebouwd dat het flexibele compressieopties en uitbreidbare coderingsschema’s per gegevenstype ondersteunt – er kunnen bijvoorbeeld verschillende coderingen worden gebruikt voor het comprimeren van integer- en stringgegevens.
Parquet-gegevens kunnen worden gecomprimeerd met behulp van deze coderingsmethoden:
- Woordenboekcodering: deze wordt automatisch en dynamisch ingeschakeld voor gegevens met een klein aantal unieke waarden.
- Bitverpakking: Gehele getallen worden meestal opgeslagen met 32 of 64 bits per geheel getal. Hierdoor kunnen kleine gehele getallen efficiënter worden opgeslagen.
- Run length encoding (RLE): wanneer dezelfde waarde meerdere keren voorkomt, wordt één enkele waarde eenmaal opgeslagen, samen met het aantal keren dat deze voorkomt. Parquet implementeert een gecombineerde versie van bit packing en RLE, waarbij de codering wordt gebaseerd op de beste compressieresultaten.

Prestaties
In tegenstelling tot op rijen gebaseerde bestandsindelingen zoals CSV, is Parquet geoptimaliseerd voor prestaties. Wanneer u query’s uitvoert op uw op Parquet gebaseerde bestandssysteem, kunt u zich zeer snel alleen richten op de relevante gegevens. Bovendien zal de hoeveelheid gescande gegevens veel kleiner zijn en resulteren in minder I/O-gebruik. Om dit te begrijpen, gaan we wat dieper in op hoe Parquet-bestanden zijn gestructureerd.
Zoals we hierboven al zeiden, is Parquet een zelfbeschreven formaat, dus elk bestand bevat zowel data als metadata. Parquet-bestanden zijn opgebouwd uit rij-groepen, header en footer. Elke rijgroep bevat gegevens van dezelfde kolommen. Dezelfde kolommen worden samen in elke rijgroep opgeslagen:
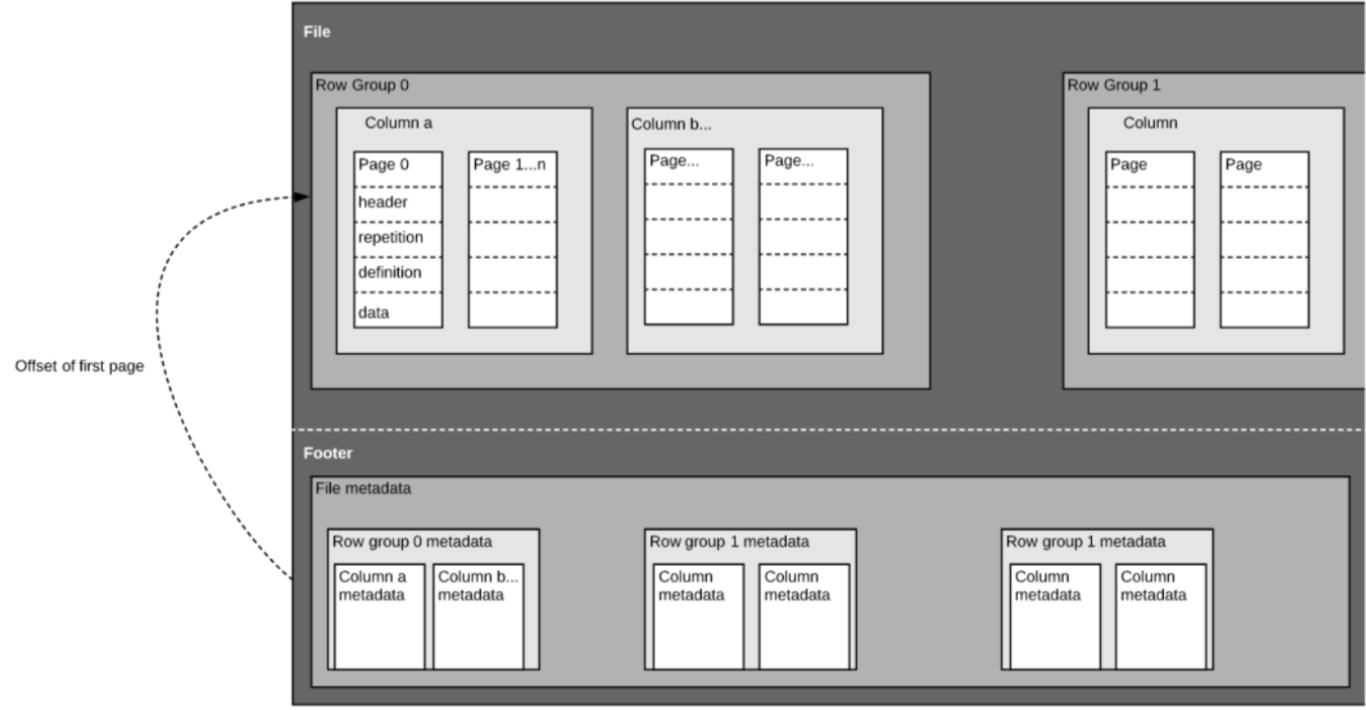
Deze structuur is goed geoptimaliseerd voor zowel snelle queryprestaties, als lage I/O (het minimaliseren van de hoeveelheid gescande gegevens). Als u bijvoorbeeld een tabel met 1000 kolommen hebt, die u meestal slechts met een kleine subset van kolommen zult bevragen. Met Parquet-bestanden kunt u alleen de vereiste kolommen en hun waarden ophalen, die in het geheugen laden en de query beantwoorden. Als een rij-gebaseerd bestandsformaat zoals CSV zou worden gebruikt, zou de hele tabel in het geheugen moeten worden geladen, met als gevolg meer I/O en slechtere prestaties.
Schema-evolutie
Bij gebruik van kolom-gebaseerde bestandsformaten zoals Parquet, kunnen gebruikers beginnen met een eenvoudig schema, en geleidelijk meer kolommen aan het schema toevoegen als dat nodig is. Op deze manier kunnen gebruikers eindigen met meerdere Parquet-bestanden met verschillende, maar onderling compatibele schema’s. In deze gevallen ondersteunt Parquet automatische schema-samenvoeging tussen deze bestanden.
Open-source ondersteuning
Apache Parquet maakt, zoals gezegd, deel uit van het Apache Hadoop ecosysteem dat open-source is en voortdurend wordt verbeterd en gesteund door een sterke gemeenschap van gebruikers en ontwikkelaars. Door uw gegevens in open formaten op te slaan, vermijdt u vendor lock-in en verhoogt u uw flexibiliteit, in vergelijking met propriëtaire bestandsformaten die door veel moderne high-performance databases worden gebruikt. Dit betekent dat u verschillende query-engines kunt gebruiken, zoals Amazon Athena, Qubole en Amazon Redshift Spectrum, binnen dezelfde data lake-architectuur.
Column-oriented vs row based storage for analytic querying
Data wordt vaak gegenereerd en eenvoudiger geconceptualiseerd in rijen. We zijn gewend te denken in termen van Excel-spreadsheets, waarin we alle gegevens die relevant zijn voor een specifiek record in één nette en georganiseerde rij kunnen zien. Voor grootschalige analytische query’s biedt kolom-opslag echter aanzienlijke voordelen met betrekking tot kosten en prestaties.
Complexe gegevens zoals logs en event streams zouden moeten worden gerepresenteerd als een tabel met honderden of duizenden kolommen, en vele miljoenen rijen. Het opslaan van deze tabel in een op rijen gebaseerd formaat zoals CSV zou betekenen:
- Het uitvoeren van query’s duurt langer omdat er meer gegevens moeten worden gescand, in plaats van alleen de subset van kolommen te bevragen die we nodig hebben om een query te beantwoorden (waarvoor meestal aggregatie op basis van dimensie of categorie nodig is)
- Opslag is duurder omdat CSV’s niet zo efficiënt worden gecomprimeerd als Parquet
Kolom-formaten bieden betere compressie en betere prestaties out-of-the-box, en stellen je in staat om gegevens verticaal te bevragen – kolom voor kolom.
Voorbeeld: Parquet, CSV en Amazon Athena
We gaan veel dieper op dit voorbeeld in tijdens ons komende webinar met Looker.
Om de impact van kolom-gebaseerde Parquet opslag ten opzichte van rij-gebaseerde alternatieven te demonstreren, laten we eens kijken naar wat er gebeurt als je Amazon Athena gebruikt om data opgeslagen op Amazon S3 in beide gevallen te bevragen.
Met Upsolver hebben we een CSV dataset van server logs opgenomen in S3. In een gebruikelijke AWS data lake architectuur, zou Athena worden gebruikt om de data direct vanuit S3 te queryen. Deze query’s kunnen vervolgens worden gevisualiseerd met interactieve datavisualisatietools zoals Tableau of Looker.
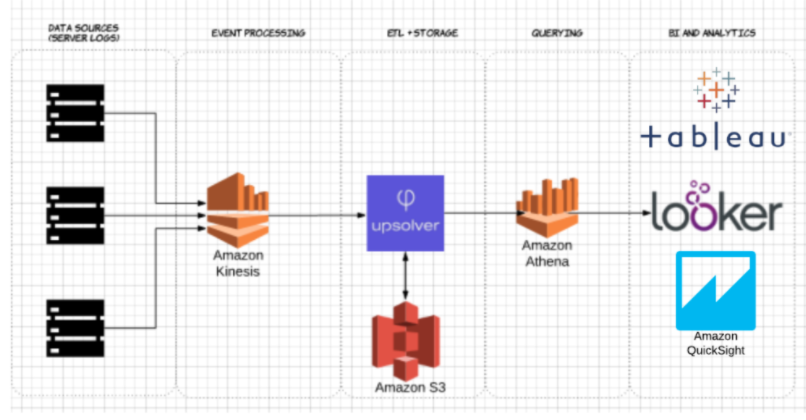
We hebben Athena getest tegen dezelfde dataset die is opgeslagen als gecomprimeerde CSV, en als Apache Parquet.
Dit is de query die we in Athena hebben uitgevoerd:
SELECT tags_host AS host_id, AVG(fields_usage_active) as avg_usage
FROM server_usage
GROUP BY tags_host
HAVING AVG(fields_usage_active) > 0
LIMIT 10
En de resultaten:
| CSV | Parquet | Columns | |
| 735 | 211 | 18 | |
| Gescande gegevens (GB) | 372.2 | 10.29 | 18 |
- Gecomprimeerde CSV’s: De gecomprimeerde CSV heeft 18 kolommen en weegt 27 GB op S3. Athena moet het hele CSV-bestand scannen om de query te beantwoorden, dus we zouden betalen voor 27 GB aan gescande gegevens. Bij hogere schalen zou dit ook de prestaties negatief beïnvloeden.
- Parquet: Als we onze gecomprimeerde CSV-bestanden converteren naar Apache Parquet, eindig je met een vergelijkbare hoeveelheid gegevens in S3. Echter, omdat Parquet columnar is, moet Athena alleen de kolommen lezen die relevant zijn voor de query die wordt uitgevoerd – een kleine subset van de gegevens. In dit geval moest Athena 0,22 GB aan data scannen, dus in plaats van te betalen voor 27 GB aan gescande data betalen we slechts voor 0,22 GB.
Is het gebruik van Parquet genoeg?
Het gebruik van Parquet is een goed begin; het optimaliseren van data lake-query’s houdt daar echter niet op. Vaak moet u de data opschonen, verrijken en transformeren, high-cardinality joins uitvoeren en een groot aantal best practices implementeren om ervoor te zorgen dat query’s consistent, snel en kosteneffectief worden beantwoord.
U kunt Upsolver gebruiken om uw data lake ETL-pijplijn te vereenvoudigen, data automatisch op te nemen als geoptimaliseerd Parquet en streaming data te transformeren met SQL- of Excel-achtige functies. Voor meer informatie kunt u hier een demo aanvragen.
Wilt u meer weten over het optimaliseren van uw data lake? Bekijk een aantal van deze best practices voor het datameer. Om meer benchmarks te zien en best practices te leren voor het voorbereiden van gegevens voor Athena, kunt u hier deelnemen aan het Upsolver + Looker webinar.